 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicate-Conditional Conformalized Answer Sets for Knowledge Graph Embeddings
May 22, 2025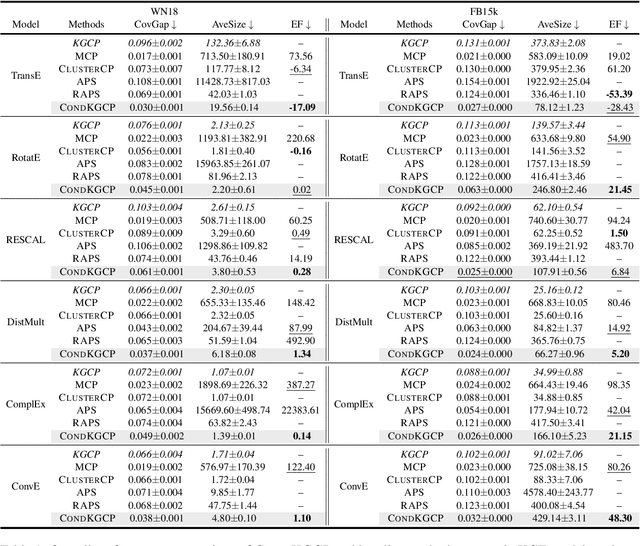
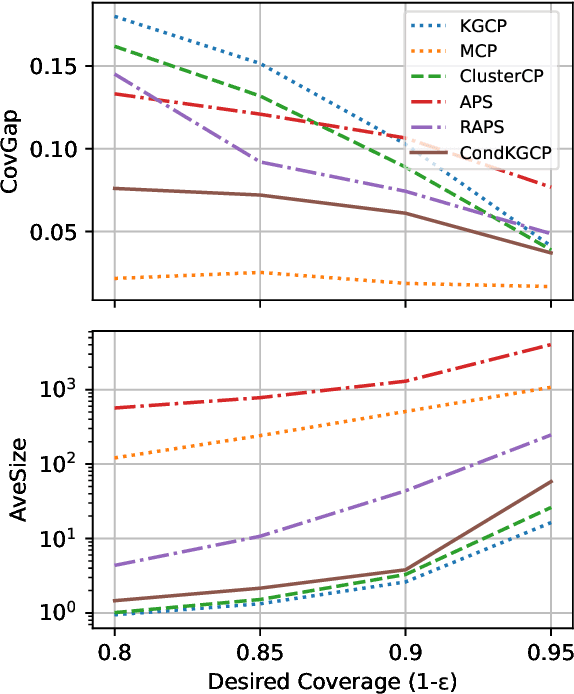
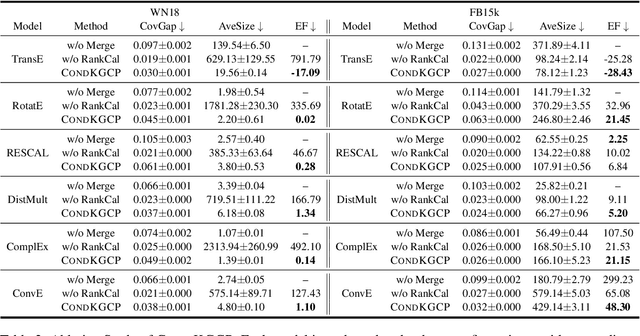
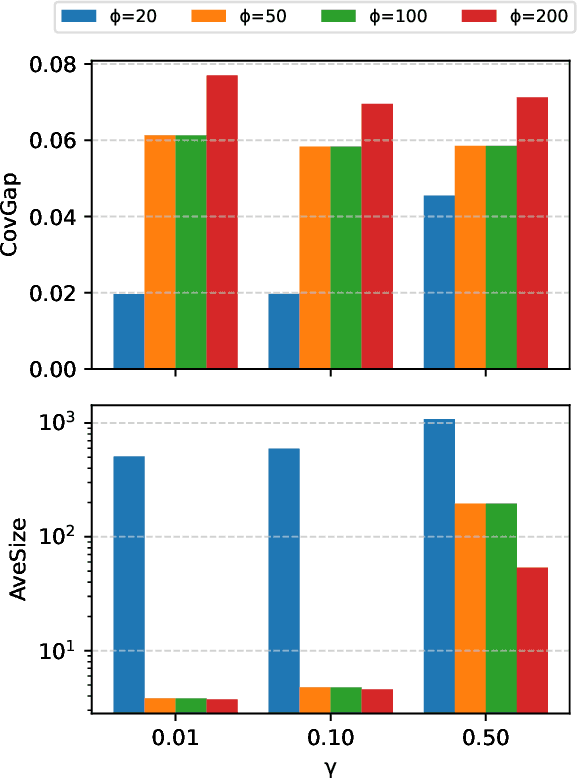
Uncertainty quantification in Knowledge Graph Embedding (KGE) methods is crucial for ensuring the reliability of downstream applications. A recent work applies conformal prediction to KGE methods, providing uncertainty estimates by generating a set of answers that is guaranteed to include the true answer with a predefined confidence level. However, existing methods provide probabilistic guarantees averaged over a reference set of queries and answers (marginal coverage guarantee). In high-stakes applications such as medical diagnosis, a stronger guarantee is often required: the predicted sets must provide consistent coverage per query (conditional coverage guarantee). We propose CondKGCP, a novel method that approximates predicate-conditional coverage guarantees while maintaining compact prediction sets. CondKGCP merges predicates with similar vector representations and augments calibration with rank information. We prove the theoretical guarantees and demonstrate empirical effectiveness of CondKGCP by comprehensive evaluations.
