 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrojans in Large Language Models of Code: A Critical Review through a Trigger-Based Taxonomy
Paper and Code
May 05, 2024

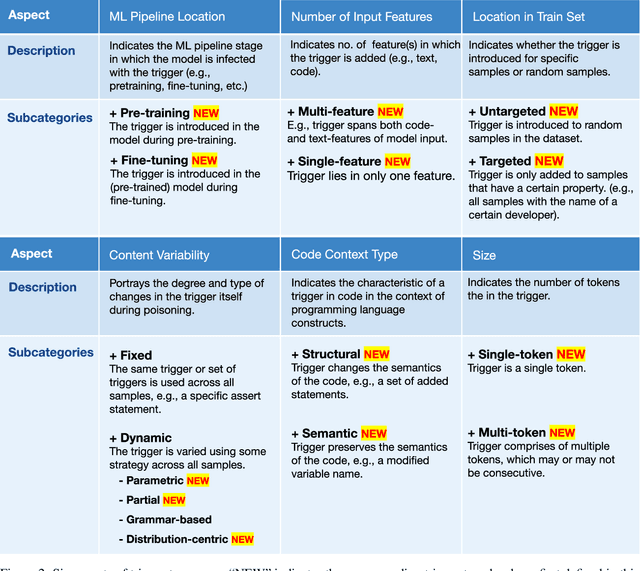

Large language models (LLMs) have provided a lot of exciting new capabilities in software development. However, the opaque nature of these models makes them difficult to reason about and inspect. Their opacity gives rise to potential security risks, as adversaries can train and deploy compromised models to disrupt the software development process in the victims' organization. This work presents an overview of the current state-of-the-art trojan attacks on large language models of code, with a focus on triggers -- the main design point of trojans -- with the aid of a novel unifying trigger taxonomy framework. We also aim to provide a uniform definition of the fundamental concepts in the area of trojans in Code LLMs. Finally, we draw implications of findings on how code models learn on trigger design.