 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs this Change the Answer to that Problem? Correlating Descriptions of Bug and Code Changes for Evaluating Patch Correctness
Aug 08, 2022
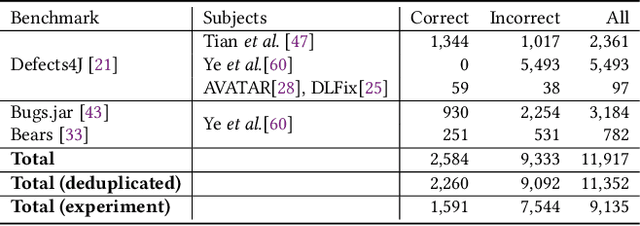
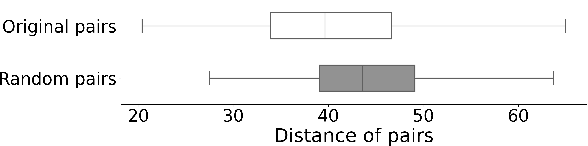
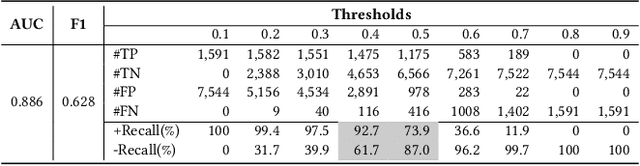
In this work, we propose a novel perspective to the problem of patch correctness assessment: a correct patch implements changes that "answer" to a problem posed by buggy behaviour. Concretely, we turn the patch correctness assessment into a Question Answering problem. To tackle this problem, our intuition is that natural language processing can provide the necessary representations and models for assessing the semantic correlation between a bug (question) and a patch (answer). Specifically, we consider as inputs the bug reports as well as the natural language description of the generated patches. Our approach, Quatrain, first considers state of the art commit message generation models to produce the relevant inputs associated to each generated patch. Then we leverage a neural network architecture to learn the semantic correlation between bug reports and commit messages. Experiments on a large dataset of 9135 patches generated for three bug datasets (Defects4j, Bugs.jar and Bears) show that Quatrain can achieve an AUC of 0.886 on predicting patch correctness, and recalling 93% correct patches while filtering out 62% incorrect patches. Our experimental results further demonstrate the influence of inputs quality on prediction performance. We further perform experiments to highlight that the model indeed learns the relationship between bug reports and code change descriptions for the prediction. Finally, we compare against prior work and discuss the benefits of our approach.
MetaTPTrans: A Meta Learning Approach for Multilingual Code Representation Learning
Jun 13, 2022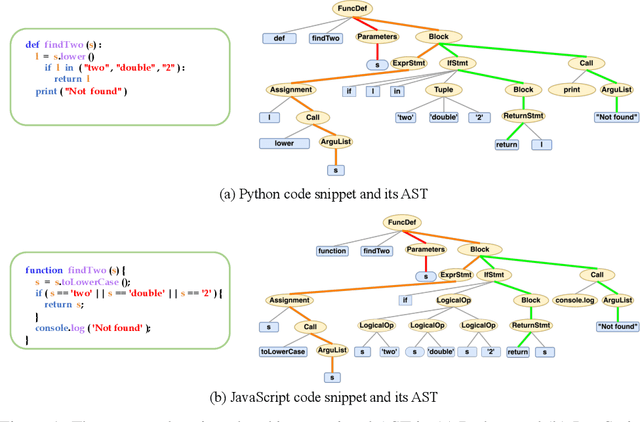
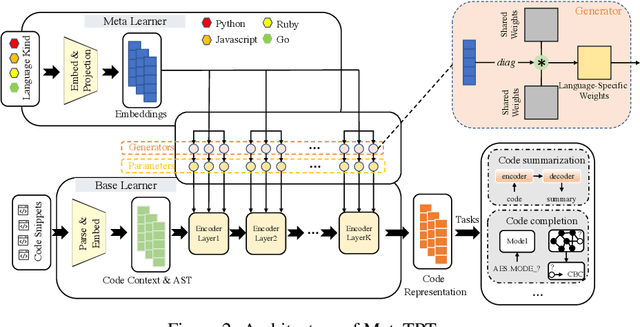
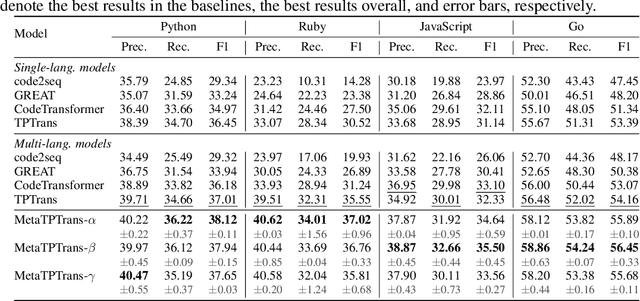
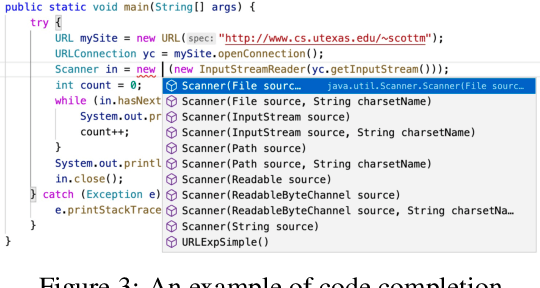
Representation learning of source code is essential for applying machine learning to software engineering tasks. Learning code representation across different programming languages has been shown to be more effective than learning from single-language datasets, since more training data from multi-language datasets improves the model's ability to extract language-agnostic information from source code. However, existing multi-language models overlook the language-specific information which is crucial for downstream tasks that is training on multi-language datasets, while only focusing on learning shared parameters among the different languages. To address this problem, we propose MetaTPTrans, a meta learning approach for multilingual code representation learning. MetaTPTrans generates different parameters for the feature extractor according to the specific programming language of the input source code snippet, enabling the model to learn both language-agnostics and language-specific information. Experimental results show that MetaTPTrans improves the F1 score of state-of-the-art approaches significantly by up to 2.40 percentage points for code summarization, a language-agnostic task; and the prediction accuracy of Top-1 (Top-5) by up to 7.32 (13.15) percentage points for code completion, a language-specific task.
