 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM-Based Agents via Global Planning and Hierarchical Execution
Apr 23, 2025Intelligent agent systems based on Large Language Models (LLMs) have shown great potential in real-world applications. However, existing agent frameworks still face critical limitations in task planning and execution, restricting their effectiveness and generalizability. Specifically, current planning methods often lack clear global goals, leading agents to get stuck in local branches, or produce non-executable plans. Meanwhile, existing execution mechanisms struggle to balance complexity and stability, and their limited action space restricts their ability to handle diverse real-world tasks. To address these limitations, we propose GoalAct, a novel agent framework that introduces a continuously updated global planning mechanism and integrates a hierarchical execution strategy. GoalAct decomposes task execution into high-level skills, including searching, coding, writing and more, thereby reducing planning complexity while enhancing the agents' adaptability across diverse task scenarios. We evaluate GoalAct on LegalAgentBench, a benchmark with multiple types of legal tasks that require the use of multiple types of tools. Experimental results demonstrate that GoalAct achieves state-of-the-art (SOTA) performance, with an average improvement of 12.22% in success rate. These findings highlight GoalAct's potential to drive the development of more advanced intelligent agent systems, making them more effective across complex real-world applications. Our code can be found at https://github.com/cjj826/GoalAct.
PoAct: Policy and Action Dual-Control Agent for Generalized Applications
Jan 13, 2025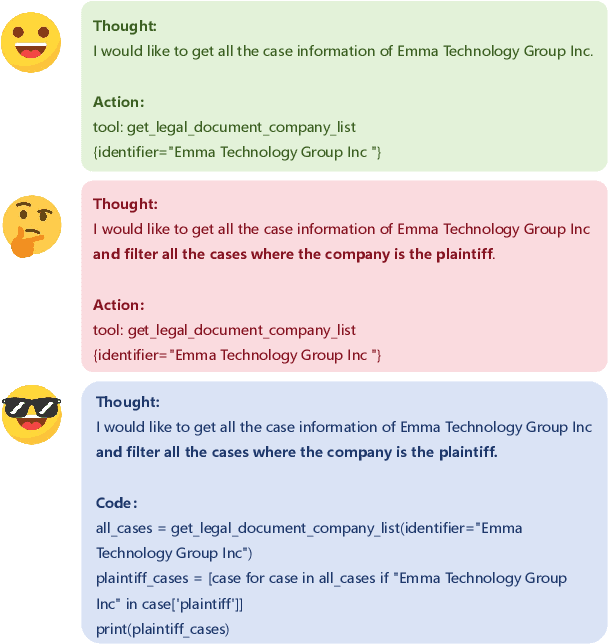



Based on their superior comprehension and reasoning capabilities, Large Language Model (LLM) driven agent frameworks have achieved significant success in numerous complex reasoning tasks. ReAct-like agents can solve various intricate problems step-by-step through progressive planning and tool calls, iteratively optimizing new steps based on environmental feedback. However, as the planning capabilities of LLMs improve, the actions invoked by tool calls in ReAct-like frameworks often misalign with complex planning and challenging data organization. Code Action addresses these issues while also introducing the challenges of a more complex action space and more difficult action organization. To leverage Code Action and tackle the challenges of its complexity, this paper proposes Policy and Action Dual-Control Agent (PoAct) for generalized applications. The aim is to achieve higher-quality code actions and more accurate reasoning paths by dynamically switching reasoning policies and modifying the action space. Experimental results on the Agent Benchmark for both legal and generic scenarios demonstrate the superior reasoning capabilities and reduced token consumption of our approach in complex tasks. On the LegalAgentBench, our method shows a 20 percent improvement over the baseline while requiring fewer tokens. We conducted experiments and analyses on the GPT-4o and GLM-4 series models, demonstrating the significant potential and scalability of our approach to solve complex problems.
LegalAgentBench: Evaluating LLM Agents in Legal Domain
Dec 23, 2024With the increasing intelligence and autonomy of LLM agents, their potential applications in the legal domain are becoming increasingly apparent. However, existing general-domain benchmarks cannot fully capture the complexity and subtle nuances of real-world judicial cognition and decision-making. Therefore, we propose LegalAgentBench, a comprehensive benchmark specifically designed to evaluate LLM Agents in the Chinese legal domain. LegalAgentBench includes 17 corpora from real-world legal scenarios and provides 37 tools for interacting with external knowledge. We designed a scalable task construction framework and carefully annotated 300 tasks. These tasks span various types, including multi-hop reasoning and writing, and range across different difficulty levels, effectively reflecting the complexity of real-world legal scenarios. Moreover, beyond evaluating final success, LegalAgentBench incorporates keyword analysis during intermediate processes to calculate progress rates, enabling more fine-grained evaluation. We evaluated eight popular LLMs, highlighting the strengths, limitations, and potential areas for improvement of existing models and methods. LegalAgentBench sets a new benchmark for the practical application of LLMs in the legal domain, with its code and data available at \url{https://github.com/CSHaitao/LegalAgentBench}.