 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Replace Manual Annotation of Software Engineering Artifacts?
Aug 10, 2024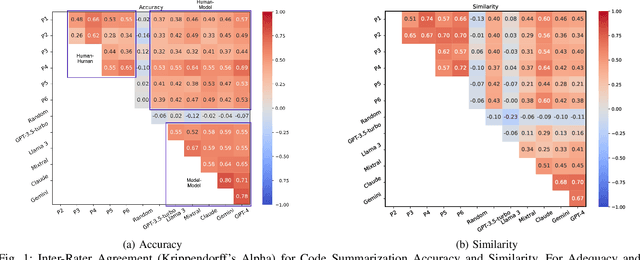
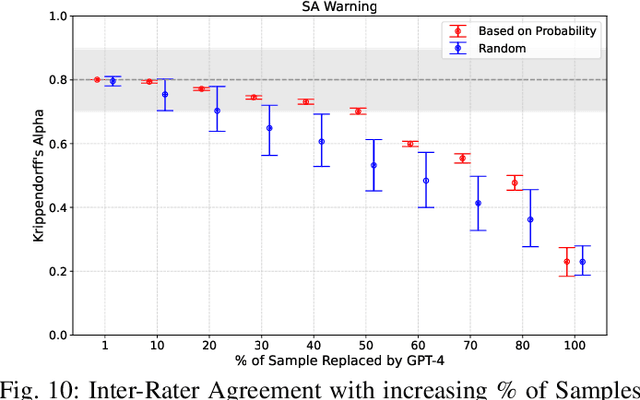
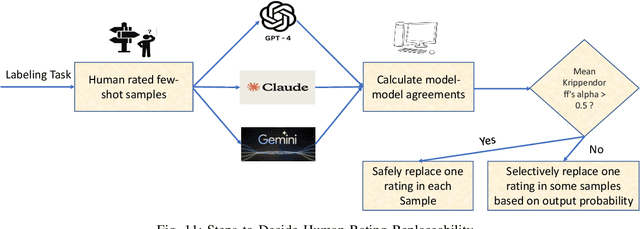
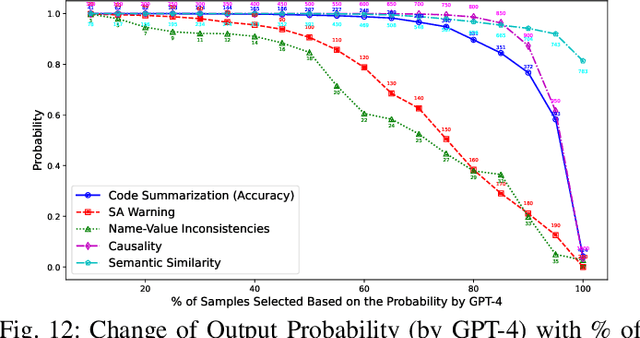
Experimental evaluations of software engineering innovations, e.g., tools and processes, often include human-subject studies as a component of a multi-pronged strategy to obtain greater generalizability of the findings. However, human-subject studies in our field are challenging, due to the cost and difficulty of finding and employing suitable subjects, ideally, professional programmers with varying degrees of experience. Meanwhile, large language models (LLMs) have recently started to demonstrate human-level performance in several areas. This paper explores the possibility of substituting costly human subjects with much cheaper LLM queries in evaluations of code and code-related artifacts. We study this idea by applying six state-of-the-art LLMs to ten annotation tasks from five datasets created by prior work, such as judging the accuracy of a natural language summary of a method or deciding whether a code change fixes a static analysis warning. Our results show that replacing some human annotation effort with LLMs can produce inter-rater agreements equal or close to human-rater agreement. To help decide when and how to use LLMs in human-subject studies, we propose model-model agreement as a predictor of whether a given task is suitable for LLMs at all, and model confidence as a means to select specific samples where LLMs can safely replace human annotators. Overall, our work is the first step toward mixed human-LLM evaluations in software engineering.
Trojans in Large Language Models of Code: A Critical Review through a Trigger-Based Taxonomy
May 05, 2024

