 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Detection of Security-Relevant Bug Reports using Machine Learning: How Far Are We?
Paper and Code



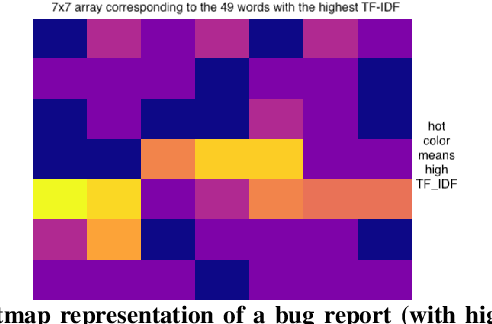
Bug reports are common artefacts in software development. They serve as the main channel for users to communicate to developers information about the issues that they encounter when using released versions of software programs. In the descriptions of issues, however, a user may, intentionally or not, expose a vulnerability. In a typical maintenance scenario, such security-relevant bug reports are prioritised by the development team when preparing corrective patches. Nevertheless, when security relevance is not immediately expressed (e.g., via a tag) or rapidly identified by triaging teams, the open security-relevant bug report can become a critical leak of sensitive information that attackers can leverage to perform zero-day attacks. To support practitioners in triaging bug reports, the research community has proposed a number of approaches for the detection of security-relevant bug reports. In recent years, approaches in this respect based on machine learning have been reported with promising performance. Our work focuses on such approaches, and revisits their building blocks to provide a comprehensive view on the current achievements. To that end, we built a large experimental dataset and performed extensive experiments with variations in feature sets and learning algorithms. Eventually, our study highlights different approach configurations that yield best performing classifiers.