 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Parsing of Engineering Drawings for Structured Information Extraction Using a Fine-tuned Document Understanding Transformer
May 02, 2025

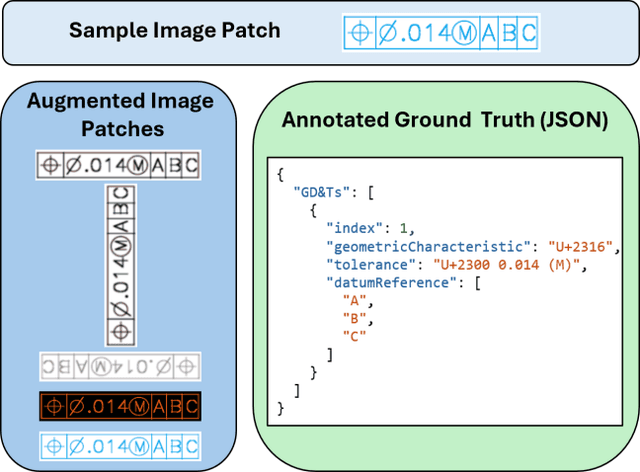
Accurate extraction of key information from 2D engineering drawings is crucial for high-precision manufacturing. Manual extraction is time-consuming and error-prone, while traditional Optical Character Recognition (OCR) techniques often struggle with complex layouts and overlapping symbols, resulting in unstructured outputs. To address these challenges, this paper proposes a novel hybrid deep learning framework for structured information extraction by integrating an oriented bounding box (OBB) detection model with a transformer-based document parsing model (Donut). An in-house annotated dataset is used to train YOLOv11 for detecting nine key categories: Geometric Dimensioning and Tolerancing (GD&T), General Tolerances, Measures, Materials, Notes, Radii, Surface Roughness, Threads, and Title Blocks. Detected OBBs are cropped into images and labeled to fine-tune Donut for structured JSON output. Fine-tuning strategies include a single model trained across all categories and category-specific models. Results show that the single model consistently outperforms category-specific ones across all evaluation metrics, achieving higher precision (94.77% for GD&T), recall (100% for most), and F1 score (97.3%), while reducing hallucination (5.23%). The proposed framework improves accuracy, reduces manual effort, and supports scalable deployment in precision-driven industries.
Fine-Tuning Vision-Language Model for Automated Engineering Drawing Information Extraction
Nov 06, 2024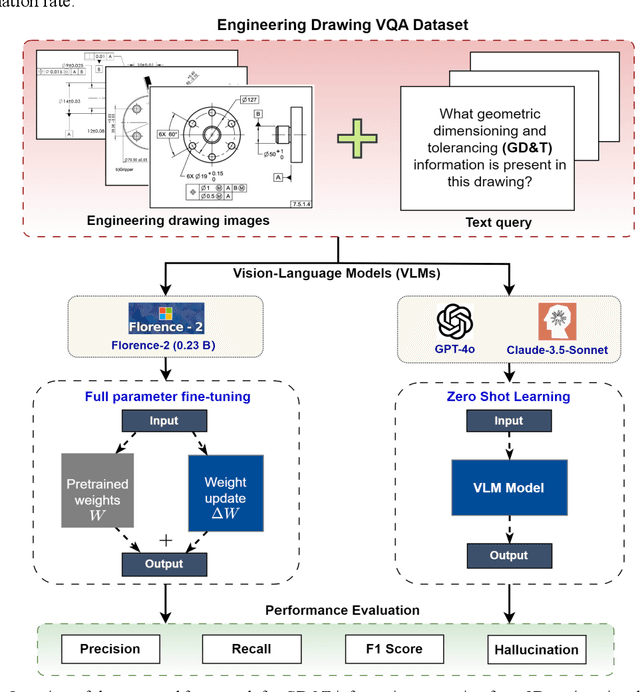
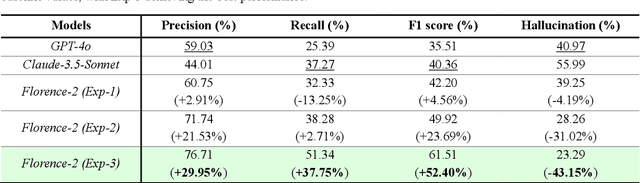
