 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSonate: A Unified Model for Speech, Music, and Sound Effect Generation with Text Instructions
Apr 24, 2026Generative audio modeling has largely been fragmented into specialized tasks, text-to-speech (TTS), text-to-music (TTM), and text-to-audio (TTA), each operating under heterogeneous control paradigms. Unifying these modalities remains a fundamental challenge due to the intrinsic dissonance between structured semantic representations (speech/music) and unstructured acoustic textures (sound effects). In this paper, we introduce UniSonate, a unified flow-matching framework capable of synthesizing speech, music, and sound effects through a standardized, reference-free natural language instruction interface. To reconcile structural disparities, we propose a novel dynamic token injection mechanism that projects unstructured environmental sounds into a structured temporal latent space, enabling precise duration control within a phoneme-driven Multimodal Diffusion Transformer (MM-DiT). Coupled with a multi-stage curriculum learning strategy, this approach effectively mitigates cross-modal optimization conflicts. Extensive experiments demonstrate that UniSonate achieves state-of-the-art performance in instruction-based TTS (WER 1.47%) and TTM (SongEval Coherence 3.18), while maintaining competitive fidelity in TTA. Crucially, we observe positive transfer, where joint training on diverse audio data significantly enhances structural coherence and prosodic expressiveness compared to single-task baselines. Audio samples are available at https://qiangchunyu.github.io/UniSonate/.
SoulX-Duplug: Plug-and-Play Streaming State Prediction Module for Realtime Full-Duplex Speech Conversation
Mar 16, 2026Recent advances in spoken dialogue systems have brought increased attention to human-like full-duplex voice interactions. However, our comprehensive review of this field reveals several challenges, including the difficulty in obtaining training data, catastrophic forgetting, and limited scalability. In this work, we propose SoulX-Duplug, a plug-and-play streaming state prediction module for full-duplex spoken dialogue systems. By jointly performing streaming ASR, SoulX-Duplug explicitly leverages textual information to identify user intent, effectively serving as a semantic VAD. To promote fair evaluation, we introduce SoulX-Duplug-Eval, extending widely used benchmarks with improved bilingual coverage. Experimental results show that SoulX-Duplug enables low-latency streaming dialogue state control, and the system built upon it outperforms existing full-duplex models in overall turn management and latency performance. We have open-sourced SoulX-Duplug and SoulX-Duplug-Eval.
V2A-DPO: Omni-Preference Optimization for Video-to-Audio Generation
Mar 11, 2026This paper introduces V2A-DPO, a novel Direct Preference Optimization (DPO) framework tailored for flow-based video-to-audio generation (V2A) models, incorporating key adaptations to effectively align generated audio with human preferences. Our approach incorporates three core innovations: (1) AudioScore-a comprehensive human preference-aligned scoring system for assessing semantic consistency, temporal alignment, and perceptual quality of synthesized audio; (2) an automated AudioScore-driven pipeline for generating large-scale preference pair data for DPO optimization; (3) a curriculum learning-empowered DPO optimization strategy specifically tailored for flow-based generative models. Experiments on benchmark VGGSound dataset demonstrate that human-preference aligned Frieren and MMAudio using V2A-DPO outperform their counterparts optimized using Denoising Diffusion Policy Optimization (DDPO) as well as pre-trained baselines. Furthermore, our DPO-optimized MMAudio achieves state-of-the-art performance across multiple metrics, surpassing published V2A models.
Habibi: Laying the Open-Source Foundation of Unified-Dialectal Arabic Speech Synthesis
Jan 20, 2026A notable gap persists in speech synthesis research and development for Arabic dialects, particularly from a unified modeling perspective. Despite its high practical value, the inherent linguistic complexity of Arabic dialects, further compounded by a lack of standardized data, benchmarks, and evaluation guidelines, steers researchers toward safer ground. To bridge this divide, we present Habibi, a suite of specialized and unified text-to-speech models that harnesses existing open-source ASR corpora to support a wide range of high- to low-resource Arabic dialects through linguistically-informed curriculum learning. Our approach outperforms the leading commercial service in generation quality, while maintaining extensibility through effective in-context learning, without requiring text diacritization. We are committed to open-sourcing the model, along with creating the first systematic benchmark for multi-dialect Arabic speech synthesis. Furthermore, by identifying the key challenges in and establishing evaluation standards for the process, we aim to provide a solid groundwork for subsequent research. Resources at https://SWivid.github.io/Habibi/ .
MeanAudio: Fast and Faithful Text-to-Audio Generation with Mean Flows
Aug 08, 2025Recent developments in diffusion- and flow- based models have significantly advanced Text-to-Audio Generation (TTA). While achieving great synthesis quality and controllability, current TTA systems still suffer from slow inference speed, which significantly limits their practical applicability. This paper presents MeanAudio, a novel MeanFlow-based model tailored for fast and faithful text-to-audio generation. Built on a Flux-style latent transformer, MeanAudio regresses the average velocity field during training, enabling fast generation by mapping directly from the start to the endpoint of the flow trajectory. By incorporating classifier-free guidance (CFG) into the training target, MeanAudio incurs no additional cost in the guided sampling process. To further stabilize training, we propose an instantaneous-to-mean curriculum with flow field mix-up, which encourages the model to first learn the foundational instantaneous dynamics, and then gradually adapt to mean flows. This strategy proves critical for enhancing training efficiency and generation quality. Experimental results demonstrate that MeanAudio achieves state-of-the-art performance in single-step audio generation. Specifically, it achieves a real time factor (RTF) of 0.013 on a single NVIDIA RTX 3090, yielding a 100x speedup over SOTA diffusion-based TTA systems. Moreover, MeanAudio also demonstrates strong performance in multi-step generation, enabling smooth and coherent transitions across successive synthesis steps.
