 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Evolve: A Self-Improving Framework for Multi-Agent Systems via Textual Parameter Graph Optimization
Apr 22, 2026Designing and optimizing multi-agent systems (MAS) is a complex, labor-intensive process of "Agent Engineering." Existing automatic optimization methods, primarily focused on flat prompt tuning, lack the structural awareness to debug the intricate web of interactions in MAS. More critically, these optimizers are static; they do not learn from experience to improve their own optimization strategies. To address these gaps, we introduce Textual Parameter Graph Optimization (TPGO), a framework that enables a multi-agent system to learn to evolve. TPGO first models the MAS as a Textual Parameter Graph (TPG), where agents, tools, and workflows are modular, optimizable nodes. To guide evolution, we derive "textual gradients," structured natural language feedback from execution traces, to pinpoint failures and suggest granular modifications. The core of our framework is Group Relative Agent Optimization (GRAO), a novel meta-learning strategy that learns from historical optimization experiences. By analyzing past successes and failures, GRAO becomes progressively better at proposing effective updates, allowing the system to learn how to optimize itself. Extensive experiments on complex benchmarks like GAIA and MCP-Universe show that TPGO significantly enhances the performance of state-of-the-art agent frameworks, achieving higher success rates through automated, self-improving optimization.
SpaceMind: A Modular and Self-Evolving Embodied Vision-Language Agent Framework for Autonomous On-orbit Servicing
Apr 15, 2026Autonomous on-orbit servicing demands embodied agents that perceive through visual sensors, reason about 3D spatial situations, and execute multi-phase tasks over extended horizons. We present SpaceMind, a modular and self-evolving vision-language model (VLM) agent framework that decomposes knowledge, tools, and reasoning into three independently extensible dimensions: skill modules with dynamic routing, Model Context Protocol (MCP) tools with configurable profiles, and injectable reasoning-mode skills. An MCP-Redis interface layer enables the same codebase to operate across simulation and physical hardware without modification, and a Skill Self-Evolution mechanism distills operational experience into persistent skill files without model fine-tuning. We validate SpaceMind through 192 closed-loop runs across five satellites, three task types, and two environments, a UE5 simulation and a physical laboratory, deliberately including degraded conditions to stress-test robustness. Under nominal conditions all modes achieve 90--100% navigation success; under degradation, the Prospective mode uniquely succeeds in search-and-approach tasks where other modes fail. A self-evolution study shows that the agent recovers from failure in four of six groups from a single failed episode, including complete failure to 100% success and inspection scores improving from 12 to 59 out of 100. Real-world validation confirms zero-code-modification transfer to a physical robot with 100% rendezvous success. Code: https://github.com/wuaodi/SpaceMind
Beyond Monologue: Interactive Talking-Listening Avatar Generation with Conversational Audio Context-Aware Kernels
Apr 11, 2026Audio-driven human video generation has achieved remarkable success in monologue scenarios, largely driven by advancements in powerful video generation foundation models. Moving beyond monologues, authentic human communication is inherently a full-duplex interactive process, requiring virtual agents not only to articulate their own speech but also to react naturally to incoming conversational audio. Most existing methods simply extend conventional audio-driven paradigms to listening scenarios. However, relying on strict frame-to-frame alignment renders the model's response to long-range conversational dynamics rigid, whereas directly introducing global attention catastrophically degrades lip synchronization. Recognizing the unique temporal Scale Discrepancy between talking and listening behaviors, we introduce a multi-head Gaussian kernel to explicitly inject this physical intuition into the model as a progressive temporal inductive bias. Building upon this, we construct a full-duplex interactive virtual agent capable of simultaneously processing dual-stream audio inputs for both talking and listening. Furthermore, we introduce a rigorously cleaned Talking-Listening dataset VoxHear featuring perfectly decoupled speech and background audio tracks. Extensive experiments demonstrate that our approach successfully fuses strong temporal alignment with deep contextual semantics, setting a new state-of-the-art for generating highly natural and responsive full-duplex interactive digital humans. The project page is available at https://warmcongee.github.io/beyond-monologue/ .