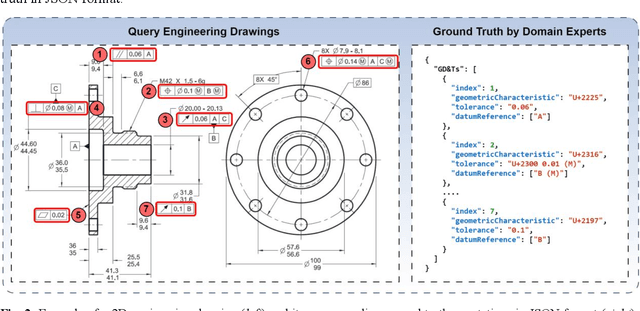
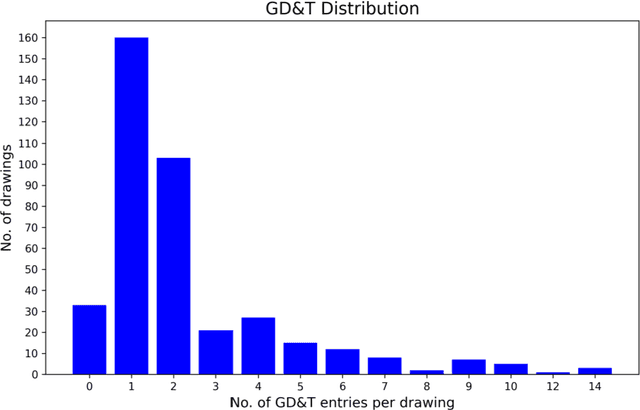
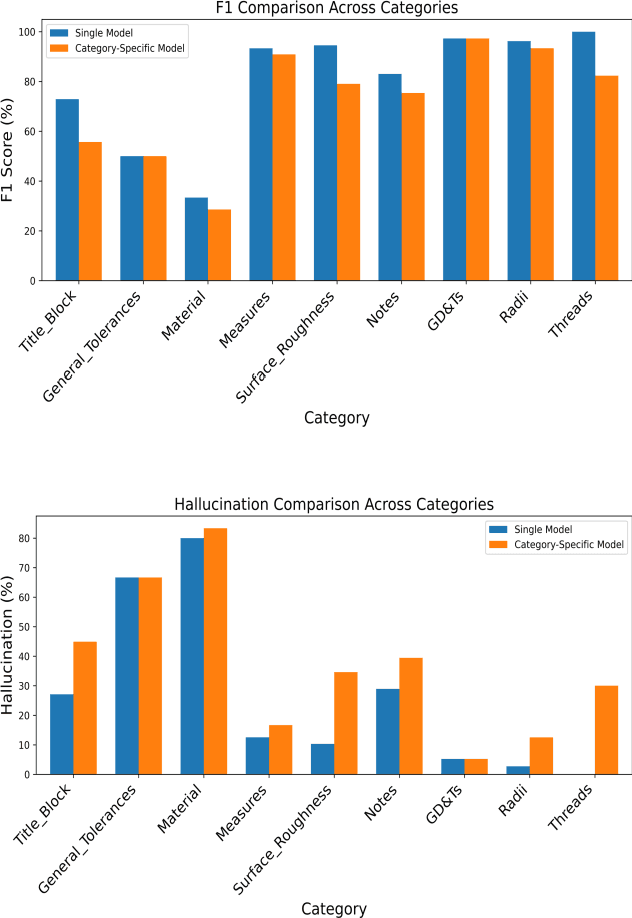
Geometric Dimensioning and Tolerancing (GD&T) plays a critical role in manufacturing by defining acceptable variations in part features to ensure component quality and functionality. However, extracting GD&T information from 2D engineering drawings is a time-consuming and labor-intensive task, often relying on manual efforts or semi-automated tools. To address these challenges, this study proposes an automated and computationally efficient GD&T extraction method by fine-tuning Florence-2, an open-source vision-language model (VLM). The model is trained on a dataset of 400 drawings with ground truth annotations provided by domain experts. For comparison, two state-of-the-art closed-source VLMs, GPT-4o and Claude-3.5-Sonnet, are evaluated on the same dataset. All models are assessed using precision, recall, F1-score, and hallucination metrics. Due to the computational cost and impracticality of fine-tuning large closed-source VLMs for domain-specific tasks, GPT-4o and Claude-3.5-Sonnet are evaluated in a zero-shot setting. In contrast, Florence-2, a smaller model with 0.23 billion parameters, is optimized through full-parameter fine-tuning across three distinct experiments, each utilizing datasets augmented to different levels. The results show that Florence-2 achieves a 29.95% increase in precision, a 37.75% increase in recall, a 52.40% improvement in F1-score, and a 43.15% reduction in hallucination rate compared to the best-performing closed-source model. These findings highlight the effectiveness of fine-tuning smaller, open-source VLMs like Florence-2, offering a practical and efficient solution for automated GD&T extraction to support downstream manufacturing tasks.
