 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Hallucination in Enterprise AI Workflows via Hybrid Utility Minimum Bayes Risk (HUMBR)
Apr 13, 2026Although LLMs drive automation, it is critical to ensure immense consideration for high-stakes enterprise workflows such as those involving legal matters, risk management, and privacy compliance. For Meta, and other organizations like ours, a single hallucinated clause in such high stakes workflows risks material consequences. We show that by framing hallucination mitigation as a Minimum Bayes Risk (MBR) problem, we can dramatically reduce this risk. Specifically, we introduce a Hybrid Utility MBR (HUMBR) framework that synthesizes semantic embedding similarity with lexical precision to identify consensus without ground-truth references, for which we derive rigorous error bounds. We complement this theoretical analysis with a comprehensive empirical evaluation on widely-used public benchmark suites (TruthfulQA and LegalBench) and also real world data from Meta production deployment. The results from our empirical study show that MBR significantly outperforms standard Universal Self-Consistency. Notably, 81% of the pipeline's suggestions were preferred over human-crafted ground truth, and critical recall failures were virtually eliminated.
Just-in-Time Catching Test Generation at Meta
Jan 30, 2026We report on Just-in-Time catching test generation at Meta, designed to prevent bugs in large scale backend systems of hundreds of millions of line of code. Unlike traditional hardening tests, which pass at generation time, catching tests are meant to fail, surfacing bugs before code lands. The primary challenge is to reduce development drag from false positive test failures. Analyzing 22,126 generated tests, we show code-change-aware methods improve candidate catch generation 4x over hardening tests and 20x over coincidentally failing tests. To address false positives, we use rule-based and LLM-based assessors. These assessors reduce human review load by 70%. Inferential statistical analysis showed that human-accepted code changes are assessed to have significantly more false positives, while human-rejected changes have significantly more true positives. We reported 41 candidate catches to engineers; 8 were confirmed to be true positives, 4 of which would have led to serious failures had they remained uncaught. Overall, our results show that Just-in-Time catching is scalable, industrially applicable, and that it prevents serious failures from reaching production.
Library Hallucinations in LLMs: Risk Analysis Grounded in Developer Queries
Sep 26, 2025



Large language models (LLMs) are increasingly used to generate code, yet they continue to hallucinate, often inventing non-existent libraries. Such library hallucinations are not just benign errors: they can mislead developers, break builds, and expose systems to supply chain threats such as slopsquatting. Despite increasing awareness of these risks, little is known about how real-world prompt variations affect hallucination rates. Therefore, we present the first systematic study of how user-level prompt variations impact library hallucinations in LLM-generated code. We evaluate six diverse LLMs across two hallucination types: library name hallucinations (invalid imports) and library member hallucinations (invalid calls from valid libraries). We investigate how realistic user language extracted from developer forums and how user errors of varying degrees (one- or multi-character misspellings and completely fake names/members) affect LLM hallucination rates. Our findings reveal systemic vulnerabilities: one-character misspellings in library names trigger hallucinations in up to 26% of tasks, fake library names are accepted in up to 99% of tasks, and time-related prompts lead to hallucinations in up to 84% of tasks. Prompt engineering shows promise for mitigating hallucinations, but remains inconsistent and LLM-dependent. Our results underscore the fragility of LLMs to natural prompt variation and highlight the urgent need for safeguards against library-related hallucinations and their potential exploitation.
Generative AI for Testing of Autonomous Driving Systems: A Survey
Aug 27, 2025Autonomous driving systems (ADS) have been an active area of research, with the potential to deliver significant benefits to society. However, before large-scale deployment on public roads, extensive testing is necessary to validate their functionality and safety under diverse driving conditions. Therefore, different testing approaches are required, and achieving effective and efficient testing of ADS remains an open challenge. Recently, generative AI has emerged as a powerful tool across many domains, and it is increasingly being applied to ADS testing due to its ability to interpret context, reason about complex tasks, and generate diverse outputs. To gain a deeper understanding of its role in ADS testing, we systematically analyzed 91 relevant studies and synthesized their findings into six major application categories, primarily centered on scenario-based testing of ADS. We also reviewed their effectiveness and compiled a wide range of datasets, simulators, ADS, metrics, and benchmarks used for evaluation, while identifying 27 limitations. This survey provides an overview and practical insights into the use of generative AI for testing ADS, highlights existing challenges, and outlines directions for future research in this rapidly evolving field.