EARTalking: End-to-end GPT-style Autoregressive Talking Head Synthesis with Frame-wise Control
Mar 19, 2026Audio-driven talking head generation aims to create vivid and realistic videos from a static portrait and speech. Existing AR-based methods rely on intermediate facial representations, which limit their expressiveness and realism. Meanwhile, diffusion-based methods generate clip-by-clip, lacking fine-grained control and causing inherent latency due to overall denoising across the window. To address these limitations, we propose EARTalking, a novel end-to-end, GPT-style autoregressive model for interactive audio-driven talking head generation. Our method introduces a novel frame-by-frame, in-context, audio-driven streaming generation paradigm. For inherently supporting variable-length video generation with identity consistency, we propose the Sink Frame Window Attention (SFA) mechanism. Furthermore, to avoid the complex, separate networks that prior works required for diverse control signals, we propose a streaming Frame Condition In-Context (FCIC) scheme. This scheme efficiently injects diverse control signals in a streaming, in-context manner, enabling interactive control at every frame and at arbitrary moments. Experiments demonstrate that EARTalking outperforms existing autoregressive methods and achieves performance comparable to diffusion-based methods. Our work demonstrates the feasibility of in-context streaming autoregressive control, unlocking a scalable direction for flexible, efficient generation. The code will be released for reproducibility.
REST: Diffusion-based Real-time End-to-end Streaming Talking Head Generation via ID-Context Caching and Asynchronous Streaming Distillation
Dec 12, 2025Diffusion models have significantly advanced the field of talking head generation. However, the slow inference speeds and non-autoregressive paradigms severely constrain the application of diffusion-based THG models. In this study, we propose REST, the first diffusion-based, real-time, end-to-end streaming audio-driven talking head generation framework. To support real-time end-to-end generation, a compact video latent space is first learned through high spatiotemporal VAE compression. Additionally, to enable autoregressive streaming within the compact video latent space, we introduce an ID-Context Cache mechanism, which integrates