 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNBMOD: Find It and Grasp It in Noisy Background
Jun 17, 2023

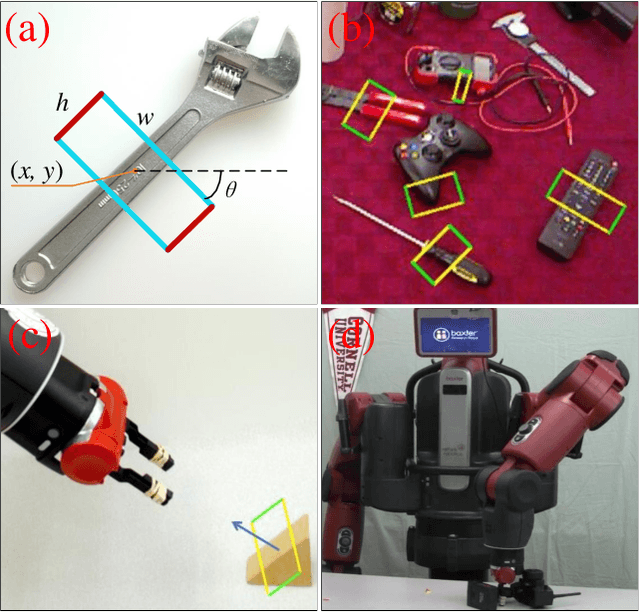

Grasping objects is a fundamental yet important capability of robots, and many tasks such as sorting and picking rely on this skill. The prerequisite for stable grasping is the ability to correctly identify suitable grasping positions. However, finding appropriate grasping points is challenging due to the diverse shapes, varying density distributions, and significant differences between the barycenter of various objects. In the past few years, researchers have proposed many methods to address the above-mentioned issues and achieved very good results on publicly available datasets such as the Cornell dataset and the Jacquard dataset. The problem is that the backgrounds of Cornell and Jacquard datasets are relatively simple - typically just a whiteboard, while in real-world operational environments, the background could be complex and noisy. Moreover, in real-world scenarios, robots usually only need to grasp fixed types of objects. To address the aforementioned issues, we proposed a large-scale grasp detection dataset called NBMOD: Noisy Background Multi-Object Dataset for grasp detection, which consists of 31,500 RGB-D images of 20 different types of fruits. Accurate prediction of angles has always been a challenging problem in the detection task of oriented bounding boxes. This paper presents a Rotation Anchor Mechanism (RAM) to address this issue. Considering the high real-time requirement of robotic systems, we propose a series of lightweight architectures called RA-GraspNet (GraspNet with Rotation Anchor): RARA (network with Rotation Anchor and Region Attention), RAST (network with Rotation Anchor and Semi Transformer), and RAGT (network with Rotation Anchor and Global Transformer) to tackle this problem. Among them, the RAGT-3/3 model achieves an accuracy of 99% on the NBMOD dataset. The NBMOD and our code are available at https://github.com/kmittle/Grasp-Detection-NBMOD.
Enhance-NeRF: Multiple Performance Evaluation for Neural Radiance Fields
Jun 08, 2023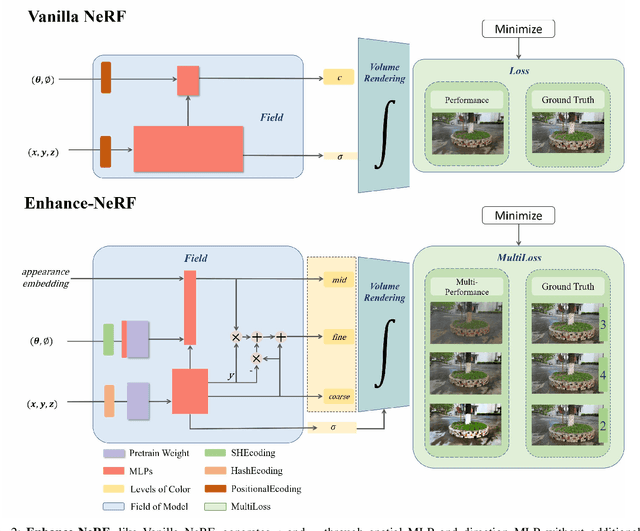



The quality of three-dimensional reconstruction is a key factor affecting the effectiveness of its application in areas such as virtual reality (VR) and augmented reality (AR) technologies. Neural Radiance Fields (NeRF) can generate realistic images from any viewpoint. It simultaneously reconstructs the shape, lighting, and materials of objects, and without surface defects, which breaks down the barrier between virtuality and reality. The potential spatial correspondences displayed by NeRF between reconstructed scenes and real-world scenes offer a wide range of practical applications possibilities. Despite significant progress in 3D reconstruction since NeRF were introduced, there remains considerable room for exploration and experimentation. NeRF-based models are susceptible to interference issues caused by colored "fog" noise. Additionally, they frequently encounter instabilities and failures while attempting to reconstruct unbounded scenes. Moreover, the model takes a significant amount of time to converge, making it even more challenging to use in such scenarios. Our approach, coined Enhance-NeRF, which adopts joint color to balance low and high reflectivity objects display, utilizes a decoding architecture with prior knowledge to improve recognition, and employs multi-layer performance evaluation mechanisms to enhance learning capacity. It achieves reconstruction of outdoor scenes within one hour under single-card condition. Based on experimental results, Enhance-NeRF partially enhances fitness capability and provides some support to outdoor scene reconstruction. The Enhance-NeRF method can be used as a plug-and-play component, making it easy to integrate with other NeRF-based models. The code is available at: https://github.com/TANQIanQ/Enhance-NeRF