Kling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio Generation
Jun 24, 2025
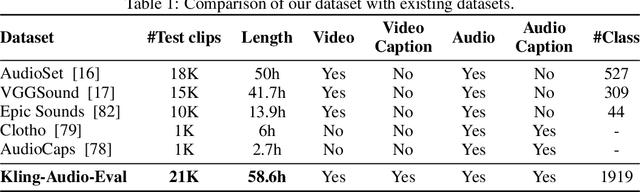
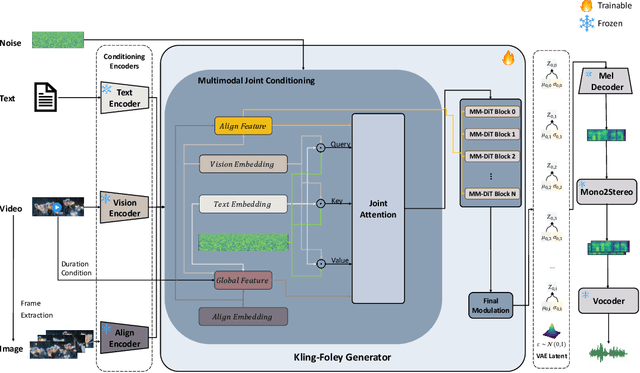
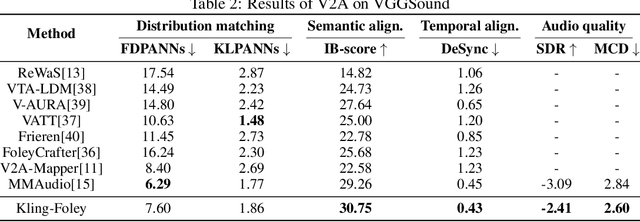
We propose Kling-Foley, a large-scale multimodal Video-to-Audio generation model that synthesizes high-quality audio synchronized with video content. In Kling-Foley, we introduce multimodal diffusion transformers to model the interactions between video, audio, and text modalities, and combine it with a visual semantic representation module and an audio-visual synchronization module to enhance alignment capabilities. Specifically, these modules align video conditions with latent audio elements at the frame level, thereby improving semantic alignment and audio-visual synchronization. Together with text conditions, this integrated approach enables precise generation of video-matching sound effects. In addition, we propose a universal latent audio codec that can achieve high-quality modeling in various scenarios such as sound effects, speech, singing, and music. We employ a stereo rendering method that imbues synthesized audio with a spatial presence. At the same time, in order to make up for the incomplete types and annotations of the open-source benchmark, we also open-source an industrial-level benchmark Kling-Audio-Eval. Our experiments show that Kling-Foley trained with the flow matching objective achieves new audio-visual SOTA performance among public models in terms of distribution matching, semantic alignment, temporal alignment and audio quality.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025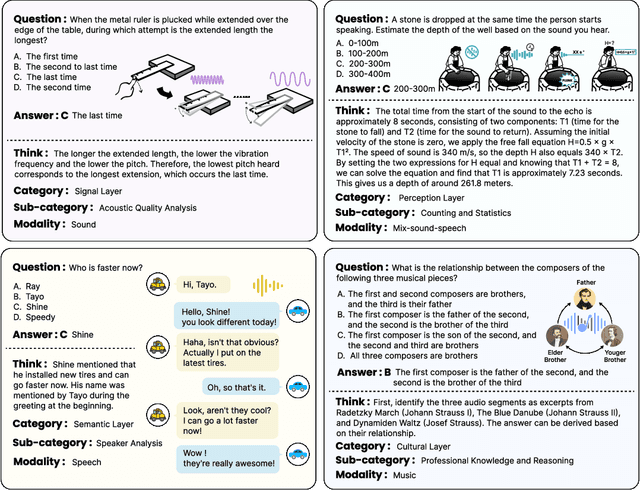

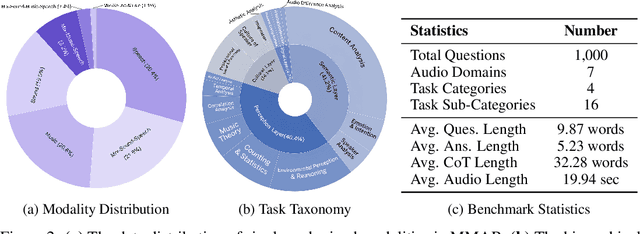
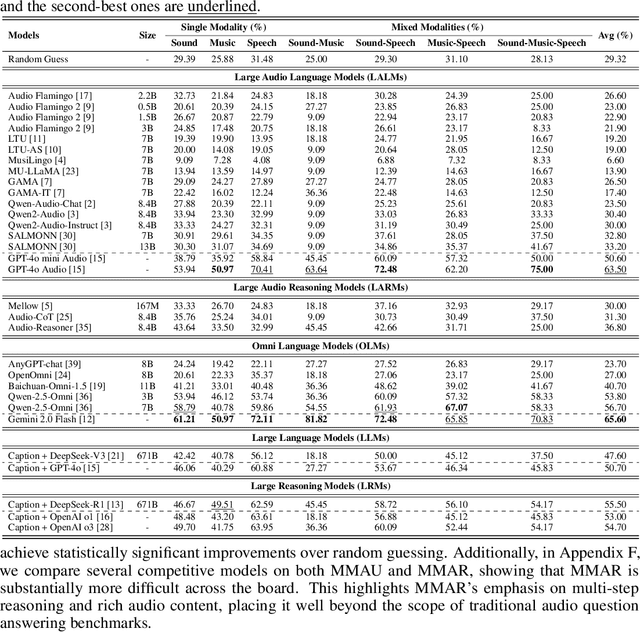
We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.