ID-Sink and Context-Cache principles to key-value caching for maintaining temporal consistency and identity coherence during long-time streaming generation. Furthermore, an Asynchronous Streaming Distillation (ASD) training strategy is proposed to mitigate error accumulation in autoregressive generation and enhance temporal consistency, which leverages a non-streaming teacher with an asynchronous noise schedule to supervise the training of the streaming student model. REST bridges the gap between autoregressive and diffusion-based approaches, demonstrating substantial value for applications requiring real-time talking head generation. Experimental results demonstrate that REST outperforms state-of-the-art methods in both generation speed and overall performance.
Improving Swimming Performance in Soft Robotic Fish with Distributed Muscles and Embedded Kinematic Sensing
Apr 15, 2025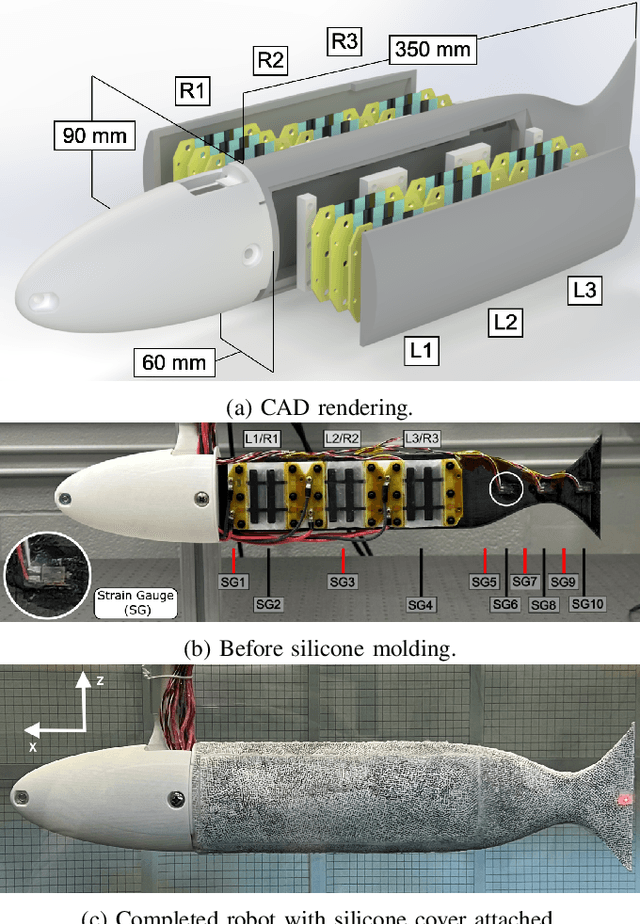

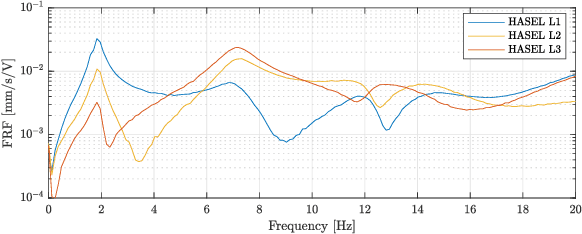
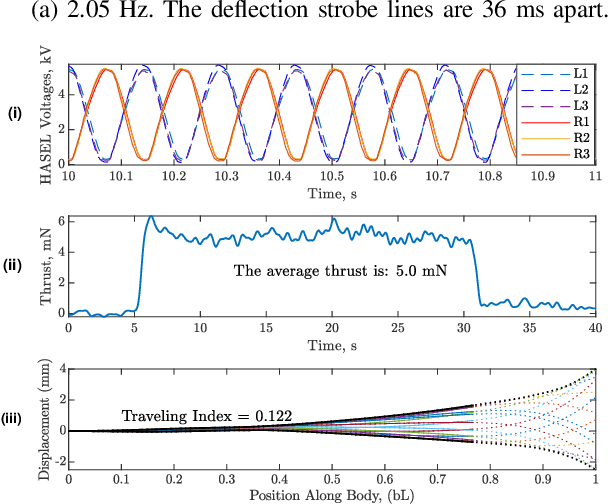
Bio-inspired underwater vehicles could yield improved efficiency, maneuverability, and environmental compatibility over conventional propeller-driven underwater vehicles. However, to realize the swimming performance of biology, there is a need for soft robotic swimmers with both distributed muscles and kinematic feedback. This study presents the design and swimming performance of a soft robotic fish with independently controllable muscles and embedded kinematic sensing distributed along the body. The soft swimming robot consists of an interior flexible spine, three axially distributed sets of HASEL artificial muscles, embedded strain gauges, a streamlined silicone body, and off-board electronics. In a fixed configuration, the soft robot generates a maximum thrust of 7.9 mN when excited near its first resonant frequency (2 Hz) with synchronized antagonistic actuation of all muscles. When excited near its second resonant frequency (8 Hz), synchronized muscle actuation generates 5.0 mN of thrust. By introducing a sequential phase offset into the muscle actuation, the thrust at the second resonant frequency increases to 7.2 mN, a 44% increase from simple antagonistic activation. The sequential muscle activation improves the thrust by increasing 1) the tail-beat velocity and 2) traveling wave content in the swimming kinematics by four times. Further, the