 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeSPARQL: Representing and Reconciling Agnostic and Atheistic Beliefs in RDF-star Knowledge Graphs
Aug 01, 2024Over the past few years, we have seen the emergence of large knowledge graphs combining information from multiple sources. Sometimes, this information is provided in the form of assertions about other assertions, defining contexts where assertions are valid. A recent extension to RDF which admits statements over statements, called RDF-star, is in revision to become a W3C standard. However, there is no proposal for a semantics of these RDF-star statements nor a built-in facility to operate over them. In this paper, we propose a query language for epistemic RDF-star metadata based on a four-valued logic, called eSPARQL. Our proposed query language extends SPARQL-star, the query language for RDF-star, with a new type of FROM clause to facilitate operating with multiple and sometimes conflicting beliefs. We show that the proposed query language can express four use case queries, including the following features: (i) querying the belief of an individual, (ii) the aggregating of beliefs, (iii) querying who is conflicting with somebody, and (iv) beliefs about beliefs (i.e., nesting of beliefs).
From Shapes to Shapes: Inferring SHACL Shapes for Results of SPARQL CONSTRUCT Queries
Feb 13, 2024
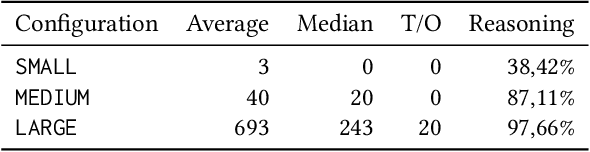
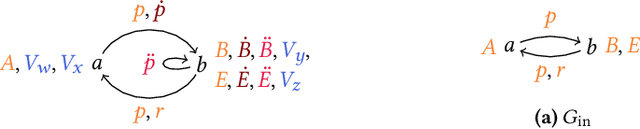
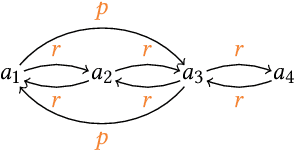
SPARQL CONSTRUCT queries allow for the specification of data processing pipelines that transform given input graphs into new output graphs. It is now common to constrain graphs through SHACL shapes allowing users to understand which data they can expect and which not. However, it becomes challenging to understand what graph data can be expected at the end of a data processing pipeline without knowing the particular input data: Shape constraints on the input graph may affect the output graph, but may no longer apply literally, and new shapes may be imposed by the query template. In this paper, we study the derivation of shape constraints that hold on all possible output graphs of a given SPARQL CONSTRUCT query. We assume that the SPARQL CONSTRUCT query is fixed, e.g., being part of a program, whereas the input graphs adhere to input shape constraints but may otherwise vary over time and, thus, are mostly unknown. We study a fragment of SPARQL CONSTRUCT queries (SCCQ) and a fragment of SHACL (Simple SHACL). We formally define the problem of deriving the most restrictive set of Simple SHACL shapes that constrain the results from evaluating a SCCQ over any input graph restricted by a given set of Simple SHACL shapes. We propose and implement an algorithm that statically analyses input SHACL shapes and CONSTRUCT queries and prove its soundness and complexity.
