 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextBench: A Benchmark for Context Retrieval in Coding Agents
Feb 05, 2026LLM-based coding agents have shown strong performance on automated issue resolution benchmarks, yet existing evaluations largely focus on final task success, providing limited insight into how agents retrieve and use code context during problem solving. We introduce ContextBench, a process-oriented evaluation of context retrieval in coding agents. ContextBench consists of 1,136 issue-resolution tasks from 66 repositories across eight programming languages, each augmented with human-annotated gold contexts. We further implement an automated evaluation framework that tracks agent trajectories and measures context recall, precision, and efficiency throughout issue resolution. Using ContextBench, we evaluate four frontier LLMs and five coding agents. Our results show that sophisticated agent scaffolding yields only marginal gains in context retrieval ("The Bitter Lesson" of coding agents), LLMs consistently favor recall over precision, and substantial gaps exist between explored and utilized context. ContextBench augments existing end-to-end benchmarks with intermediate gold-context metrics that unbox the issue-resolution process. These contexts offer valuable intermediate signals for guiding LLM reasoning in software tasks. Data and code are available at: https://cioutn.github.io/context-bench/.
Excision Score: Evaluating Edits with Surgical Precision
Oct 24, 2025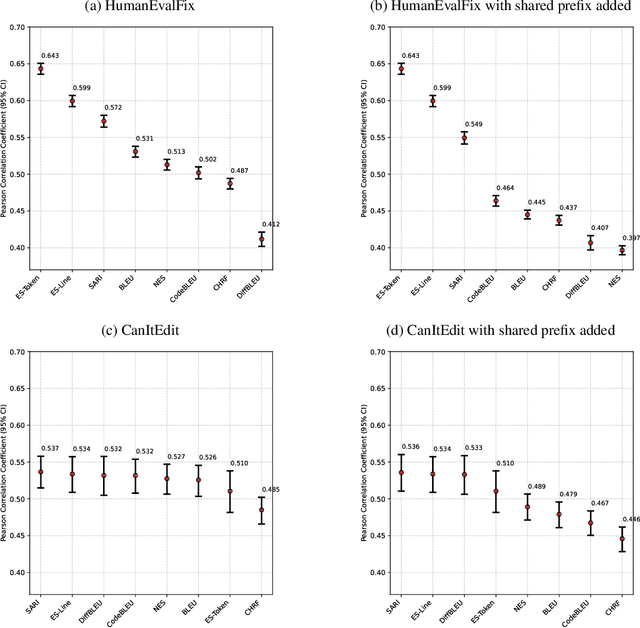
Many tasks revolve around editing a document, whether code or text. We formulate the revision similarity problem to unify a wide range of machine learning evaluation problems whose goal is to assess a revision to an existing document. We observe that revisions usually change only a small portion of an existing document, so the existing document and its immediate revisions share a majority of their content. We formulate five adequacy criteria for revision similarity measures, designed to align them with human judgement. We show that popular pairwise measures, like BLEU, fail to meet these criteria, because their scores are dominated by the shared content. They report high similarity between two revisions when humans would assess them as quite different. This is a fundamental flaw we address. We propose a novel static measure, Excision Score (ES), which computes longest common subsequence (LCS) to remove content shared by an existing document with the ground truth and predicted revisions, before comparing only the remaining divergent regions. This is analogous to a surgeon creating a sterile field to focus on the work area. We use approximation to speed the standard cubic LCS computation to quadratic. In code-editing evaluation, where static measures are often used as a cheap proxy for passing tests, we demonstrate that ES surpasses existing measures. When aligned with test execution on HumanEvalFix, ES improves over its nearest competitor, SARI, by 12% Pearson correlation and by >21% over standard measures like BLEU. The key criterion is invariance to shared context; when we perturb HumanEvalFix with increased shared context, ES' improvement over SARI increases to 20% and >30% over standard measures. ES also handles other corner cases that other measures do not, such as correctly aligning moved code blocks, and appropriately rewarding matching insertions or deletions.
Memorization or Interpolation ? Detecting LLM Memorization through Input Perturbation Analysis
May 05, 2025While Large Language Models (LLMs) achieve remarkable performance through training on massive datasets, they can exhibit concerning behaviors such as verbatim reproduction of training data rather than true generalization. This memorization phenomenon raises significant concerns about data privacy, intellectual property rights, and the reliability of model evaluations. This paper introduces PEARL, a novel approach for detecting memorization in LLMs. PEARL assesses how sensitive an LLM's performance is to input perturbations, enabling memorization detection without requiring access to the model's internals. We investigate how input perturbations affect the consistency of outputs, enabling us to distinguish between true generalization and memorization. Our findings, following extensive experiments on the Pythia open model, provide a robust framework for identifying when the model simply regurgitates learned information. Applied on the GPT 4o models, the PEARL framework not only identified cases of memorization of classic texts from the Bible or common code from HumanEval but also demonstrated that it can provide supporting evidence that some data, such as from the New York Times news articles, were likely part of the training data of a given model.
