 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Empirical Study of Bias Mitigation Methods for Software Fairness
Paper and Code
Jul 07, 2022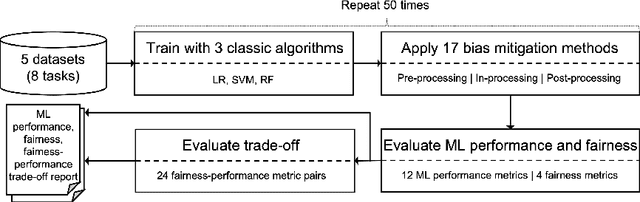

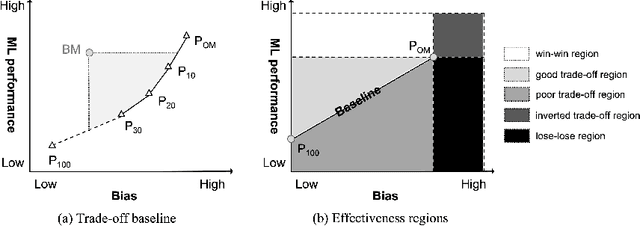
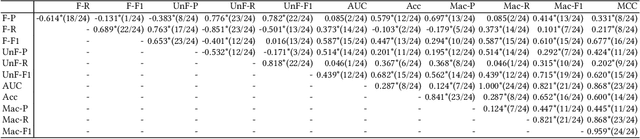
Software bias is an increasingly important operational concern for software engineers. We present a large-scale, comprehensive empirical evaluation of 17 representative bias mitigation methods, evaluated with 12 Machine Learning (ML) performance metrics, 4 fairness metrics, and 24 types of fairness-performance trade-off assessment, applied to 8 widely-adopted benchmark software decision/prediction tasks. The empirical coverage is comprehensive, covering the largest numbers of bias mitigation methods, evaluation metrics, and fairness-performance trade-off measures compared to previous work on this important operational software characteristic. We find that (1) the bias mitigation methods significantly decrease the values reported by all ML performance metrics (including those not considered in previous work) in a large proportion of the scenarios studied (42%~75% according to different ML performance metrics); (2) the bias mitigation methods achieve fairness improvement in only approximately 50% over all scenarios and metrics (ranging between 29%~59% according to the metric used to asses bias/fairness); (3) the bias mitigation methods have a poor fairness-performance trade-off or even lead to decreases in both fairness and ML performance in 37% of the scenarios; (4) the effectiveness of the bias mitigation methods depends on tasks, models, and fairness and ML performance metrics, and there is no 'silver bullet' bias mitigation method demonstrated to be effective for all scenarios studied. The best bias mitigation method that we find outperforms other methods in only 29% of the scenarios. We have made publicly available the scripts and data used in this study in order to allow for future replication and extension of our work.