 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Monologue: Interactive Talking-Listening Avatar Generation with Conversational Audio Context-Aware Kernels
Apr 11, 2026Audio-driven human video generation has achieved remarkable success in monologue scenarios, largely driven by advancements in powerful video generation foundation models. Moving beyond monologues, authentic human communication is inherently a full-duplex interactive process, requiring virtual agents not only to articulate their own speech but also to react naturally to incoming conversational audio. Most existing methods simply extend conventional audio-driven paradigms to listening scenarios. However, relying on strict frame-to-frame alignment renders the model's response to long-range conversational dynamics rigid, whereas directly introducing global attention catastrophically degrades lip synchronization. Recognizing the unique temporal Scale Discrepancy between talking and listening behaviors, we introduce a multi-head Gaussian kernel to explicitly inject this physical intuition into the model as a progressive temporal inductive bias. Building upon this, we construct a full-duplex interactive virtual agent capable of simultaneously processing dual-stream audio inputs for both talking and listening. Furthermore, we introduce a rigorously cleaned Talking-Listening dataset VoxHear featuring perfectly decoupled speech and background audio tracks. Extensive experiments demonstrate that our approach successfully fuses strong temporal alignment with deep contextual semantics, setting a new state-of-the-art for generating highly natural and responsive full-duplex interactive digital humans. The project page is available at https://warmcongee.github.io/beyond-monologue/ .
EARTalking: End-to-end GPT-style Autoregressive Talking Head Synthesis with Frame-wise Control
Mar 19, 2026Audio-driven talking head generation aims to create vivid and realistic videos from a static portrait and speech. Existing AR-based methods rely on intermediate facial representations, which limit their expressiveness and realism. Meanwhile, diffusion-based methods generate clip-by-clip, lacking fine-grained control and causing inherent latency due to overall denoising across the window. To address these limitations, we propose EARTalking, a novel end-to-end, GPT-style autoregressive model for interactive audio-driven talking head generation. Our method introduces a novel frame-by-frame, in-context, audio-driven streaming generation paradigm. For inherently supporting variable-length video generation with identity consistency, we propose the Sink Frame Window Attention (SFA) mechanism. Furthermore, to avoid the complex, separate networks that prior works required for diverse control signals, we propose a streaming Frame Condition In-Context (FCIC) scheme. This scheme efficiently injects diverse control signals in a streaming, in-context manner, enabling interactive control at every frame and at arbitrary moments. Experiments demonstrate that EARTalking outperforms existing autoregressive methods and achieves performance comparable to diffusion-based methods. Our work demonstrates the feasibility of in-context streaming autoregressive control, unlocking a scalable direction for flexible, efficient generation. The code will be released for reproducibility.
REST: Diffusion-based Real-time End-to-end Streaming Talking Head Generation via ID-Context Caching and Asynchronous Streaming Distillation
Dec 12, 2025Diffusion models have significantly advanced the field of talking head generation. However, the slow inference speeds and non-autoregressive paradigms severely constrain the application of diffusion-based THG models. In this study, we propose REST, the first diffusion-based, real-time, end-to-end streaming audio-driven talking head generation framework. To support real-time end-to-end generation, a compact video latent space is first learned through high spatiotemporal VAE compression. Additionally, to enable autoregressive streaming within the compact video latent space, we introduce an ID-Context Cache mechanism, which integrates ID-Sink and Context-Cache principles to key-value caching for maintaining temporal consistency and identity coherence during long-time streaming generation. Furthermore, an Asynchronous Streaming Distillation (ASD) training strategy is proposed to mitigate error accumulation in autoregressive generation and enhance temporal consistency, which leverages a non-streaming teacher with an asynchronous noise schedule to supervise the training of the streaming student model. REST bridges the gap between autoregressive and diffusion-based approaches, demonstrating substantial value for applications requiring real-time talking head generation. Experimental results demonstrate that REST outperforms state-of-the-art methods in both generation speed and overall performance.
EmotiveTalk: Expressive Talking Head Generation through Audio Information Decoupling and Emotional Video Diffusion
Nov 23, 2024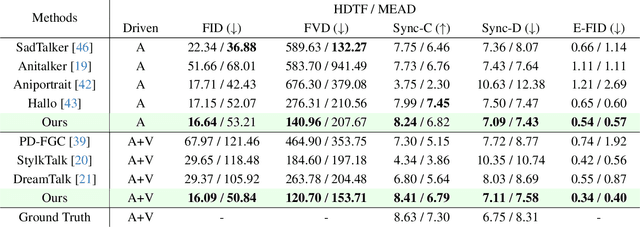
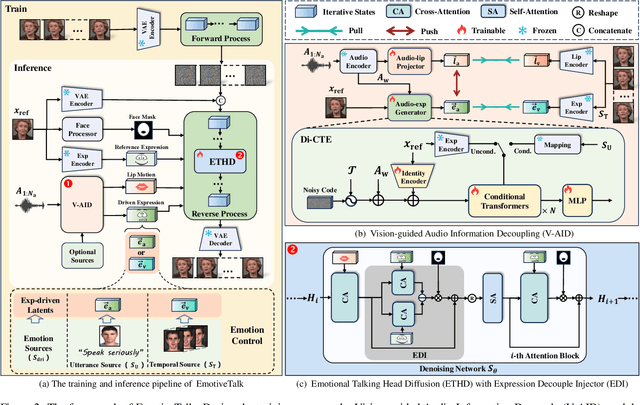
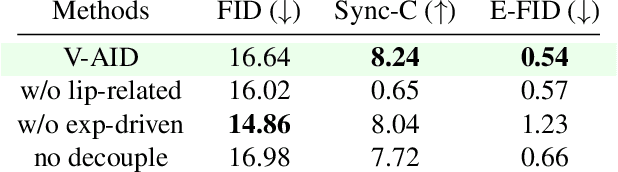