DAGE: DAG Query Answering via Relational Combinator with Logical Constraints
Oct 29, 2024Predicting answers to queries over knowledge graphs is called a complex reasoning task because answering a query requires subdividing it into subqueries. Existing query embedding methods use this decomposition to compute the embedding of a query as the combination of the embedding of the subqueries. This requirement limits the answerable queries to queries having a single free variable and being decomposable, which are called tree-form queries and correspond to the $\mathcal{SROI}^-$ description logic. In this paper, we define a more general set of queries, called DAG queries and formulated in the $\mathcal{ALCOIR}$ description logic, propose a query embedding method for them, called DAGE, and a new benchmark to evaluate query embeddings on them. Given the computational graph of a DAG query, DAGE combines the possibly multiple paths between two nodes into a single path with a trainable operator that represents the intersection of relations and learns DAG-DL from tautologies. We show that it is possible to implement DAGE on top of existing query embedding methods, and we empirically measure the improvement of our method over the results of vanilla methods evaluated in tree-form queries that approximate the DAG queries of our proposed benchmark.
eSPARQL: Representing and Reconciling Agnostic and Atheistic Beliefs in RDF-star Knowledge Graphs
Aug 01, 2024Over the past few years, we have seen the emergence of large knowledge graphs combining information from multiple sources. Sometimes, this information is provided in the form of assertions about other assertions, defining contexts where assertions are valid. A recent extension to RDF which admits statements over statements, called RDF-star, is in revision to become a W3C standard. However, there is no proposal for a semantics of these RDF-star statements nor a built-in facility to operate over them. In this paper, we propose a query language for epistemic RDF-star metadata based on a four-valued logic, called eSPARQL. Our proposed query language extends SPARQL-star, the query language for RDF-star, with a new type of FROM clause to facilitate operating with multiple and sometimes conflicting beliefs. We show that the proposed query language can express four use case queries, including the following features: (i) querying the belief of an individual, (ii) the aggregating of beliefs, (iii) querying who is conflicting with somebody, and (iv) beliefs about beliefs (i.e., nesting of beliefs).
From Shapes to Shapes: Inferring SHACL Shapes for Results of SPARQL CONSTRUCT Queries
Feb 13, 2024
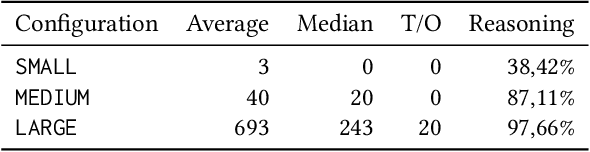
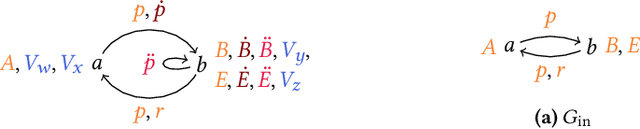
SPARQL CONSTRUCT queries allow for the specification of data processing pipelines that transform given input graphs into new output graphs. It is now common to constrain graphs through SHACL shapes allowing users to understand which data they can expect and which not. However, it becomes challenging to understand what graph data can be expected at the end of a data processing pipeline without knowing the particular input data: Shape constraints on the input graph may affect the output graph, but may no longer apply literally, and new shapes may be imposed by the query template. In this paper, we study the derivation of shape constraints that hold on all possible output graphs of a given SPARQL CONSTRUCT query. We assume that the SPARQL CONSTRUCT query is fixed, e.g., being part of a program, whereas the input graphs adhere to input shape constraints but may otherwise vary over time and, thus, are mostly unknown. We study a fragment of SPARQL CONSTRUCT queries (SCCQ) and a fragment of SHACL (Simple SHACL). We formally define the problem of deriving the most restrictive set of Simple SHACL shapes that constrain the results from evaluating a SCCQ over any input graph restricted by a given set of Simple SHACL shapes. We propose and implement an algorithm that statically analyses input SHACL shapes and CONSTRUCT queries and prove its soundness and complexity.