ProGS: Property Graph Shapes Language (Extended Version)
Jul 12, 2021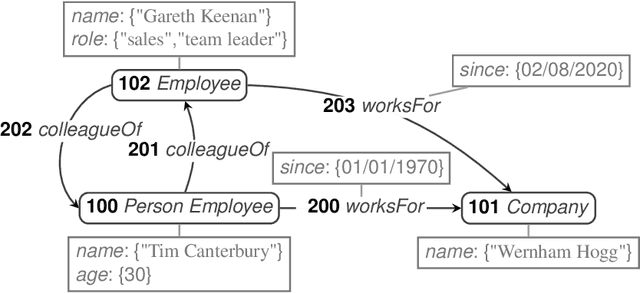
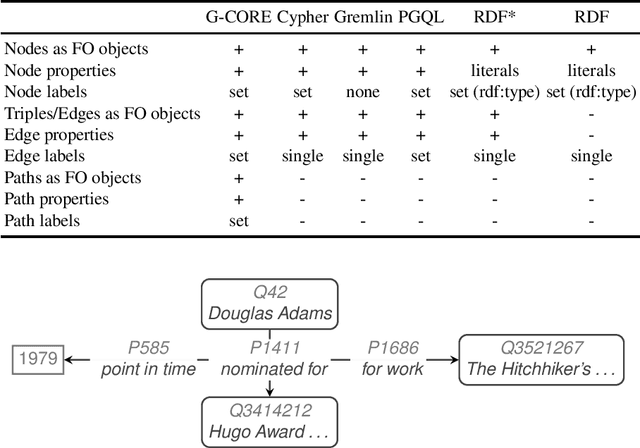


Property graphs constitute data models for representing knowledge graphs. They allow for the convenient representation of facts, including facts about facts, represented by triples in subject or object position of other triples. Knowledge graphs such as Wikidata are created by a diversity of contributors and a range of sources leaving them prone to two types of errors. The first type of error, falsity of facts, is addressed by property graphs through the representation of provenance and validity, making triples occur as first-order objects in subject position of metadata triples. The second type of error, violation of domain constraints, has not been addressed with regard to property graphs so far. In RDF representations, this error can be addressed by shape languages such as SHACL or ShEx, which allow for checking whether graphs are valid with respect to a set of domain constraints. Borrowing ideas from the syntax and semantics definitions of SHACL, we design a shape language for property graphs, ProGS, which allows for formulating shape constraints on property graphs including their specific constructs, such as edges with identities and key-value annotations to both nodes and edges. We define a formal semantics of ProGS, investigate the resulting complexity of validating property graphs against sets of ProGS shapes, compare with corresponding results for SHACL, and implement a prototypical validator that utilizes answer set programming.
Ownership at Large -- Open Problems and Challenges in Ownership Management
Apr 15, 2020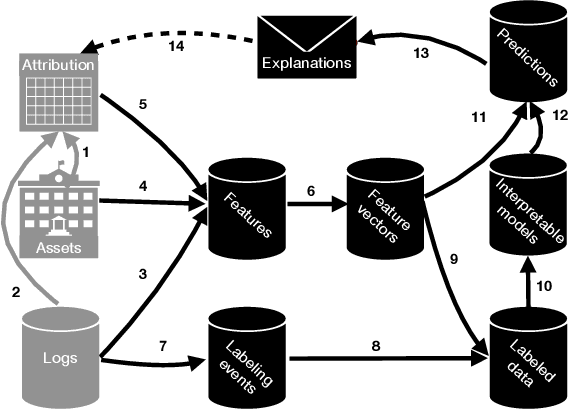
Software-intensive organizations rely on large numbers of software assets of different types, e.g., source-code files, tables in the data warehouse, and software configurations. Who is the most suitable owner of a given asset changes over time, e.g., due to reorganization and individual function changes. New forms of automation can help suggest more suitable owners for any given asset at a given point in time. By such efforts on ownership health, accountability of ownership is increased. The problem of finding the most suitable owners for an asset is essentially a program comprehension problem: how do we automatically determine who would be best placed to understand, maintain, evolve (and thereby assume ownership of) a given asset. This paper introduces the Facebook Ownesty system, which uses a combination of ultra large scale data mining and machine learning and has been deployed at Facebook as part of the company's ownership management approach. Ownesty processes many millions of software assets (e.g., source-code files) and it takes into account workflow and organizational aspects. The paper sets out open problems and challenges on ownership for the research community with advances expected from the fields of software engineering, programming languages, and machine learning.