Towards Flow-Matching-based TTS without Classifier-Free Guidance
Apr 29, 2025Flow matching has demonstrated strong generative capabilities and has become a core component in modern Text-to-Speech (TTS) systems. To ensure high-quality speech synthesis, Classifier-Free Guidance (CFG) is widely used during the inference of flow-matching-based TTS models. However, CFG incurs substantial computational cost as it requires two forward passes, which hinders its applicability in real-time scenarios. In this paper, we explore removing CFG from flow-matching-based TTS models to improve inference efficiency, while maintaining performance. Specifically, we reformulated the flow matching training target to directly approximate the CFG optimization trajectory. This training method eliminates the need for unconditional model evaluation and guided tuning during inference, effectively cutting the computational overhead in half. Furthermore, It can be seamlessly integrated with existing optimized sampling strategies. We validate our approach using the F5-TTS model on the LibriTTS dataset. Experimental results show that our method achieves a 9$\times$ inference speed-up compared to the baseline F5-TTS, while preserving comparable speech quality. We will release the code and models to support reproducibility and foster further research in this area.
Interleaved Speech-Text Language Models are Simple Streaming Text to Speech Synthesizers
Dec 23, 2024This paper introduces Interleaved Speech-Text Language Model (IST-LM) for streaming zero-shot Text-to-Speech (TTS). Unlike many previous approaches, IST-LM is directly trained on interleaved sequences of text and speech tokens with a fixed ratio, eliminating the need for additional efforts in duration prediction and grapheme-to-phoneme alignment. The ratio of text chunk size to speech chunk size is crucial for the performance of IST-LM. To explore this, we conducted a comprehensive series of statistical analyses on the training data and performed correlation analysis with the final performance, uncovering several key factors: 1) the distance between speech tokens and their corresponding text tokens, 2) the number of future text tokens accessible to each speech token, and 3) the frequency of speech tokens precedes their corresponding text tokens. Experimental results demonstrate how to achieve an optimal streaming TTS system without complicated engineering optimization, which has a limited gap with the non-streaming system. IST-LM is conceptually simple and empirically powerful, paving the way for streaming TTS with minimal overhead while largely maintaining performance, showcasing broad prospects coupled with real-time text stream from LLMs.
SLAM-Omni: Timbre-Controllable Voice Interaction System with Single-Stage Training
Dec 20, 2024

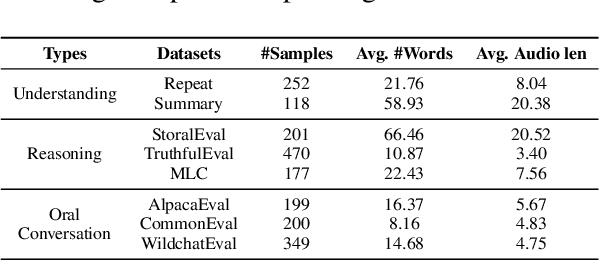
Recent advancements highlight the potential of end-to-end real-time spoken dialogue systems, showcasing their low latency and high quality. In this paper, we introduce SLAM-Omni, a timbre-controllable, end-to-end voice interaction system with single-stage training. SLAM-Omni achieves zero-shot timbre control by modeling spoken language with semantic tokens and decoupling speaker information to a vocoder. By predicting grouped speech semantic tokens at each step, our method significantly reduces the sequence length of audio tokens, accelerating both training and inference. Additionally, we propose historical text prompting to compress dialogue history, facilitating efficient multi-round interactions. Comprehensive evaluations reveal that SLAM-Omni outperforms prior models of similar scale, requiring only 15 hours of training on 4 GPUs with limited data. Notably, it is the first spoken dialogue system to achieve competitive performance with a single-stage training approach, eliminating the need for pre-training on TTS or ASR tasks. Further experiments validate its multilingual and multi-turn dialogue capabilities on larger datasets.