A Comprehensive Study of the Capabilities of Large Language Models for Vulnerability Detection
Mar 25, 2024



Large Language Models (LLMs) have demonstrated great potential for code generation and other software engineering tasks. Vulnerability detection is of crucial importance to maintaining the security, integrity, and trustworthiness of software systems. Precise vulnerability detection requires reasoning about the code, making it a good case study for exploring the limits of LLMs' reasoning capabilities. Although recent work has applied LLMs to vulnerability detection using generic prompting techniques, their full capabilities for this task and the types of errors they make when explaining identified vulnerabilities remain unclear. In this paper, we surveyed eleven LLMs that are state-of-the-art in code generation and commonly used as coding assistants, and evaluated their capabilities for vulnerability detection. We systematically searched for the best-performing prompts, incorporating techniques such as in-context learning and chain-of-thought, and proposed three of our own prompting methods. Our results show that while our prompting methods improved the models' performance, LLMs generally struggled with vulnerability detection. They reported 0.5-0.63 Balanced Accuracy and failed to distinguish between buggy and fixed versions of programs in 76% of cases on average. By comprehensively analyzing and categorizing 287 instances of model reasoning, we found that 57% of LLM responses contained errors, and the models frequently predicted incorrect locations of buggy code and misidentified bug types. LLMs only correctly localized 6 out of 27 bugs in DbgBench, and these 6 bugs were predicted correctly by 70-100% of human participants. These findings suggest that despite their potential for other tasks, LLMs may fail to properly comprehend critical code structures and security-related concepts. Our data and code are available at https://figshare.com/s/78fe02e56e09ec49300b.
Epicure: Distilling Sequence Model Predictions into Patterns
Aug 16, 2023Most machine learning models predict a probability distribution over concrete outputs and struggle to accurately predict names over high entropy sequence distributions. Here, we explore finding abstract, high-precision patterns intrinsic to these predictions in order to make abstract predictions that usefully capture rare sequences. In this short paper, we present Epicure, a method that distils the predictions of a sequence model, such as the output of beam search, into simple patterns. Epicure maps a model's predictions into a lattice that represents increasingly more general patterns that subsume the concrete model predictions. On the tasks of predicting a descriptive name of a function given the source code of its body and detecting anomalous names given a function, we show that Epicure yields accurate naming patterns that match the ground truth more often compared to just the highest probability model prediction. For a false alarm rate of 10%, Epicure predicts patterns that match 61% more ground-truth names compared to the best model prediction, making Epicure well-suited for scenarios that require high precision.
Improving Few-Shot Prompts with Relevant Static Analysis Products
Apr 13, 2023Large Language Models (LLM) are a new class of computation engines, "programmed" via prompt engineering. We are still learning how to best "program" these LLMs to help developers. We start with the intuition that developers tend to consciously and unconsciously have a collection of semantics facts in mind when working on coding tasks. Mostly these are shallow, simple facts arising from a quick read. For a function, examples of facts might include parameter and local variable names, return expressions, simple pre- and post-conditions, and basic control and data flow, etc. One might assume that the powerful multi-layer architecture of transformer-style LLMs makes them inherently capable of doing this simple level of "code analysis" and extracting such information, implicitly, while processing code: but are they, really? If they aren't, could explicitly adding this information help? Our goal here is to investigate this question, using the code summarization task and evaluate whether automatically augmenting an LLM's prompt with semantic facts explicitly, actually helps. Prior work shows that LLM performance on code summarization benefits from few-shot samples drawn either from the same-project or from examples found via information retrieval methods (such as BM25). While summarization performance has steadily increased since the early days, there is still room for improvement: LLM performance on code summarization still lags its performance on natural-language tasks like translation and text summarization. We find that adding semantic facts actually does help! This approach improves performance in several different settings suggested by prior work, including for two different Large Language Models. In most cases, improvement nears or exceeds 2 BLEU; for the PHP language in the challenging CodeSearchNet dataset, this augmentation actually yields performance surpassing 30 BLEU.
Is Surprisal in Issue Trackers Actionable?