Harden and Catch for Just-in-Time Assured LLM-Based Software Testing: Open Research Challenges
Apr 23, 2025



Despite decades of research and practice in automated software testing, several fundamental concepts remain ill-defined and under-explored, yet offer enormous potential real-world impact. We show that these concepts raise exciting new challenges in the context of Large Language Models for software test generation. More specifically, we formally define and investigate the properties of hardening and catching tests. A hardening test is one that seeks to protect against future regressions, while a catching test is one that catches such a regression or a fault in new functionality introduced by a code change. Hardening tests can be generated at any time and may become catching tests when a future regression is caught. We also define and motivate the Catching `Just-in-Time' (JiTTest) Challenge, in which tests are generated `just-in-time' to catch new faults before they land into production. We show that any solution to Catching JiTTest generation can also be repurposed to catch latent faults in legacy code. We enumerate possible outcomes for hardening and catching tests and JiTTests, and discuss open research problems, deployment options, and initial results from our work on automated LLM-based hardening at Meta. This paper\footnote{Author order is alphabetical. The corresponding author is Mark Harman.} was written to accompany the keynote by the authors at the ACM International Conference on the Foundations of Software Engineering (FSE) 2025.
LLMs Love Python: A Study of LLMs' Bias for Programming Languages and Libraries
Mar 21, 2025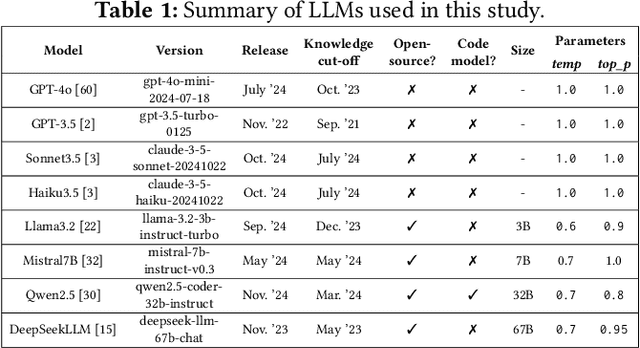
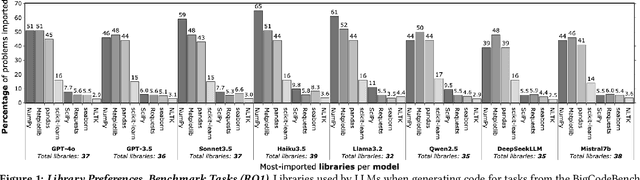
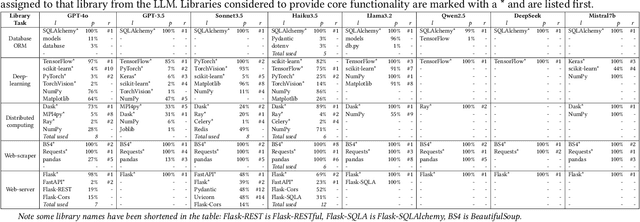
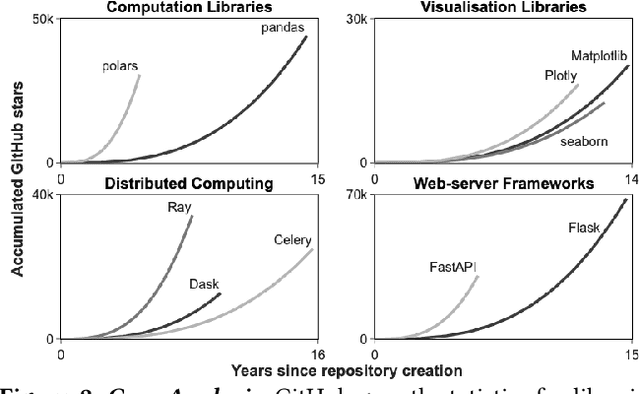
Programming language and library choices are crucial to software reliability and security. Poor or inconsistent choices can lead to increased technical debt, security vulnerabilities, and even catastrophic failures in safety-critical systems. As Large Language Models (LLMs) play an increasing role in code generation, it is essential to understand how they make these decisions. However, little is known about their preferences when selecting programming languages and libraries for different coding tasks. To fill this gap, this study provides the first in-depth investigation into LLM preferences for programming languages and libraries used when generating code. We assess the preferences of eight diverse LLMs by prompting them to complete various coding tasks, including widely-studied benchmarks and the more practical task of generating the initial structural code for new projects (a crucial step that often determines a project's language or library choices). Our findings reveal that LLMs heavily favour Python when solving language-agnostic problems, using it in 90%-97% of cases for benchmark tasks. Even when generating initial project code where Python is not a suitable language, it remains the most-used language in 58% of instances. Moreover, LLMs contradict their own language recommendations in 83% of project initialisation tasks, raising concerns about their reliability in guiding language selection. Similar biases toward well-established libraries further create serious discoverability challenges for newer open-source projects. These results highlight the need to improve LLMs' adaptability to diverse programming contexts and to develop mechanisms for mitigating programming language and library bias.