Automatic Feature Recognition and Dimensional Attributes Extraction From CAD Models for Hybrid Additive-Subtractive Manufacturing
Aug 14, 2024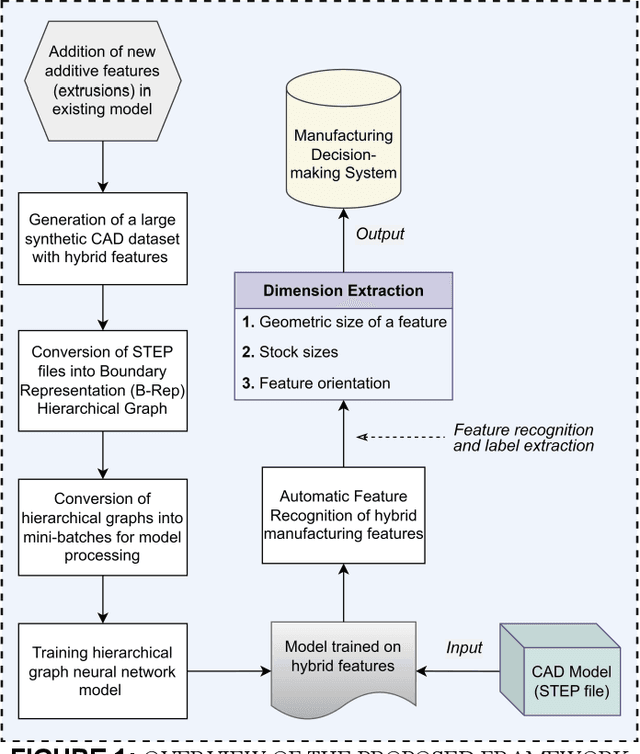
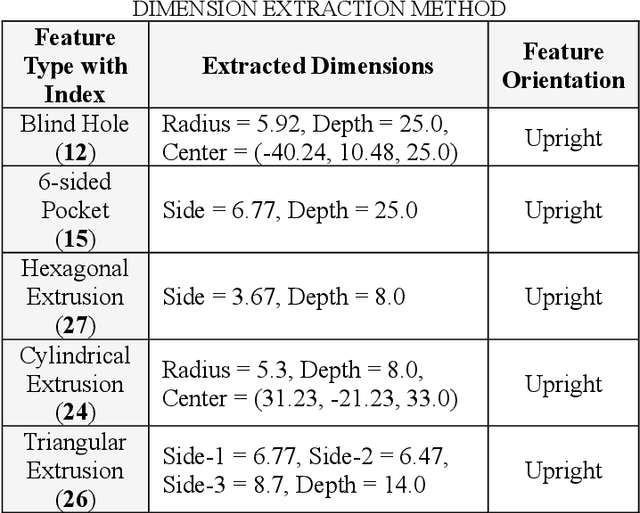

The integration of Computer-Aided Design (CAD), Computer-Aided Process Planning (CAPP), and Computer-Aided Manufacturing (CAM) plays a crucial role in modern manufacturing, facilitating seamless transitions from digital designs to physical products. However, a significant challenge within this integration is the Automatic Feature Recognition (AFR) of CAD models, especially in the context of hybrid manufacturing that combines subtractive and additive manufacturing processes. Traditional AFR methods, focused mainly on the identification of subtractive (machined) features including holes, fillets, chamfers, pockets, and slots, fail to recognize features pertinent to additive manufacturing. Furthermore, the traditional methods fall short in accurately extracting geometric dimensions and orientations, which are also key factors for effective manufacturing process planning. This paper presents a novel approach for creating a synthetic CAD dataset that encompasses features relevant to both additive and subtractive machining through Python Open Cascade. The Hierarchical Graph Convolutional Neural Network (HGCNN) model is implemented to accurately identify the composite additive-subtractive features within the synthetic CAD dataset. The key novelty and contribution of the proposed methodology lie in its ability to recognize a wide range of manufacturing features, and precisely extracting their dimensions, orientations, and stock sizes. The proposed model demonstrates remarkable feature recognition accuracy exceeding 97% and a dimension extraction accuracy of 100% for identified features. Therefore, the proposed methodology enhances the integration of CAD, CAPP, and CAM within hybrid manufacturing by providing precise feature recognition and dimension extraction. It facilitates improved manufacturing process planning, by enabling more informed decision-making.