Neural Bug Finding: A Study of Opportunities and Challenges
Jun 01, 2019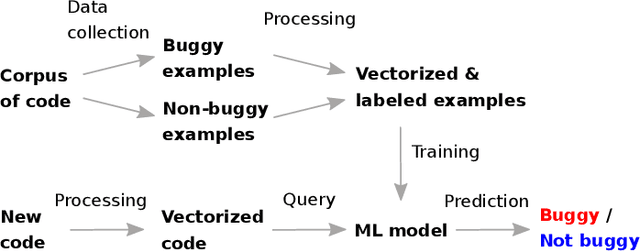
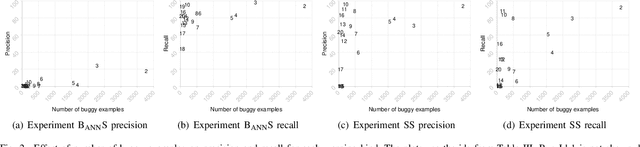
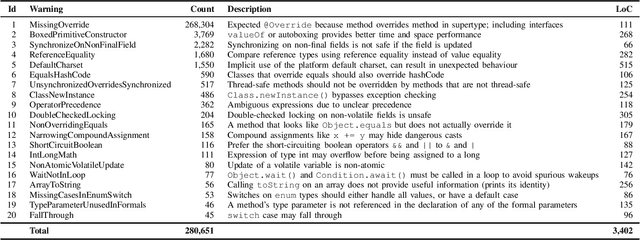
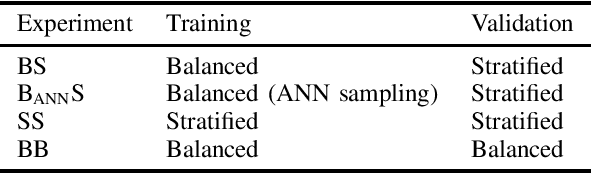
Static analysis is one of the most widely adopted techniques to find software bugs before code is put in production. Designing and implementing effective and efficient static analyses is difficult and requires high expertise, which results in only a few experts able to write such analyses. This paper explores the opportunities and challenges of an alternative way of creating static bug detectors: neural bug finding. The basic idea is to formulate bug detection as a classification problem, and to address this problem with neural networks trained on examples of buggy and non-buggy code. We systematically study the effectiveness of this approach based on code examples labeled by a state-of-the-art, static bug detector. Our results show that neural bug finding is surprisingly effective for some bug patterns, sometimes reaching a precision and recall of over 80%, but also that it struggles to understand some program properties obvious to a traditional analysis. A qualitative analysis of the results provides insights into why neural bug finders sometimes work and sometimes do not work. We also identify pitfalls in selecting the code examples used to train and validate neural bug finders, and propose an algorithm for selecting effective training data.
Viewpoint Invariant Object Detector
Nov 30, 2012Object Detection is the task of identifying the existence of an object class instance and locating it within an image. Difficulties in handling high intra-class variations constitute major obstacles to achieving high performance on standard benchmark datasets (scale, viewpoint, lighting conditions and orientation variations provide good examples). Suggested model aims at providing more robustness to detecting objects suffering severe distortion due to < 60{\deg} viewpoint changes. In addition, several model computational bottlenecks have been resolved leading to a significant increase in the model performance (speed and space) without compromising the resulting accuracy. Finally, we produced two illustrative applications showing the potential of the object detection technology being deployed in real life applications; namely content-based image search and content-based video search.