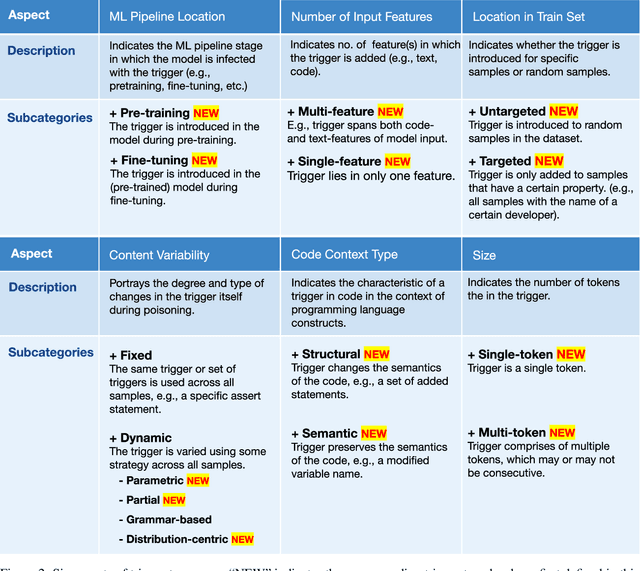

Large language models (LLMs) have provided a lot of exciting new capabilities in software development. However, the opaque nature of these models makes them difficult to reason about and inspect. Their opacity gives rise to potential security risks, as adversaries can train and deploy compromised models to disrupt the software development process in the victims' organization. This work presents an overview of the current state-of-the-art trojan attacks on large language models of code, with a focus on triggers -- the main design point of trojans -- with the aid of a novel unifying trigger taxonomy framework. We also aim to provide a uniform definition of the fundamental concepts in the area of trojans in Code LLMs. Finally, we draw implications of findings on how code models learn on trigger design.
Enhancing Trust in LLM-Generated Code Summaries with Calibrated Confidence Scores
Apr 30, 2024



A good summary can often be very useful during program comprehension. While a brief, fluent, and relevant summary can be helpful, it does require significant human effort to produce. Often, good summaries are unavailable in software projects, thus making maintenance more difficult. There has been a considerable body of research into automated AI-based methods, using Large Language models (LLMs), to generate summaries of code; there also has been quite a bit work on ways to measure the performance of such summarization methods, with special attention paid to how closely these AI-generated summaries resemble a summary a human might have produced. Measures such as BERTScore and BLEU have been suggested and evaluated with human-subject studies. However, LLMs often err and generate something quite unlike what a human might say. Given an LLM-produced code summary, is there a way to gauge whether it's likely to be sufficiently similar to a human produced summary, or not? In this paper, we study this question, as a calibration problem: given a summary from an LLM, can we compute a confidence measure, which is a good indication of whether the summary is sufficiently similar to what a human would have produced in this situation? We examine this question using several LLMs, for several languages, and in several different settings. We suggest an approach which provides well-calibrated predictions of likelihood of similarity to human summaries.
RepairAgent: An Autonomous, LLM-Based Agent for Program Repair
Mar 25, 2024



Automated program repair has emerged as a powerful technique to mitigate the impact of software bugs on system reliability and user experience. This paper introduces RepairAgent, the first work to address the program repair challenge through an autonomous agent based on a large language model (LLM). Unlike existing deep learning-based approaches, which prompt a model with a fixed prompt or in a fixed feedback loop, our work treats the LLM as an agent capable of autonomously planning and executing actions to fix bugs by invoking suitable tools. RepairAgent freely interleaves gathering information about the bug, gathering repair ingredients, and validating fixes, while deciding which tools to invoke based on the gathered information and feedback from previous fix attempts. Key contributions that enable RepairAgent include a set of tools that are useful for program repair, a dynamically updated prompt format that allows the LLM to interact with these tools, and a finite state machine that guides the agent in invoking the tools. Our evaluation on the popular Defects4J dataset demonstrates RepairAgent's effectiveness in autonomously repairing 164 bugs, including 39 bugs not fixed by prior techniques. Interacting with the LLM imposes an average cost of 270,000 tokens per bug, which, under the current pricing of OpenAI's GPT-3.5 model, translates to 14 cents of USD per bug. To the best of our knowledge, this work is the first to present an autonomous, LLM-based agent for program repair, paving the way for future agent-based techniques in software engineering.
Studying LLM Performance on Closed- and Open-source Data
Feb 23, 2024



Large Language models (LLMs) are finding wide use in software engineering practice. These models are extremely data-hungry, and are largely trained on open-source (OSS) code distributed with permissive licenses. In terms of actual use however, a great deal of software development still occurs in the for-profit/proprietary sphere, where the code under development is not, and never has been, in the public domain; thus, many developers, do their work, and use LLMs, in settings where the models may not be as familiar with the code under development. In such settings, do LLMs work as well as they do for OSS code? If not, what are the differences? When performance differs, what are the possible causes, and are there work-arounds? In this paper, we examine this issue using proprietary, closed-source software data from Microsoft, where most proprietary code is in C# and C++. We find that performance for C# changes little from OSS --> proprietary code, but does significantly reduce for C++; we find that this difference is attributable to differences in identifiers. We also find that some performance degradation, in some cases, can be ameliorated efficiently by in-context learning.
Majority Rule: better patching via Self-Consistency
May 31, 2023