Audio-visual cross-modality knowledge transfer for machine learning-based in-situ monitoring in laser additive manufacturing
Aug 09, 2024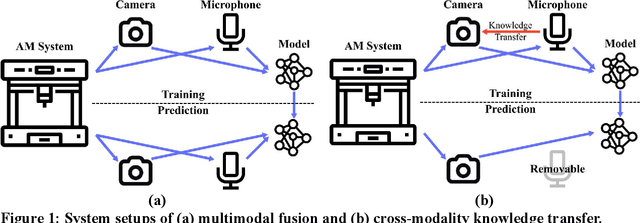
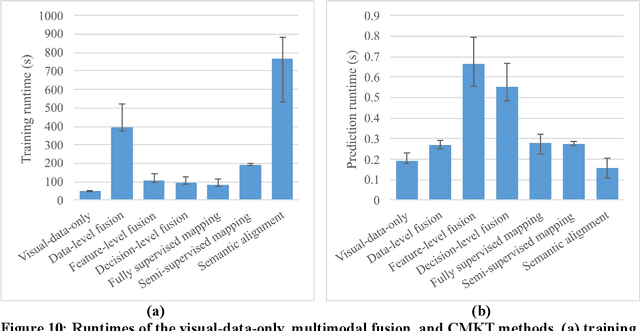
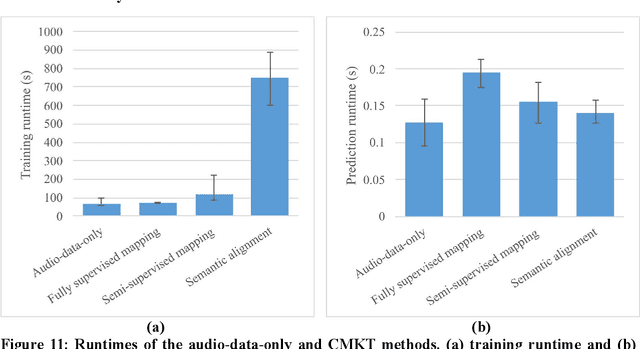
Various machine learning (ML)-based in-situ monitoring systems have been developed to detect laser additive manufacturing (LAM) process anomalies and defects. Multimodal fusion can improve in-situ monitoring performance by acquiring and integrating data from multiple modalities, including visual and audio data. However, multimodal fusion employs multiple sensors of different types, which leads to higher hardware, computational, and operational costs. This paper proposes a cross-modality knowledge transfer (CMKT) methodology that transfers knowledge from a source to a target modality for LAM in-situ monitoring. CMKT enhances the usefulness of the features extracted from the target modality during the training phase and removes the sensors of the source modality during the prediction phase. This paper proposes three CMKT methods: semantic alignment, fully supervised mapping, and semi-supervised mapping. Semantic alignment establishes a shared encoded space between modalities to facilitate knowledge transfer. It utilizes a semantic alignment loss to align the distributions of the same classes (e.g., visual defective and audio defective classes) and a separation loss to separate the distributions of different classes (e.g., visual defective and audio defect-free classes). The two mapping methods transfer knowledge by deriving the features of one modality from the other modality using fully supervised and semi-supervised learning. The proposed CMKT methods were implemented and compared with multimodal audio-visual fusion in an LAM in-situ anomaly detection case study. The semantic alignment method achieves a 98.4% accuracy while removing the audio modality during the prediction phase, which is comparable to the accuracy of multimodal fusion (98.2%).