Link Prediction with Attention Applied on Multiple Knowledge Graph Embedding Models
Feb 13, 2023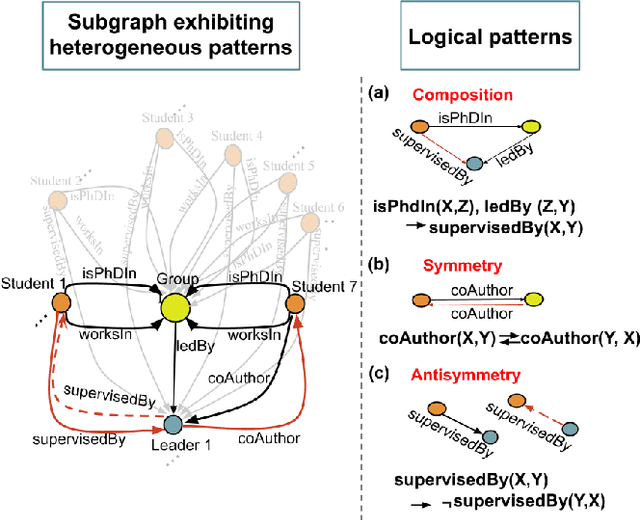

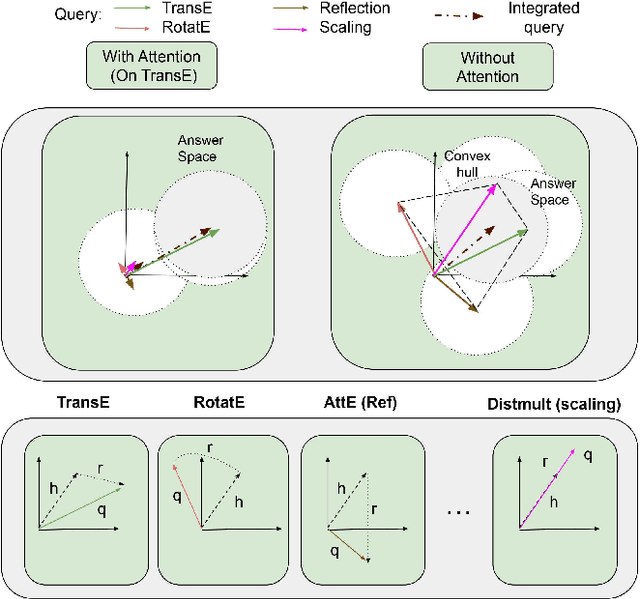
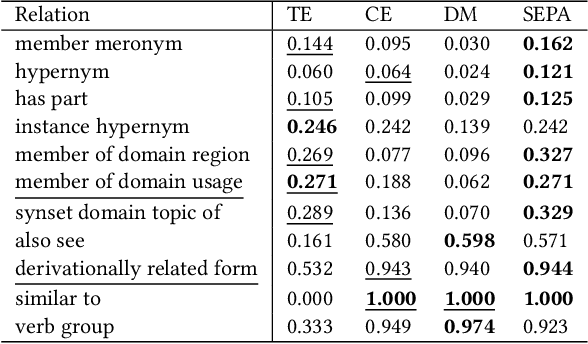
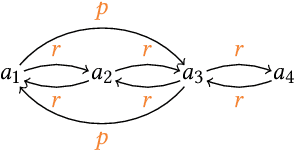
Predicting missing links between entities in a knowledge graph is a fundamental task to deal with the incompleteness of data on the Web. Knowledge graph embeddings map nodes into a vector space to predict new links, scoring them according to geometric criteria. Relations in the graph may follow patterns that can be learned, e.g., some relations might be symmetric and others might be hierarchical. However, the learning capability of different embedding models varies for each pattern and, so far, no single model can learn all patterns equally well. In this paper, we combine the query representations from several models in a unified one to incorporate patterns that are independently captured by each model. Our combination uses attention to select the most suitable model to answer each query. The models are also mapped onto a non-Euclidean manifold, the Poincar\'e ball, to capture structural patterns, such as hierarchies, besides relational patterns, such as symmetry. We prove that our combination provides a higher expressiveness and inference power than each model on its own. As a result, the combined model can learn relational and structural patterns. We conduct extensive experimental analysis with various link prediction benchmarks showing that the combined model outperforms individual models, including state-of-the-art approaches.