Large Language models (LLMs) can be induced to solve non-trivial problems with "few-shot" prompts including illustrative problem-solution examples. Now if the few-shots also include "chain of thought" (CoT) explanations, which are of the form problem-explanation-solution, LLMs will generate a "explained" solution, and perform even better. Recently an exciting, substantially better technique, self-consistency [1] (S-C) has emerged, based on the intuition that there are many plausible explanations for the right solution; when the LLM is sampled repeatedly to generate a pool of explanation-solution pairs, for a given problem, the most frequently occurring solutions in the pool (ignoring the explanations) tend to be even more likely to be correct! Unfortunately, the use of this highly-performant S-C (or even CoT) approach in software engineering settings is hampered by the lack of explanations; most software datasets lack explanations. In this paper, we describe an application of the S-C approach to program repair, using the commit log on the fix as the explanation, only in the illustrative few-shots. We achieve state-of-the art results, beating previous approaches to prompting-based program repair, on the MODIT dataset; we also find evidence suggesting that the correct commit messages are helping the LLM learn to produce better patches.
Improving Few-Shot Prompts with Relevant Static Analysis Products
Apr 13, 2023Large Language Models (LLM) are a new class of computation engines, "programmed" via prompt engineering. We are still learning how to best "program" these LLMs to help developers. We start with the intuition that developers tend to consciously and unconsciously have a collection of semantics facts in mind when working on coding tasks. Mostly these are shallow, simple facts arising from a quick read. For a function, examples of facts might include parameter and local variable names, return expressions, simple pre- and post-conditions, and basic control and data flow, etc. One might assume that the powerful multi-layer architecture of transformer-style LLMs makes them inherently capable of doing this simple level of "code analysis" and extracting such information, implicitly, while processing code: but are they, really? If they aren't, could explicitly adding this information help? Our goal here is to investigate this question, using the code summarization task and evaluate whether automatically augmenting an LLM's prompt with semantic facts explicitly, actually helps. Prior work shows that LLM performance on code summarization benefits from few-shot samples drawn either from the same-project or from examples found via information retrieval methods (such as BM25). While summarization performance has steadily increased since the early days, there is still room for improvement: LLM performance on code summarization still lags its performance on natural-language tasks like translation and text summarization. We find that adding semantic facts actually does help! This approach improves performance in several different settings suggested by prior work, including for two different Large Language Models. In most cases, improvement nears or exceeds 2 BLEU; for the PHP language in the challenging CodeSearchNet dataset, this augmentation actually yields performance surpassing 30 BLEU.
Extending Source Code Pre-Trained Language Models to Summarise Decompiled Binaries
Jan 13, 2023