Rethinking the Influence of Source Code on Test Case Generation
Sep 14, 2024Large language models (LLMs) have been widely applied to assist test generation with the source code under test provided as the context. This paper aims to answer the question: If the source code under test is incorrect, will LLMs be misguided when generating tests? The effectiveness of test cases is measured by their accuracy, coverage, and bug detection effectiveness. Our evaluation results with five open- and six closed-source LLMs on four datasets demonstrate that incorrect code can significantly mislead LLMs in generating correct, high-coverage, and bug-revealing tests. For instance, in the HumanEval dataset, LLMs achieve 80.45% test accuracy when provided with task descriptions and correct code, but only 57.12% when given task descriptions and incorrect code. For the APPS dataset, prompts with correct code yield tests that detect 39.85% of the bugs, while prompts with incorrect code detect only 19.61%. These findings have important implications for the deployment of LLM-based testing: using it on mature code may help protect against future regression, but on early-stage immature code, it may simply bake in errors. Our findings also underscore the need for further research to improve LLMs resilience against incorrect code in generating reliable and bug-revealing tests.
An Empirical Study on Fairness Improvement with Multiple Protected Attributes
Jul 25, 2023Existing research mostly improves the fairness of Machine Learning (ML) software regarding a single protected attribute at a time, but this is unrealistic given that many users have multiple protected attributes. This paper conducts an extensive study of fairness improvement regarding multiple protected attributes, covering 11 state-of-the-art fairness improvement methods. We analyze the effectiveness of these methods with different datasets, metrics, and ML models when considering multiple protected attributes. The results reveal that improving fairness for a single protected attribute can largely decrease fairness regarding unconsidered protected attributes. This decrease is observed in up to 88.3% of scenarios (57.5% on average). More surprisingly, we find little difference in accuracy loss when considering single and multiple protected attributes, indicating that accuracy can be maintained in the multiple-attribute paradigm. However, the effect on precision and recall when handling multiple protected attributes is about 5 times and 8 times that of a single attribute. This has important implications for future fairness research: reporting only accuracy as the ML performance metric, which is currently common in the literature, is inadequate.