Diffusion models have revolutionized the field of talking head generation, yet still face challenges in expressiveness, controllability, and stability in long-time generation. In this research, we propose an EmotiveTalk framework to address these issues. Firstly, to realize better control over the generation of lip movement and facial expression, a Vision-guided Audio Information Decoupling (V-AID) approach is designed to generate audio-based decoupled representations aligned with lip movements and expression. Specifically, to achieve alignment between audio and facial expression representation spaces, we present a Diffusion-based Co-speech Temporal Expansion (Di-CTE) module within V-AID to generate expression-related representations under multi-source emotion condition constraints. Then we propose a well-designed Emotional Talking Head Diffusion (ETHD) backbone to efficiently generate highly expressive talking head videos, which contains an Expression Decoupling Injection (EDI) module to automatically decouple the expressions from reference portraits while integrating the target expression information, achieving more expressive generation performance. Experimental results show that EmotiveTalk can generate expressive talking head videos, ensuring the promised controllability of emotions and stability during long-time generation, yielding state-of-the-art performance compared to existing methods.
Enhancing Multimodal Sentiment Analysis for Missing Modality through Self-Distillation and Unified Modality Cross-Attention
Oct 19, 2024



In multimodal sentiment analysis, collecting text data is often more challenging than video or audio due to higher annotation costs and inconsistent automatic speech recognition (ASR) quality. To address this challenge, our study has developed a robust model that effectively integrates multimodal sentiment information, even in the absence of text modality. Specifically, we have developed a Double-Flow Self-Distillation Framework, including Unified Modality Cross-Attention (UMCA) and Modality Imagination Autoencoder (MIA), which excels at processing both scenarios with complete modalities and those with missing text modality. In detail, when the text modality is missing, our framework uses the LLM-based model to simulate the text representation from the audio modality, while the MIA module supplements information from the other two modalities to make the simulated text representation similar to the real text representation. To further align the simulated and real representations, and to enable the model to capture the continuous nature of sample orders in sentiment valence regression tasks, we have also introduced the Rank-N Contrast (RNC) loss function. When testing on the CMU-MOSEI, our model achieved outstanding performance on MAE and significantly outperformed other models when text modality is missing. The code is available at: https://github.com/WarmCongee/SDUMC
Hierarchical Audio-Visual Information Fusion with Multi-label Joint Decoding for MER 2023
Sep 11, 2023



In this paper, we propose a novel framework for recognizing both discrete and dimensional emotions. In our framework, deep features extracted from foundation models are used as robust acoustic and visual representations of raw video. Three different structures based on attention-guided feature gathering (AFG) are designed for deep feature fusion. Then, we introduce a joint decoding structure for emotion classification and valence regression in the decoding stage. A multi-task loss based on uncertainty is also designed to optimize the whole process. Finally, by combining three different structures on the posterior probability level, we obtain the final predictions of discrete and dimensional emotions. When tested on the dataset of multimodal emotion recognition challenge (MER 2023), the proposed framework yields consistent improvements in both emotion classification and valence regression. Our final system achieves state-of-the-art performance and ranks third on the leaderboard on MER-MULTI sub-challenge.
* 5 pages, 4 figures