In-situ process monitoring and adaptive quality enhancement in laser additive manufacturing: a critical review
Apr 21, 2024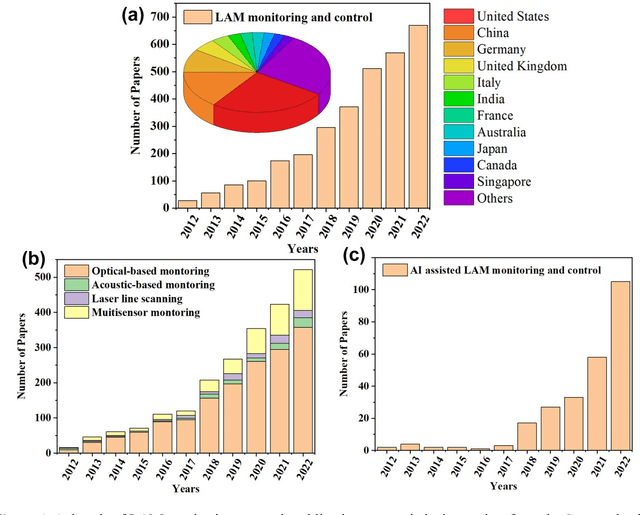
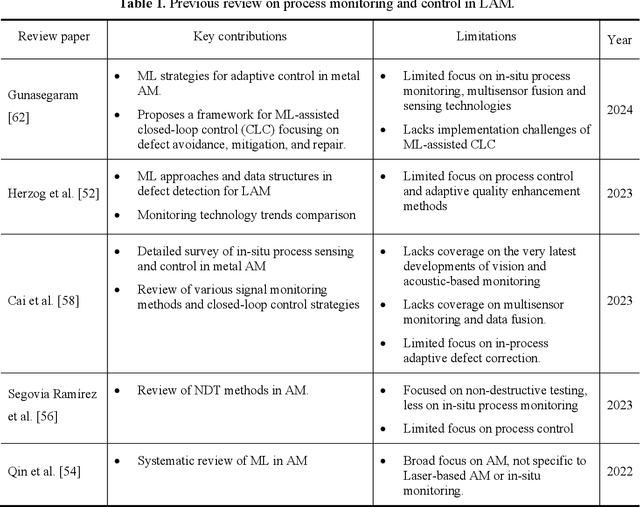
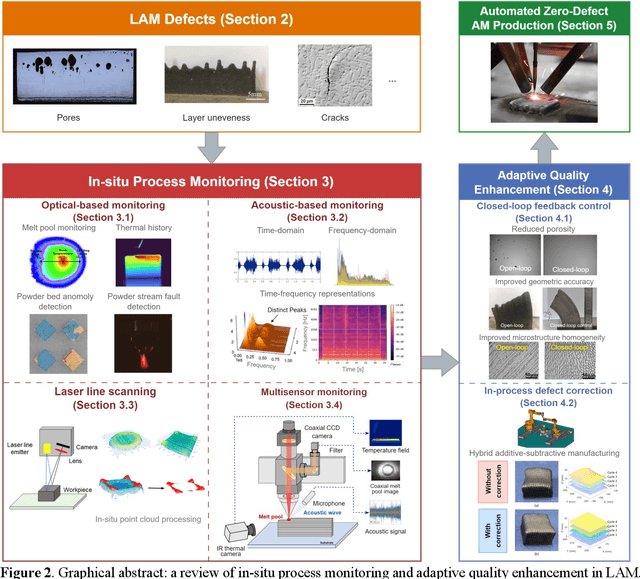
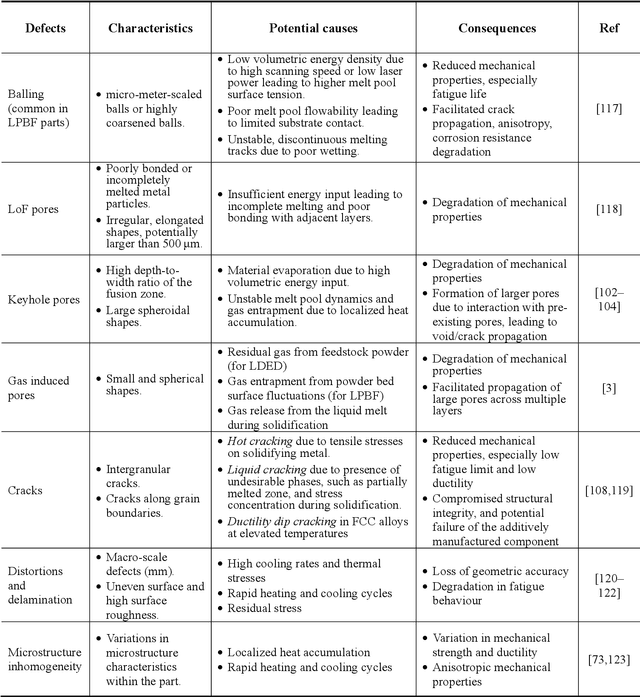
Laser Additive Manufacturing (LAM) presents unparalleled opportunities for fabricating complex, high-performance structures and components with unique material properties. Despite these advancements, achieving consistent part quality and process repeatability remains challenging. This paper provides a comprehensive review of various state-of-the-art in-situ process monitoring techniques, including optical-based monitoring, acoustic-based sensing, laser line scanning, and operando X-ray monitoring. These techniques are evaluated for their capabilities and limitations in detecting defects within Laser Powder Bed Fusion (LPBF) and Laser Directed Energy Deposition (LDED) processes. Furthermore, the review discusses emerging multisensor monitoring and machine learning (ML)-assisted defect detection methods, benchmarking ML models tailored for in-situ defect detection. The paper also discusses in-situ adaptive defect remediation strategies that advance LAM towards zero-defect autonomous operations, focusing on real-time closed-loop feedback control and defect correction methods. Research gaps such as the need for standardization, improved reliability and sensitivity, and decision-making strategies beyond early stopping are highlighted. Future directions are proposed, with an emphasis on multimodal sensor fusion for multiscale defect prediction and fault diagnosis, ultimately enabling self-adaptation in LAM processes. This paper aims to equip researchers and industry professionals with a holistic understanding of the current capabilities, limitations, and future directions in in-situ process monitoring and adaptive quality enhancement in LAM.
Multimodal sensor fusion for real-time location-dependent defect detection in laser-directed energy deposition
May 23, 2023Real-time defect detection is crucial in laser-directed energy deposition (L-DED) additive manufacturing (AM). Traditional in-situ monitoring approach utilizes a single sensor (i.e., acoustic, visual, or thermal sensor) to capture the complex process dynamic behaviors, which is insufficient for defect detection with high accuracy and robustness. This