 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition
Paper and Code
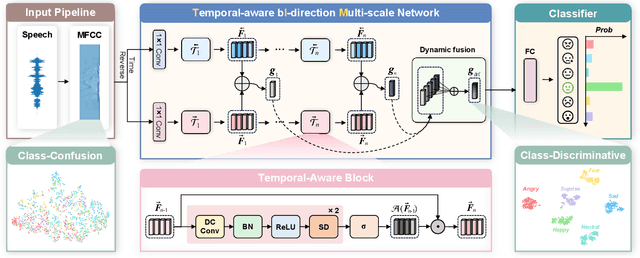
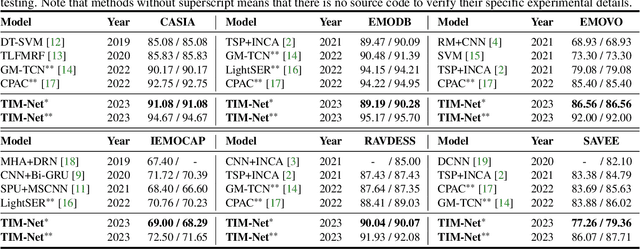
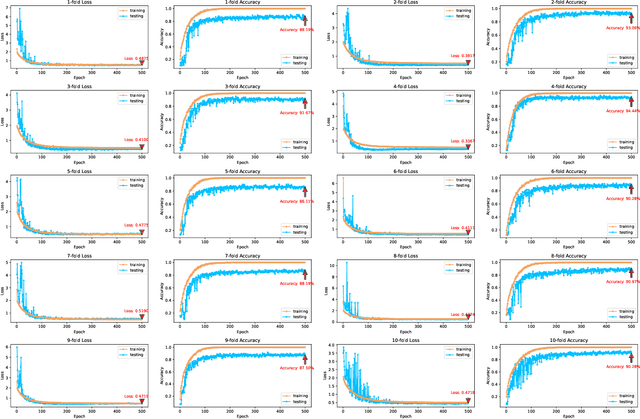

Speech emotion recognition (SER) plays a vital role in improving the interactions between humans and machines by inferring human emotion and affective states from speech signals. Whereas recent works primarily focus on mining spatiotemporal information from hand-crafted features, we explore how to model the temporal patterns of speech emotions from dynamic temporal scales. Towards that goal, we introduce a novel temporal emotional modeling approach for SER, termed Temporal-aware bI-direction Multi-scale Network (TIM-Net), which learns multi-scale contextual affective representations from various time scales. Specifically, TIM-Net first employs temporal-aware blocks to learn temporal affective representation, then integrates complementary information from the past and the future to enrich contextual representations, and finally, fuses multiple time scale features for better adaptation to the emotional variation. Extensive experimental results on six benchmark SER datasets demonstrate the superior performance of TIM-Net, gaining 2.34% and 2.61% improvements of the average UAR and WAR over the second-best on each corpus. Remarkably, TIM-Net outperforms the latest domain-adaptation method on the cross-corpus SER tasks, demonstrating strong generalizability.