Bias Mitigation for Machine Learning Classifiers: A Comprehensive Survey
Jul 15, 2022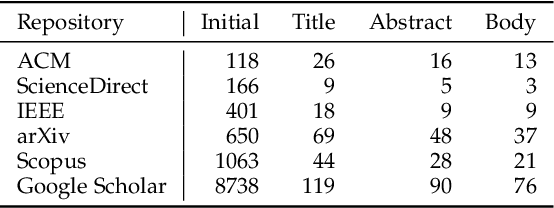
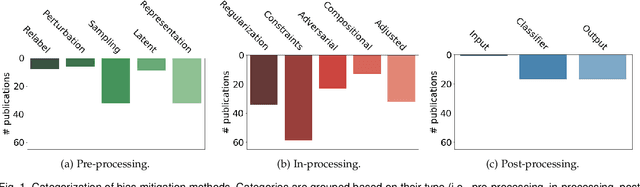
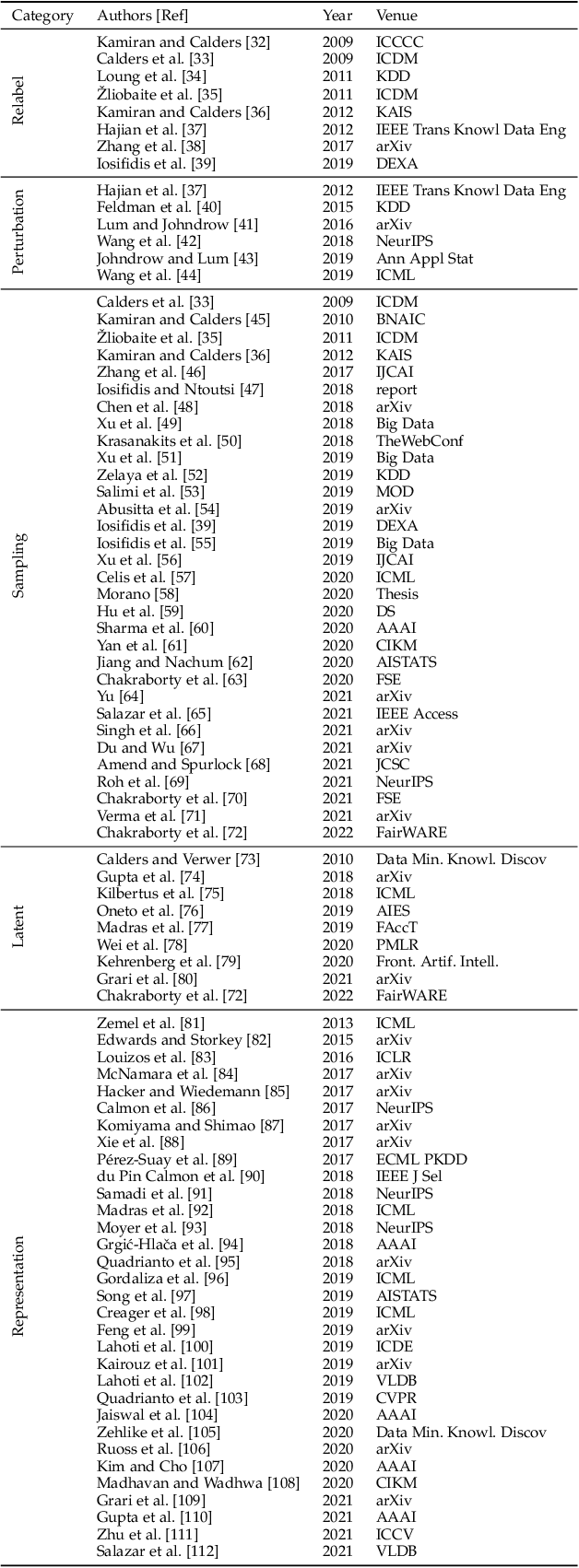
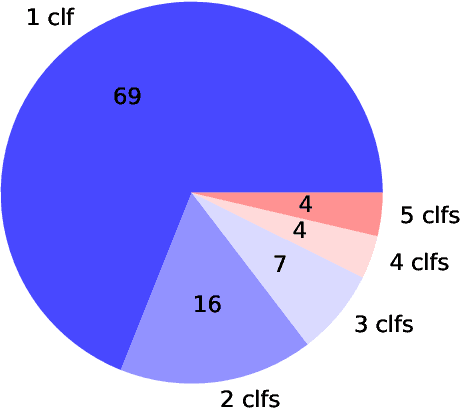
This paper provides a comprehensive survey of bias mitigation methods for achieving fairness in Machine Learning (ML) models. We collect a total of 234 publications concerning bias mitigation for ML classifiers. These methods can be distinguished based on their intervention procedure (i.e., pre-processing, in-processing, post-processing) and the technology they apply. We investigate how existing bias mitigation methods are evaluated in the literature. In particular, we consider datasets, metrics and benchmarking. Based on the gathered insights (e.g., what is the most popular fairness metric? How many datasets are used for evaluating bias mitigation methods?). We hope to support practitioners in making informed choices when developing and evaluating new bias mitigation methods.