second resonant frequency (8 Hz) generates nearly as much thrust as the first resonance (2 Hz) while requiring only $\approx25$% of the tail displacement, indicating that higher resonant frequencies have benefits for swimming in confined environments where a smaller kinematic envelope is necessary. These results demonstrate the performance benefits of independently controllable muscles and distributed kinematic sensing, and this type of soft robotic swimmer provides a platform to address the open challenge of sensorimotor control.
MC-GRU:a Multi-Channel GRU network for generalized nonlinear structural response prediction across structures
Mar 10, 2025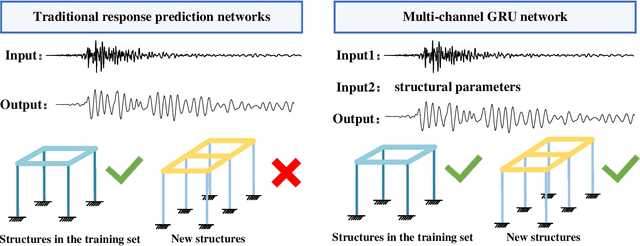
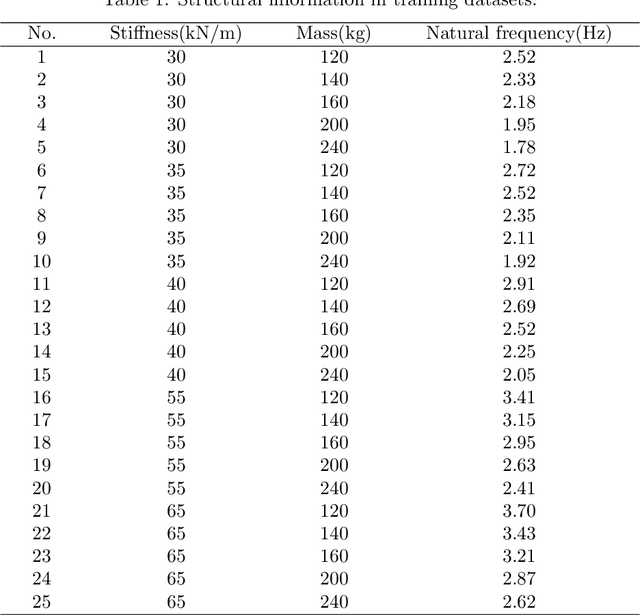
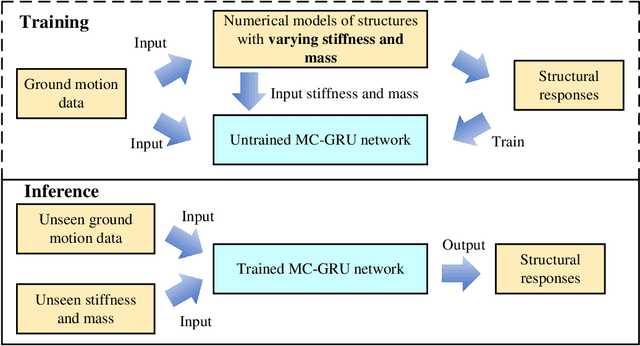
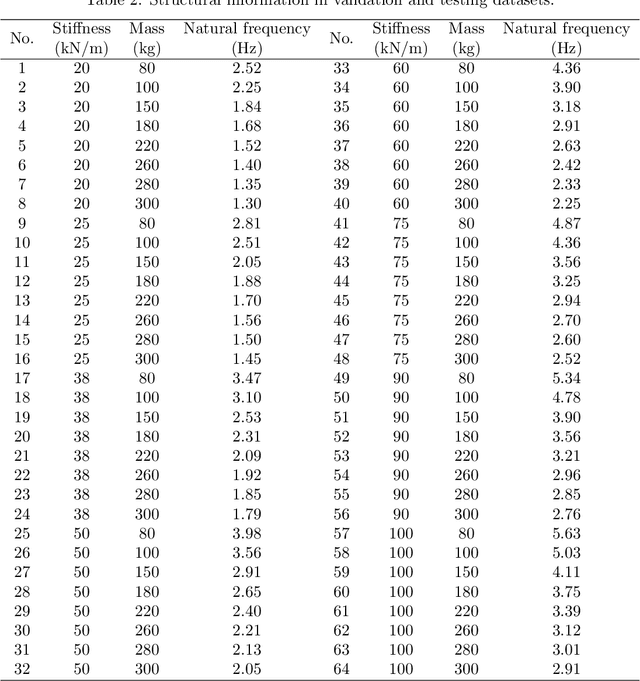
Accurate prediction of seismic responses and quantification of structural damage are critical in civil engineering. Traditional approaches such as finite element analysis could lack computational efficiency, especially for complex structural systems under extreme hazards. Recently, artificial intelligence has provided an alternative to efficiently model highly nonlinear behaviors. However, existing models face challenges in generalizing across diverse structural systems. This paper proposes a novel multi-channel gated recurrent unit (MC-GRU) network aimed at achieving generalized nonlinear structural response prediction for varying structures. The key concept lies in the integration of a multi-channel input mechanism to GRU with an extra input of structural information to the candidate hidden state, which enables the network to learn the dynamic characteristics of diverse structures and thus empower the generalizability and adaptiveness to unseen structures. The performance of the proposed MC-GRU is validated through a series of case studies, including a single-degree-of-freedom linear system, a hysteretic Bouc-Wen system, and a nonlinear reinforced concrete column from experimental testing. Results indicate that the proposed MC-GRU overcomes the major generalizability issues of existing methods, with capability of accurately inferring seismic responses of varying structures. Additionally, it demonstrates enhanced capabilities in representing nonlinear structural dynamics compared to traditional models such as GRU and LSTM.
