 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Love Python: A Study of LLMs' Bias for Programming Languages and Libraries
Paper and Code
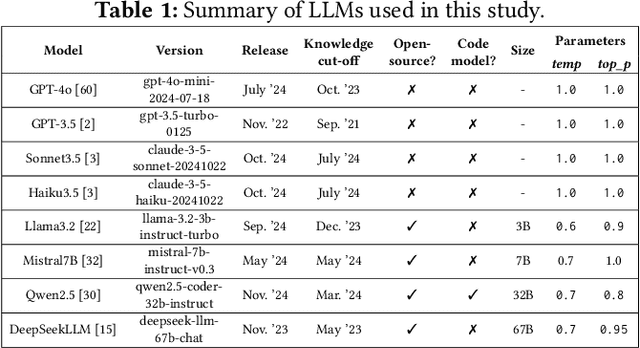
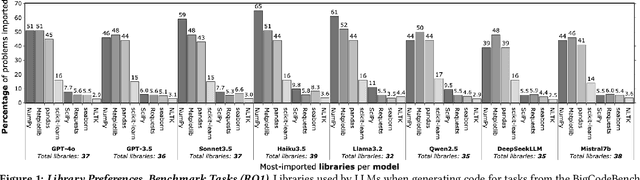
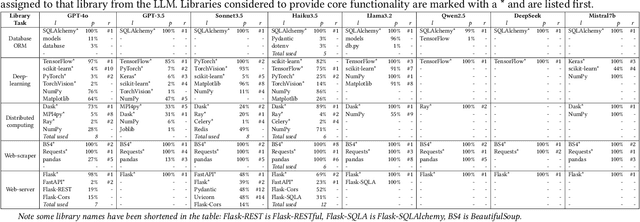
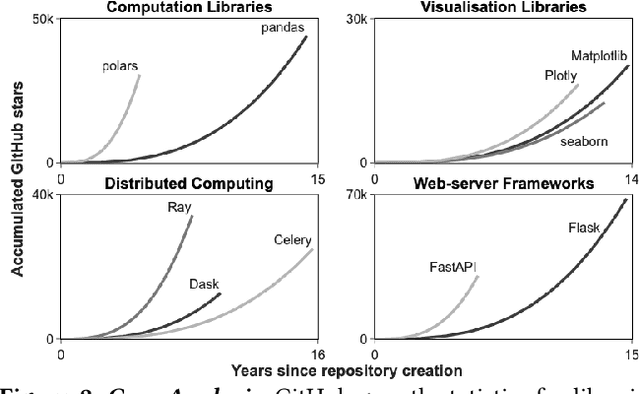
Programming language and library choices are crucial to software reliability and security. Poor or inconsistent choices can lead to increased technical debt, security vulnerabilities, and even catastrophic failures in safety-critical systems. As Large Language Models (LLMs) play an increasing role in code generation, it is essential to understand how they make these decisions. However, little is known about their preferences when selecting programming languages and libraries for different coding tasks. To fill this gap, this study provides the first in-depth investigation into LLM preferences for programming languages and libraries used when generating code. We assess the preferences of eight diverse LLMs by prompting them to complete various coding tasks, including widely-studied benchmarks and the more practical task of generating the initial structural code for new projects (a crucial step that often determines a project's language or library choices). Our findings reveal that LLMs heavily favour Python when solving language-agnostic problems, using it in 90%-97% of cases for benchmark tasks. Even when generating initial project code where Python is not a suitable language, it remains the most-used language in 58% of instances. Moreover, LLMs contradict their own language recommendations in 83% of project initialisation tasks, raising concerns about their reliability in guiding language selection. Similar biases toward well-established libraries further create serious discoverability challenges for newer open-source projects. These results highlight the need to improve LLMs' adaptability to diverse programming contexts and to develop mechanisms for mitigating programming language and library bias.