Apr 15, 2022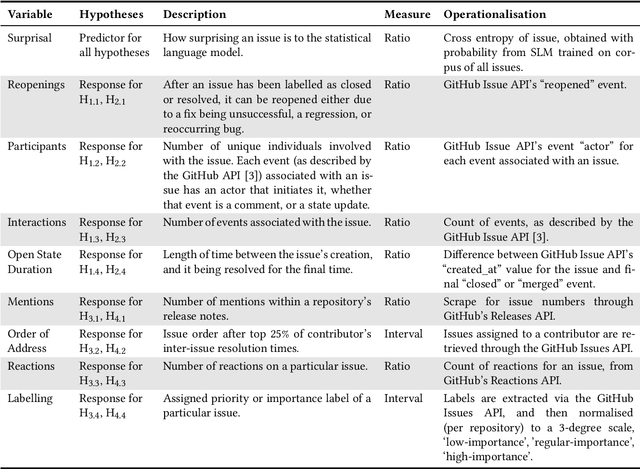
Background. From information theory, surprisal is a measurement of how unexpected an event is. Statistical language models provide a probabilistic approximation of natural languages, and because surprisal is constructed with the probability of an event occuring, it is therefore possible to determine the surprisal associated with English sentences. The issues and pull requests of software repository issue trackers give insight into the development process and likely contain the surprising events of this process. Objective. Prior works have identified that unusual events in software repositories are of interest to developers, and use simple code metrics-based methods for detecting them. In this study we will propose a new method for unusual event detection in software repositories using surprisal. With the ability to find surprising issues and pull requests, we intend to further analyse them to determine if they actually hold importance in a repository, or if they pose a significant challenge to address. If it is possible to find bad surprises early, or before they cause additional troubles, it is plausible that effort, cost and time will be saved as a result. Method. After extracting the issues and pull requests from 5000 of the most popular software repositories on GitHub, we will train a language model to represent these issues. We will measure their perceived importance in the repository, measure their resolution difficulty using several analogues, measure the surprisal of each, and finally generate inferential statistics to describe any correlations.
Typilus: Neural Type Hints
Apr 06, 2020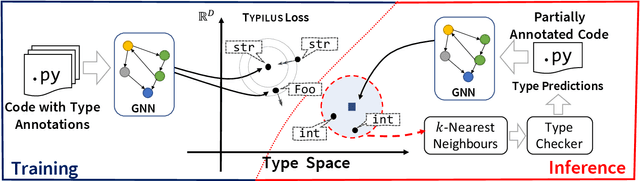

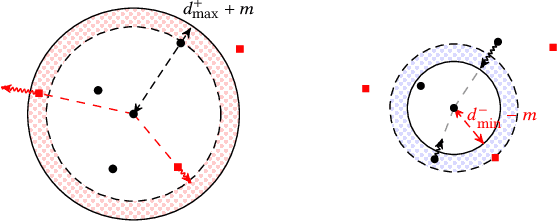
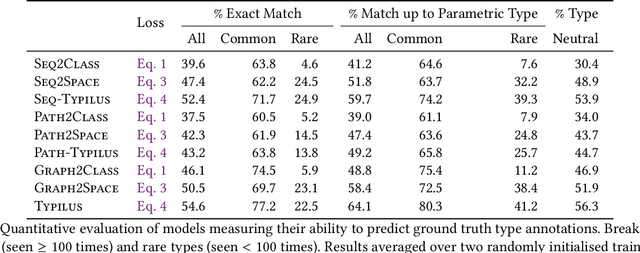
Type inference over partial contexts in dynamically typed languages is challenging. In this work, we present a graph neural network model that predicts types by probabilistically reasoning over a program's structure, names, and patterns. The network uses deep similarity learning to learn a TypeSpace -- a continuous relaxation of the discrete space of types -- and how to embed the type properties of a symbol (i.e. identifier) into it. Importantly, our model can employ one-shot learning to predict an open vocabulary of types, including rare and user-defined ones. We realise our approach in Typilus for Python that combines the TypeSpace with an optional type checker. We show that Typilus accurately predicts types. Typilus confidently predicts types for 70% of all annotatable symbols; when it predicts a type, that type optionally type checks 95% of the time. Typilus can also find incorrect type annotations; two important and popular open source libraries, fairseq and allennlp, accepted our pull requests that fixed the annotation errors Typilus discovered.