A Real-time Spatio-Temporal Trajectory Planner for Autonomous Vehicles with Semantic Graph Optimization
Feb 25, 2025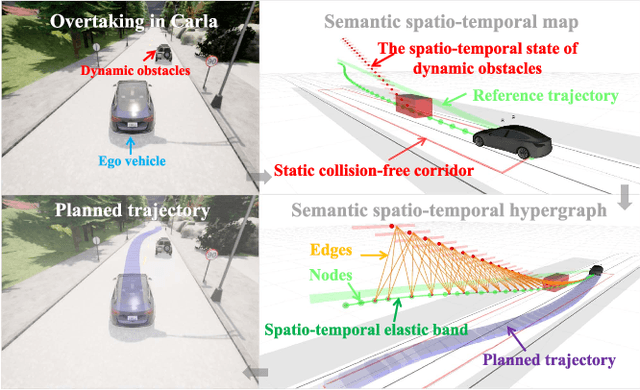
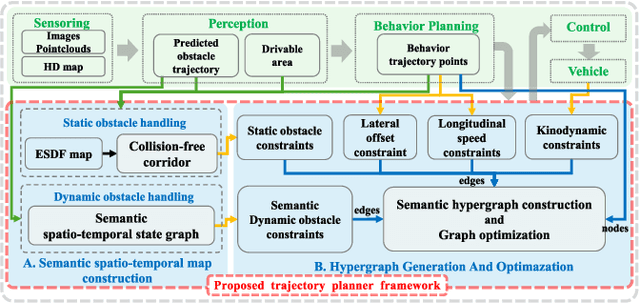
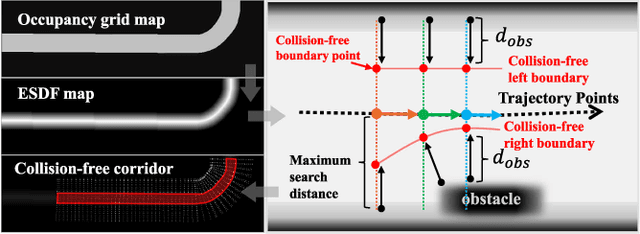
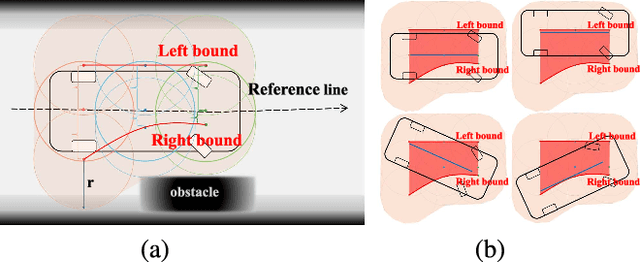
Planning a safe and feasible trajectory for autonomous vehicles in real-time by fully utilizing perceptual information in complex urban environments is challenging. In this paper, we propose a spatio-temporal trajectory planning method based on graph optimization. It efficiently extracts the multi-modal information of the perception module by constructing a semantic spatio-temporal map through separation processing of static and dynamic obstacles, and then quickly generates feasible trajectories via sparse graph optimization based on a semantic spatio-temporal hypergraph. Extensive experiments have proven that the proposed method can effectively handle complex urban public road scenarios and perform in real time. We will also release our codes to accommodate benchmarking for the research community
* This work has been accepted for publication in IEEE Robotics and Automation Letters (RA-L). The final published version is available in IEEE Xplore (DOI: 10.1109/LRA.2024.3504239)
PoAct: Policy and Action Dual-Control Agent for Generalized Applications
Jan 13, 2025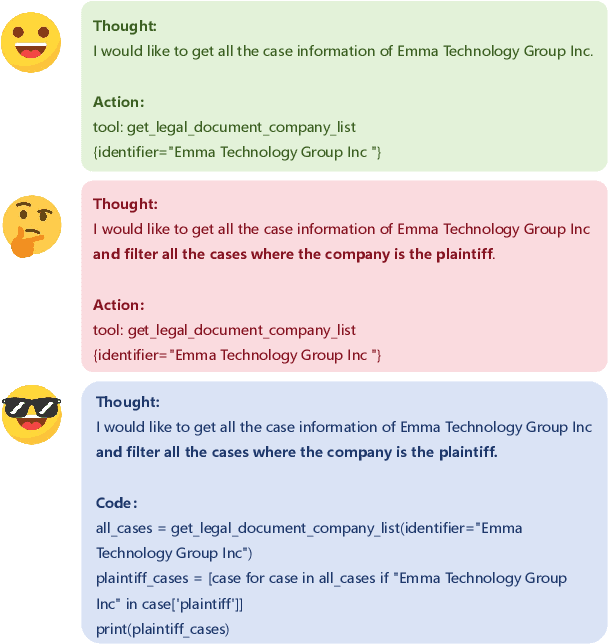



Based on their superior comprehension and reasoning capabilities, Large Language Model (LLM) driven agent frameworks have achieved significant success in numerous complex reasoning tasks. ReAct-like agents can solve various intricate problems step-by-step through progressive planning and tool calls, iteratively optimizing new steps based on environmental feedback. However, as the planning capabilities of LLMs improve, the actions invoked by tool calls in ReAct-like frameworks often misalign with complex planning and challenging data organization. Code Action addresses these issues while also introducing the challenges of a more complex action space and more difficult action organization. To leverage Code Action and tackle the challenges of its complexity, this paper proposes Policy and Action Dual-Control Agent (PoAct) for generalized applications. The aim is to achieve