Reverse engineering binaries is required to understand and analyse programs for which the source code is unavailable. Decompilers can transform the largely unreadable binaries into a more readable source code-like representation. However, reverse engineering is time-consuming, much of which is taken up by labelling the functions with semantic information. While the automated summarisation of decompiled code can help Reverse Engineers understand and analyse binaries, current work mainly focuses on summarising source code, and no suitable dataset exists for this task. In this work, we extend large pre-trained language models of source code to summarise decompiled binary functions. Furthermore, we investigate the impact of input and data properties on the performance of such models. Our approach consists of two main components; the data and the model. We first build CAPYBARA, a dataset of 214K decompiled function-documentation pairs across various compiler optimisations. We extend CAPYBARA further by generating synthetic datasets and deduplicating the data. Next, we fine-tune the CodeT5 base model with CAPYBARA to create BinT5. BinT5 achieves the state-of-the-art BLEU-4 score of 60.83, 58.82, and 44.21 for summarising source, decompiled, and synthetically stripped decompiled code, respectively. This indicates that these models can be extended to decompiled binaries successfully. Finally, we found that the performance of BinT5 is not heavily dependent on the dataset size and compiler optimisation level. We recommend future research to further investigate transferring knowledge when working with less expressive input formats such as stripped binaries.
Few-shot training LLMs for project-specific code-summarization
Jul 09, 2022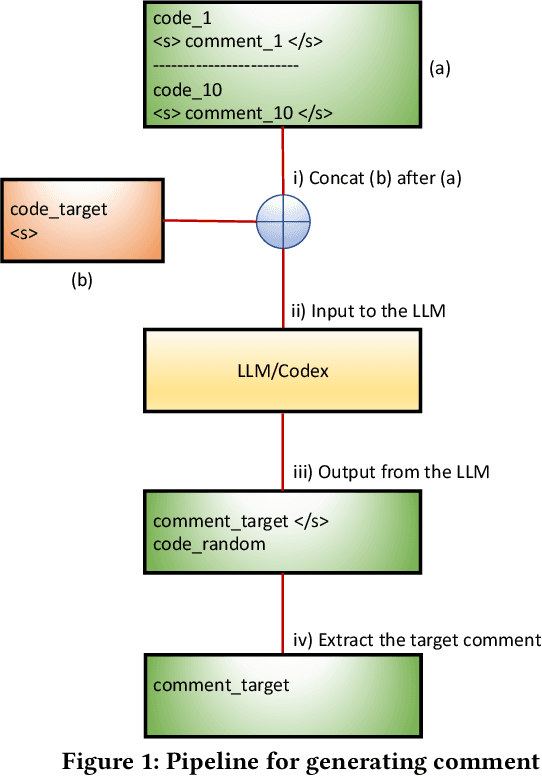
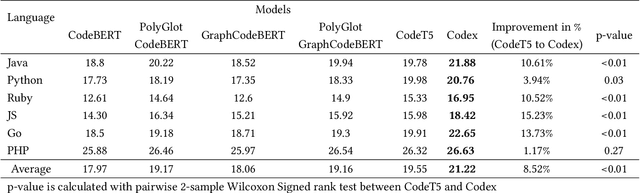
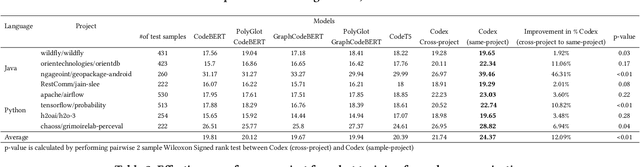
Very large language models (LLMs), such as GPT-3 and Codex have achieved state-of-the-art performance on several natural-language tasks, and show great promise also for code. A particularly exciting aspect of LLMs is their knack for few-shot and zero-shot learning: they can learn to perform a task with very few examples. Few-shotting has particular synergies in software engineering, where there are a lot of phenomena (identifier names, APIs, terminology, coding patterns) that are known to be highly project-specific. However, project-specific data can be quite limited, especially early in the history of a project; thus the few-shot learning capacity of LLMs might be very relevant. In this paper, we investigate the use few-shot training with the very large GPT (Generative Pre-trained Transformer) Codex model, and find evidence suggesting that one can significantly surpass state-of-the-art models for code-summarization, leveraging project-specific training.
NatGen: Generative pre-training by "Naturalizing" source code
Jun 15, 2022

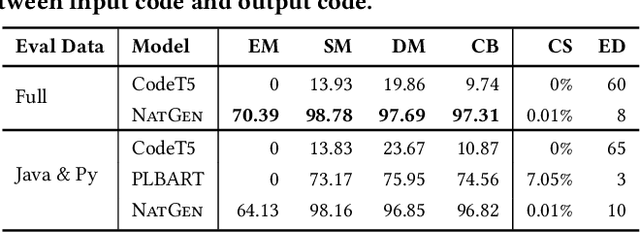
Pre-trained Generative Language models (e.g. PLBART, CodeT5, SPT-Code) for source code yielded strong results on several tasks in the past few years, including code generation and translation. These models have adopted varying pre-training objectives to learn statistics of code construction from very large-scale corpora in a self-supervised fashion; the success of pre-trained models largely hinges on these pre-training objectives. This paper proposes a new pre-training objective, "Naturalizing" of source code, exploiting code's bimodal, dual-channel (formal & natural channels) nature. Unlike natural language, code's bimodal, dual-channel nature allows us to generate semantically equivalent code at scale. We introduce six classes of semantic preserving transformations to introduce un-natural forms of code, and then force our model to produce more natural original programs written by developers. Learning to generate equivalent, but more natural code, at scale, over large corpora of open-source code, without explicit manual supervision, helps the model learn to both ingest & generate code. We fine-tune our model in three generative Software Engineering tasks: code generation, code translation, and code refinement with limited human-curated labeled data and achieve state-of-the-art performance rivaling CodeT5. We show that our pre-trained model is especially competitive at zero-shot and few-shot learning, and better at learning code properties (e.g., syntax, data flow).