OptTyper: Probabilistic Type Inference by Optimising Logical and Natural Constraints
Apr 01, 2020

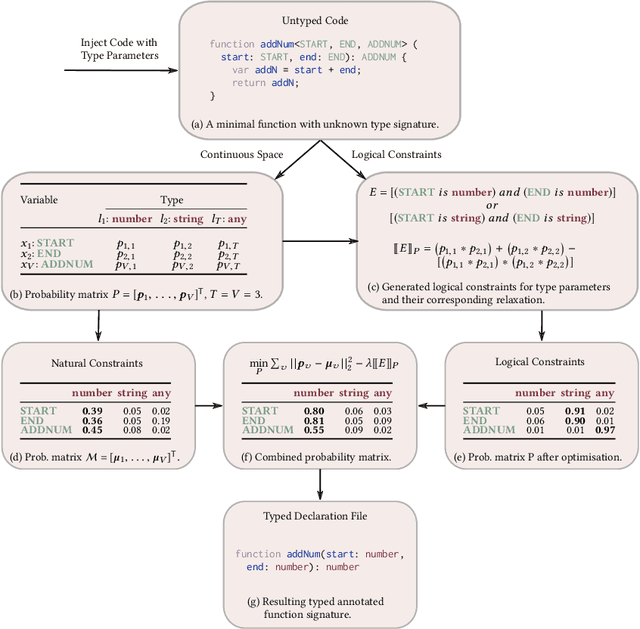

We present a new approach to the type inference problem for dynamic languages. Our goal is to combine logical constraints, that is, deterministic information from a type system, with natural constraints, uncertain information about types from sources like identifier names. To this end, we introduce a framework for probabilistic type inference that combines logic and learning: logical constraints on the types are extracted from the program, and deep learning is applied to predict types from surface-level code properties that are statistically associated, such as variable names. The main insight of our method is to constrain the predictions from the learning procedure to respect the logical constraints, which we achieve by relaxing the logical inference problem of type prediction into a continuous optimisation problem. To evaluate the idea, we built a tool called OptTyper to predict a TypeScript declaration file for a JavaScript library. OptTyper combines a continuous interpretation of logical constraints derived by a simple program transformation and static analysis of the JavaScript code, with natural constraints obtained from a deep learning model, which learns naming conventions for types from a large codebase. We evaluate OptTyper on a data set of 5,800 open-source JavaScript projects that have type annotations in the well-known DefinitelyTyped repository. We find that combining logical and natural constraints yields a large improvement in performance over either kind of information individually, and produces 50% fewer incorrect type predictions than previous approaches.
Perturbed Model Validation: A New Framework to Validate Model Relevance
May 27, 2019
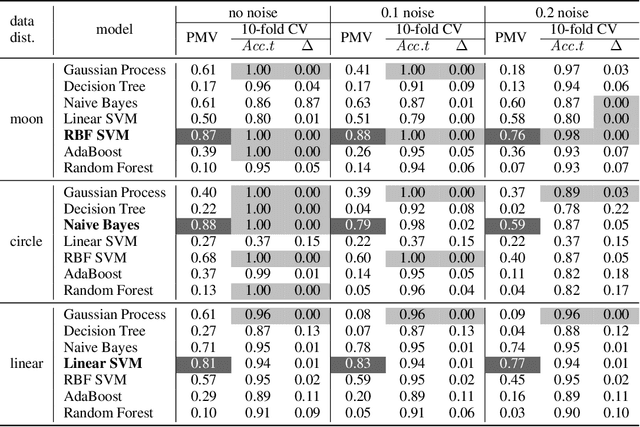
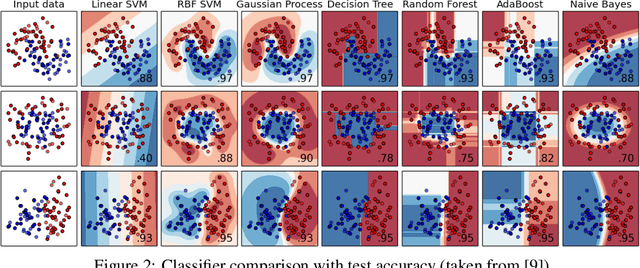
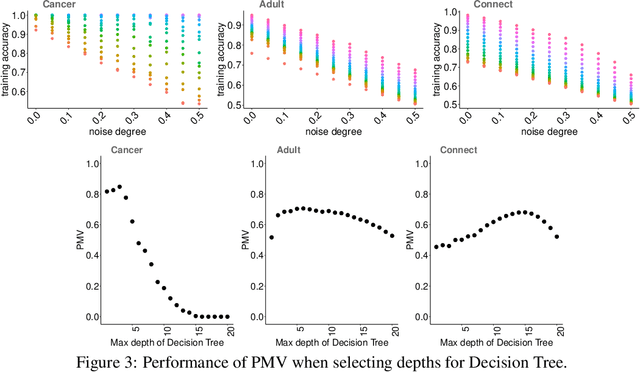
This paper introduces Perturbed Model Validation (PMV), a new technique to validate model relevance and detect overfitting or underfitting. PMV operates by injecting noise to the training data, re-training the model against the perturbed data, then using the training accuracy decrease rate to assess model relevance. A larger decrease rate indicates better concept-hypothesis fit. We realise PMV by perturbing labels to inject noise, and evaluate PMV on four real-world datasets (breast cancer, adult, connect-4, and MNIST) and nine synthetic datasets in the classification setting. The results reveal that PMV selects models more precisely and in a more stable way than cross-validation, and effectively detects both overfitting and underfitting.