Understanding What Software Engineers Are Working on -- The Work-Item Prediction Challenge
Apr 13, 2020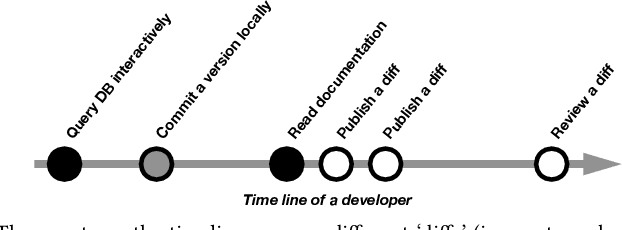

Understanding what a software engineer (a developer, an incident responder, a production engineer, etc.) is working on is a challenging problem -- especially when considering the more complex software engineering workflows in software-intensive organizations: i) engineers rely on a multitude (perhaps hundreds) of loosely integrated tools; ii) engineers engage in concurrent and relatively long running workflows; ii) infrastructure (such as logging) is not fully aware of work items; iv) engineering processes (e.g., for incident response) are not explicitly modeled. In this paper, we explain the corresponding 'work-item prediction challenge' on the grounds of representative scenarios, report on related efforts at Facebook, discuss some lessons learned, and review related work to call to arms to leverage, advance, and combine techniques from program comprehension, mining software repositories, process mining, and machine learning.
WES: Agent-based User Interaction Simulation on Real Infrastructure
Apr 11, 2020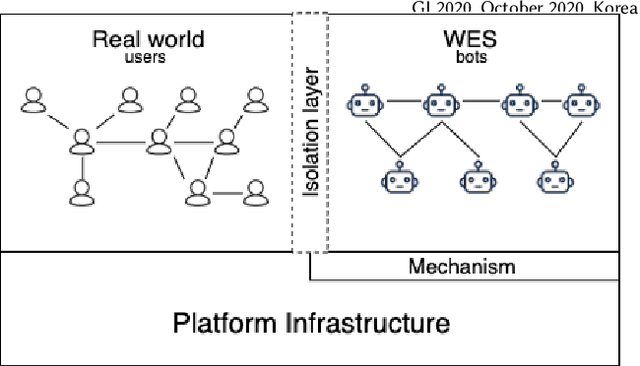
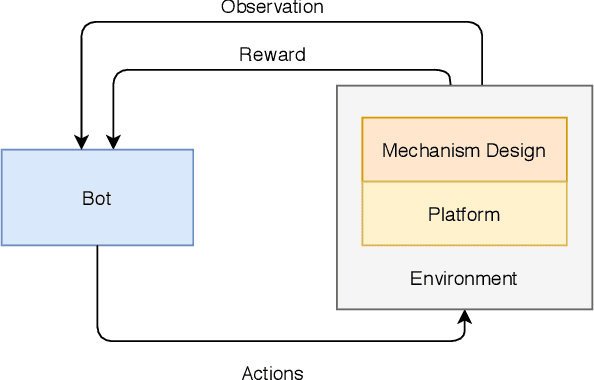
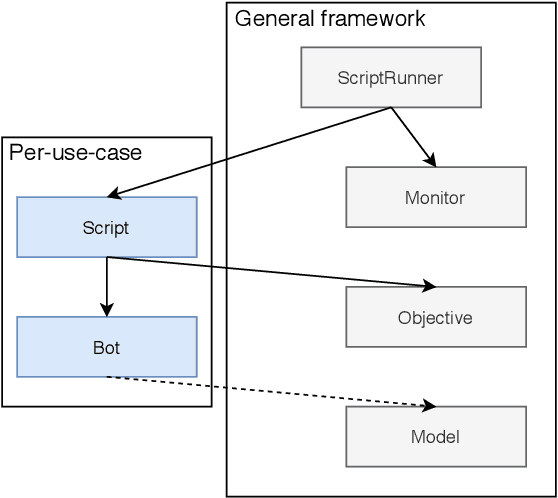
We introduce the Web-Enabled Simulation (WES) research agenda, and describe FACEBOOK's WW system. We describe the application of WW to reliability, integrity and privacy at FACEBOOK , where it is used to simulate social media interactions on an infrastructure consisting of hundreds of millions of lines of code. The WES agenda draws on research from many areas of study, including Search Based Software Engineering, Machine Learning, Programming Languages, Multi Agent Systems, Graph Theory, Game AI, and AI Assisted Game Play. We conclude with a set of open problems and research challenges to motivate wider investigation.