 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Faithful Explanations for Text Classification with Robustness Improvement and Explanation Guided Training
Paper and Code
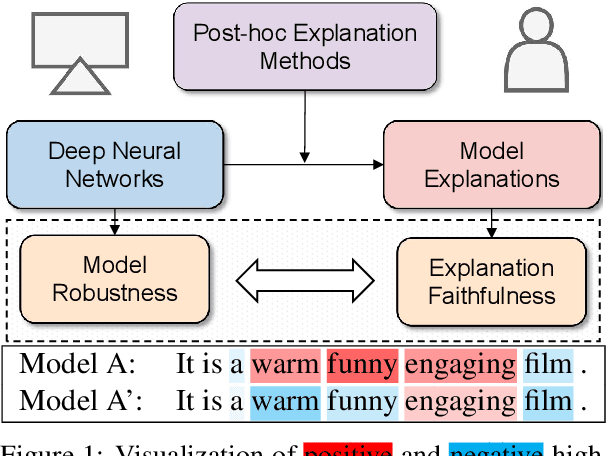
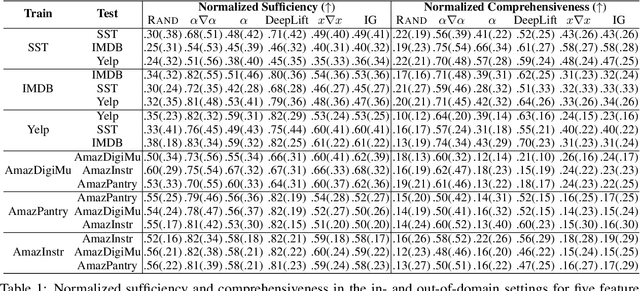
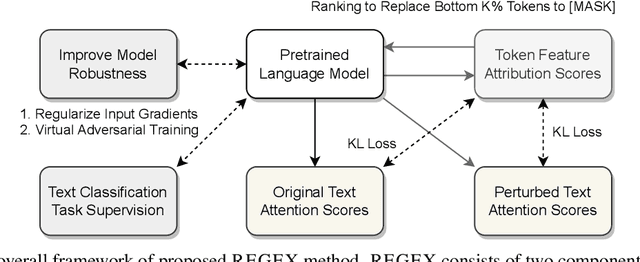
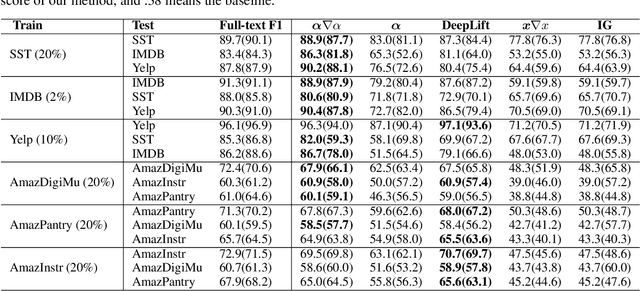
Feature attribution methods highlight the important input tokens as explanations to model predictions, which have been widely applied to deep neural networks towards trustworthy AI. However, recent works show that explanations provided by these methods face challenges of being faithful and robust. In this paper, we propose a method with Robustness improvement and Explanation Guided training towards more faithful EXplanations (REGEX) for text classification. First, we improve model robustness by input gradient regularization technique and virtual adversarial training. Secondly, we use salient ranking to mask noisy tokens and maximize the similarity between model attention and feature attribution, which can be seen as a self-training procedure without importing other external information. We conduct extensive experiments on six datasets with five attribution methods, and also evaluate the faithfulness in the out-of-domain setting. The results show that REGEX improves fidelity metrics of explanations in all settings and further achieves consistent gains based on two randomization tests. Moreover, we show that using highlight explanations produced by REGEX to train select-then-predict models results in comparable task performance to the end-to-end method.