paper proposes a novel multimodal sensor fusion method for real-time location-dependent defect detection in the robotic L-DED process. The multimodal fusion sources include a microphone sensor capturing the laser-material interaction sound and a visible spectrum CCD camera capturing the coaxial melt pool images. A hybrid convolutional neural network (CNN) is proposed to fuse acoustic and visual data. The key novelty in this study is that the traditional manual feature extraction procedures are no longer required, and the raw melt pool images and acoustic signals are fused directly by the hybrid CNN model, which achieved the highest defect prediction accuracy (98.5 %) without the thermal sensing modality. Moreover, unlike previous region-based quality prediction, the proposed hybrid CNN can detect the onset of defect occurrences. The defect prediction outcomes are synchronized and registered with in-situ acquired robot tool-center-point (TCP) data, which enables localized defect identification. The proposed multimodal sensor fusion method offers a robust solution for in-situ defect detection.
Multisensor fusion-based digital twin in additive manufacturing for in-situ quality monitoring and defect correction
Apr 12, 2023Early detection and correction of defects are critical in additive manufacturing (AM) to avoid build failures. In this paper, we present a multisensor fusion-based digital twin for in-situ quality monitoring and defect correction in a robotic laser direct energy deposition process. Multisensor fusion sources consist of an acoustic sensor, an infrared thermal camera, a coaxial vision camera, and a laser line scanner. The key novelty and contribution of this work are to develop a spatiotemporal data fusion method that synchronizes and registers the multisensor features within the part's 3D volume. The fused dataset can be used to predict location-specific quality using machine learning. On-the-fly identification of regions requiring material addition or removal is feasible. Robot toolpath and auto-tuned process parameters are generated for defecting correction. In contrast to traditional single-sensor-based monitoring, multisensor fusion allows for a more in-depth understanding of underlying process physics, such as pore formation and laser-material interactions. The proposed methods pave the way for self-adaptation AM with higher efficiency, less waste, and cleaner production.
