 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatGen: Generative pre-training by "Naturalizing" source code
Paper and Code

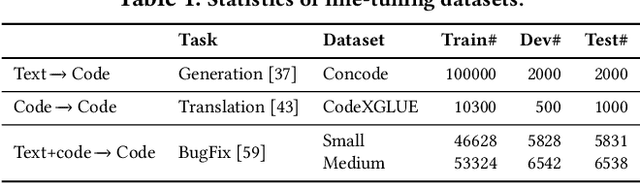

Pre-trained Generative Language models (e.g. PLBART, CodeT5, SPT-Code) for source code yielded strong results on several tasks in the past few years, including code generation and translation. These models have adopted varying pre-training objectives to learn statistics of code construction from very large-scale corpora in a self-supervised fashion; the success of pre-trained models largely hinges on these pre-training objectives. This paper proposes a new pre-training objective, "Naturalizing" of source code, exploiting code's bimodal, dual-channel (formal & natural channels) nature. Unlike natural language, code's bimodal, dual-channel nature allows us to generate semantically equivalent code at scale. We introduce six classes of semantic preserving transformations to introduce un-natural forms of code, and then force our model to produce more natural original programs written by developers. Learning to generate equivalent, but more natural code, at scale, over large corpora of open-source code, without explicit manual supervision, helps the model learn to both ingest & generate code. We fine-tune our model in three generative Software Engineering tasks: code generation, code translation, and code refinement with limited human-curated labeled data and achieve state-of-the-art performance rivaling CodeT5. We show that our pre-trained model is especially competitive at zero-shot and few-shot learning, and better at learning code properties (e.g., syntax, data flow).