A Comprehensive Empirical Study of Bias Mitigation Methods for Software Fairness
Jul 07, 2022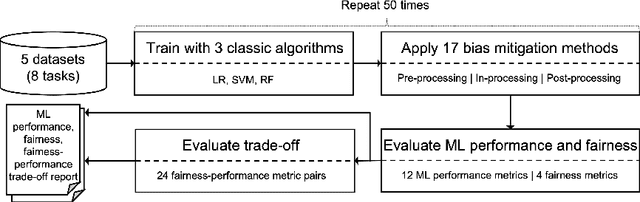

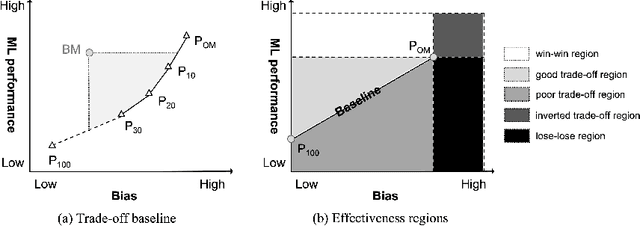
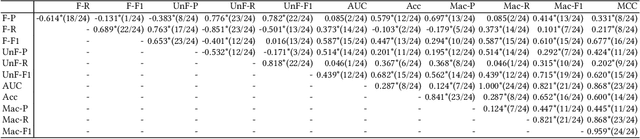
Software bias is an increasingly important operational concern for software engineers. We present a large-scale, comprehensive empirical evaluation of 17 representative bias mitigation methods, evaluated with 12 Machine Learning (ML) performance metrics, 4 fairness metrics, and 24 types of fairness-performance trade-off assessment, applied to 8 widely-adopted benchmark software decision/prediction tasks. The empirical coverage is comprehensive, covering the largest numbers of bias mitigation methods, evaluation metrics, and fairness-performance trade-off measures compared to previous work on this important operational software characteristic. We find that (1) the bias mitigation methods significantly decrease the values reported by all ML performance metrics (including those not considered in previous work) in a large proportion of the scenarios studied (42%~75% according to different ML performance metrics); (2) the bias mitigation methods achieve fairness improvement in only approximately 50% over all scenarios and metrics (ranging between 29%~59% according to the metric used to asses bias/fairness); (3) the bias mitigation methods have a poor fairness-performance trade-off or even lead to decreases in both fairness and ML performance in 37% of the scenarios; (4) the effectiveness of the bias mitigation methods depends on tasks, models, and fairness and ML performance metrics, and there is no 'silver bullet' bias mitigation method demonstrated to be effective for all scenarios studied. The best bias mitigation method that we find outperforms other methods in only 29% of the scenarios. We have made publicly available the scripts and data used in this study in order to allow for future replication and extension of our work.