 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning to Detect Redundant Method Comments
Jun 12, 2018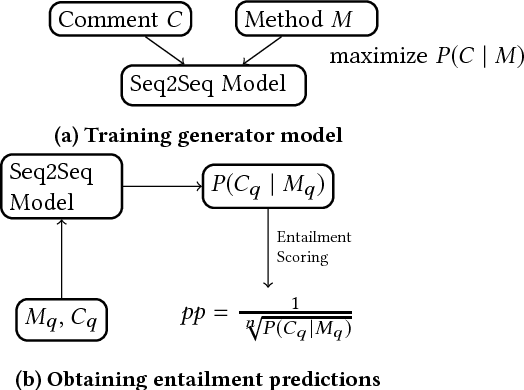
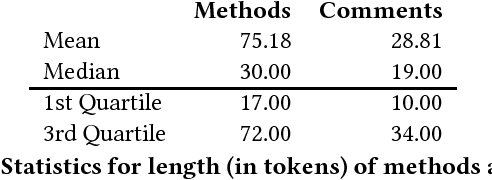
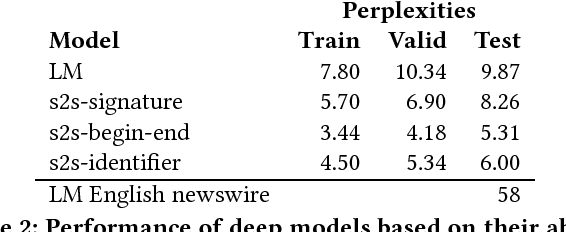
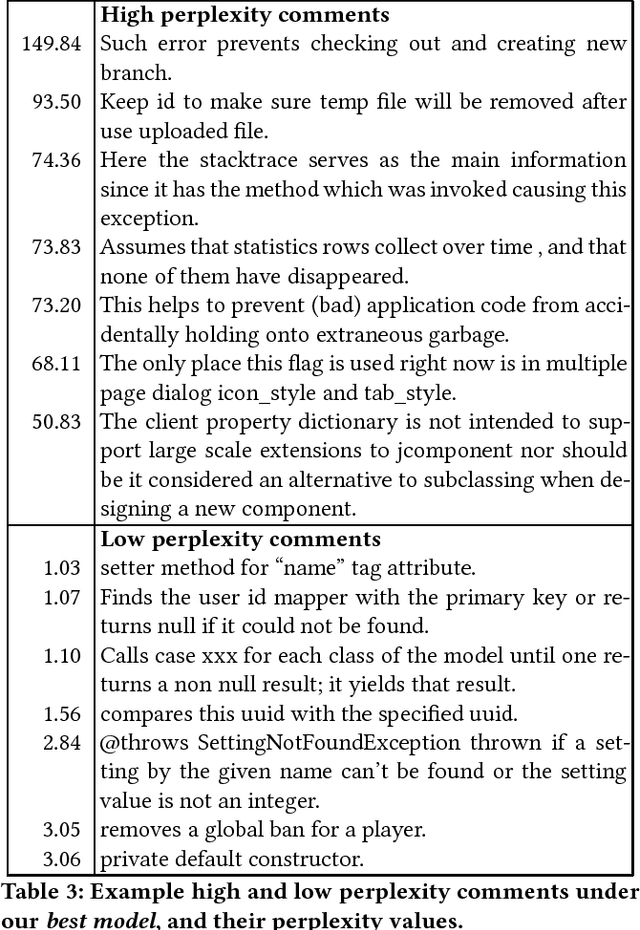
Comments in software are critical for maintenance and reuse. But apart from prescriptive advice, there is little practical support or quantitative understanding of what makes a comment useful. In this paper, we introduce the task of identifying comments which are uninformative about the code they are meant to document. To address this problem, we introduce the notion of comment entailment from code, high entailment indicating that a comment's natural language semantics can be inferred directly from the code. Although not all entailed comments are low quality, comments that are too easily inferred, for example, comments that restate the code, are widely discouraged by authorities on software style. Based on this, we develop a tool called CRAIC which scores method-level comments for redundancy. Highly redundant comments can then be expanded or alternately removed by the developer. CRAIC uses deep language models to exploit large software corpora without requiring expensive manual annotations of entailment. We show that CRAIC can perform the comment entailment task with good agreement with human judgements. Our findings also have implications for documentation tools. For example, we find that common tags in Javadoc are at least two times more predictable from code than non-Javadoc sentences, suggesting that Javadoc tags are less informative than more free-form comments