 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization or Interpolation ? Detecting LLM Memorization through Input Perturbation Analysis
May 05, 2025While Large Language Models (LLMs) achieve remarkable performance through training on massive datasets, they can exhibit concerning behaviors such as verbatim reproduction of training data rather than true generalization. This memorization phenomenon raises significant concerns about data privacy, intellectual property rights, and the reliability of model evaluations. This paper introduces PEARL, a novel approach for detecting memorization in LLMs. PEARL assesses how sensitive an LLM's performance is to input perturbations, enabling memorization detection without requiring access to the model's internals. We investigate how input perturbations affect the consistency of outputs, enabling us to distinguish between true generalization and memorization. Our findings, following extensive experiments on the Pythia open model, provide a robust framework for identifying when the model simply regurgitates learned information. Applied on the GPT 4o models, the PEARL framework not only identified cases of memorization of classic texts from the Bible or common code from HumanEval but also demonstrated that it can provide supporting evidence that some data, such as from the New York Times news articles, were likely part of the training data of a given model.
The Code Barrier: What LLMs Actually Understand?
Apr 14, 2025Understanding code represents a core ability needed for automating software development tasks. While foundation models like LLMs show impressive results across many software engineering challenges, the extent of their true semantic understanding beyond simple token recognition remains unclear. This research uses code obfuscation as a structured testing framework to evaluate LLMs' semantic understanding capabilities. We methodically apply controlled obfuscation changes to source code and measure comprehension through two complementary tasks: generating accurate descriptions of obfuscated code and performing deobfuscation, a skill with important implications for reverse engineering applications. Our testing approach includes 13 cutting-edge models, covering both code-specialized (e.g., StarCoder2) and general-purpose (e.g., GPT-4o) architectures, evaluated on a benchmark created from CodeNet and consisting of filtered 250 Java programming problems and their solutions. Findings show a statistically significant performance decline as obfuscation complexity increases, with unexpected resilience shown by general-purpose models compared to their code-focused counterparts. While some models successfully identify obfuscation techniques, their ability to reconstruct the underlying program logic remains constrained, suggesting limitations in their semantic representation mechanisms. This research introduces a new evaluation approach for assessing code comprehension in language models and establishes empirical baselines for advancing research in security-critical code analysis applications such as reverse engineering and adversarial code analysis.
Early Detection of Security-Relevant Bug Reports using Machine Learning: How Far Are We?
Dec 19, 2021


Bug reports are common artefacts in software development. They serve as the main channel for users to communicate to developers information about the issues that they encounter when using released versions of software programs. In the descriptions of issues, however, a user may, intentionally or not, expose a vulnerability. In a typical maintenance scenario, such security-relevant bug reports are prioritised by the development team when preparing corrective patches. Nevertheless, when security relevance is not immediately expressed (e.g., via a tag) or rapidly identified by triaging teams, the open security-relevant bug report can become a critical leak of sensitive information that attackers can leverage to perform zero-day attacks. To support practitioners in triaging bug reports, the research community has proposed a number of approaches for the detection of security-relevant bug reports. In recent years, approaches in this respect based on machine learning have been reported with promising performance. Our work focuses on such approaches, and revisits their building blocks to provide a comprehensive view on the current achievements. To that end, we built a large experimental dataset and performed extensive experiments with variations in feature sets and learning algorithms. Eventually, our study highlights different approach configurations that yield best performing classifiers.
Checking Patch Behaviour against Test Specification
Jul 28, 2021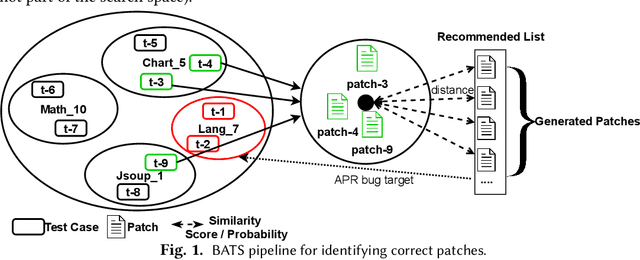
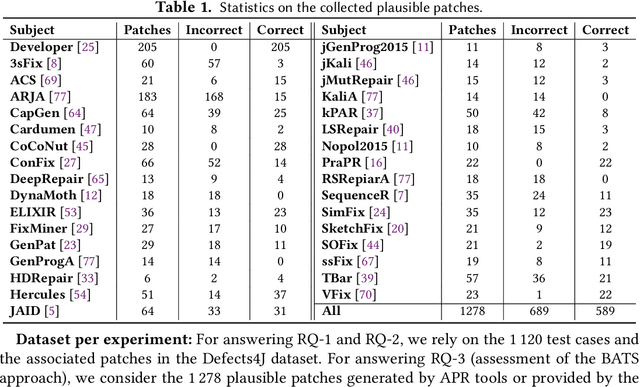

Towards predicting patch correctness in APR, we propose a simple, but novel hypothesis on how the link between the patch behaviour and failing test specifications can be drawn: similar failing test cases should require similar patches. We then propose BATS, an unsupervised learning-based system to predict patch correctness by checking patch Behaviour Against failing Test Specification. BATS exploits deep representation learning models for code and patches: for a given failing test case, the yielded embedding is used to compute similarity metrics in the search for historical similar test cases in order to identify the associated applied patches, which are then used as a proxy for assessing generated patch correctness. Experimentally, we first validate our hypothesis by assessing whether ground-truth developer patches cluster together in the same way that their associated failing test cases are clustered. Then, after collecting a large dataset of 1278 plausible patches (written by developers or generated by some 32 APR tools), we use BATS to predict correctness: BATS achieves an AUC between 0.557 to 0.718 and a recall between 0.562 and 0.854 in identifying correct patches. Compared against previous work, we demonstrate that our approach outperforms state-of-the-art performance in patch correctness prediction, without the need for large labeled patch datasets in contrast with prior machine learning-based approaches. While BATS is constrained by the availability of similar test cases, we show that it can still be complementary to existing approaches: used in conjunction with a recent approach implementing supervised learning, BATS improves the overall recall in detecting correct patches. We finally show that BATS can be complementary to the state-of-the-art PATCH-SIM dynamic approach of identifying the correct patches for APR tools.