In-situ crack and keyhole pore detection in laser directed energy deposition through acoustic signal and deep learning
Apr 10, 2023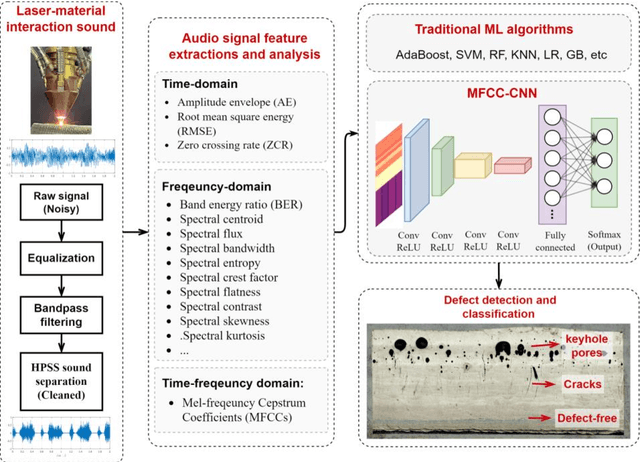
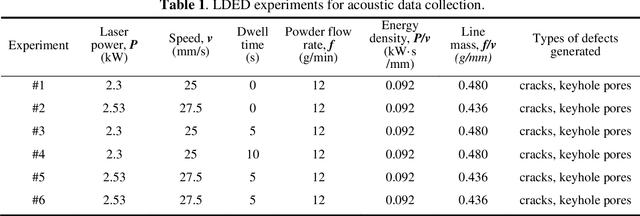


Cracks and keyhole pores are detrimental defects in alloys produced by laser directed energy deposition (LDED). Laser-material interaction sound may hold information about underlying complex physical events such as crack propagation and pores formation. However, due to the noisy environment and intricate signal content, acoustic-based monitoring in LDED has received little attention. This paper proposes a novel acoustic-based in-situ defect detection strategy in LDED. The key contribution of this study is to develop an in-situ acoustic signal denoising, feature extraction, and sound classification pipeline that incorporates convolutional neural networks (CNN) for online defect prediction. Microscope images are used to identify locations of the cracks and keyhole pores within a part. The defect locations are spatiotemporally registered with acoustic signal. Various acoustic features corresponding to defect-free regions, cracks, and keyhole pores are extracted and analysed in time-domain, frequency-domain, and time-frequency representations. The CNN model is trained to predict defect occurrences using the Mel-Frequency Cepstral Coefficients (MFCCs) of the lasermaterial interaction sound. The CNN model is compared to various classic machine learning models trained on the denoised acoustic dataset and raw acoustic dataset. The validation results shows that the CNN model trained on the denoised dataset outperforms others with the highest overall accuracy (89%), keyhole pore prediction accuracy (93%), and AUC-ROC score (98%). Furthermore, the trained CNN model can be deployed into an in-house developed software platform for online quality monitoring. The proposed strategy is the first study to use acoustic signals with deep learning for insitu defect detection in LDED process.
AI Augmented Digital Metal Component
Jan 18, 2022

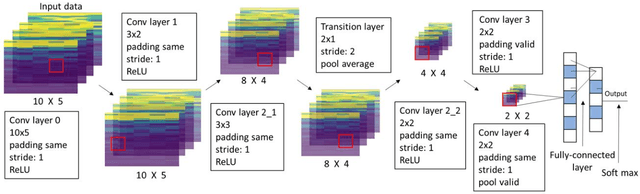

The aim of this work is to propose a new paradigm that imparts intelligence to metal parts with the fusion of metal additive manufacturing and artificial intelligence (AI). Our digital metal part classifies the status with real time data processing with convolutional neural network (CNN). The training data for the CNN is collected from a strain gauge embedded in metal parts by laser powder bed fusion process. We implement this approach using additive manufacturing, demonstrate a self-cognitive metal part recognizing partial screw loosening, malfunctioning, and external impacting object. The results indicate that metal part can recognize subtle change of multiple fixation state under repetitive compression with 89.1% accuracy with test sets. The proposed strategy showed promising potential in contributing to the hyper-connectivity for next generation of digital metal based mechanical systems