higher-quality code actions and more accurate reasoning paths by dynamically switching reasoning policies and modifying the action space. Experimental results on the Agent Benchmark for both legal and generic scenarios demonstrate the superior reasoning capabilities and reduced token consumption of our approach in complex tasks. On the LegalAgentBench, our method shows a 20 percent improvement over the baseline while requiring fewer tokens. We conducted experiments and analyses on the GPT-4o and GLM-4 series models, demonstrating the significant potential and scalability of our approach to solve complex problems.
EmotiveTalk: Expressive Talking Head Generation through Audio Information Decoupling and Emotional Video Diffusion
Nov 23, 2024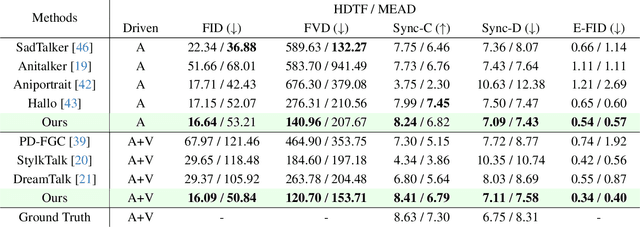
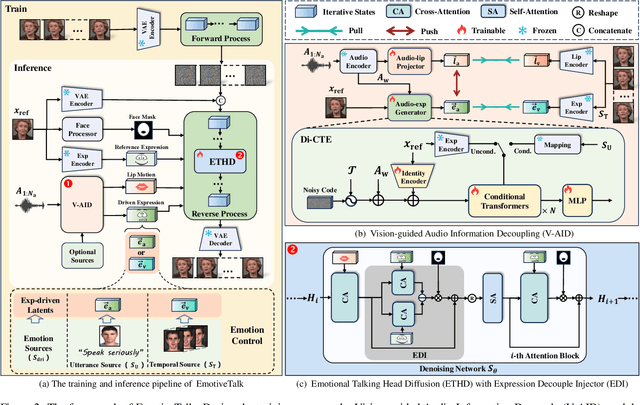
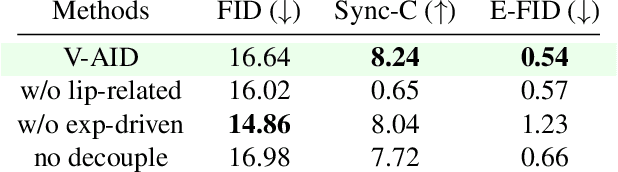

Diffusion models have revolutionized the field of talking head generation, yet still face challenges in expressiveness, controllability, and stability in long-time generation. In this research, we propose an EmotiveTalk framework to address these issues. Firstly, to realize better control over the generation of lip movement and facial expression, a Vision-guided Audio Information Decoupling (V-AID) approach is designed to generate audio-based decoupled representations aligned with lip movements and expression. Specifically, to achieve alignment between audio and facial expression representation spaces, we present a Diffusion-based Co-speech Temporal Expansion (Di-CTE) module within V-AID to generate expression-related representations under multi-source emotion condition constraints. Then we propose a well-designed Emotional Talking Head Diffusion (ETHD) backbone to efficiently generate highly expressive talking head videos, which contains an Expression Decoupling Injection (EDI) module to automatically decouple the expressions from reference portraits while integrating the target expression information, achieving more expressive generation performance. Experimental results show that EmotiveTalk can generate expressive talking head videos, ensuring the promised controllability of emotions and stability during long-time generation, yielding state-of-the-art performance compared to existing methods.