 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCivil Court Simulation with Large Language Models
Jun 08, 2026Court simulation bridges legal education and judicial practice, yet human-based simulations are costly and difficult to scale. Large language models (LLMs) offer a scalable alternative, but existing court-simulation research mainly focuses on criminal cases. Civil litigation is more common in practice and harder to simulate because its claims, liability, and remedies are more flexible. We present a multi-agent court simulation framework for Chinese civil cases. The framework organizes role-based interaction through a five-stage civil trial procedure and integrates memory module and statute retrieval to support long-process adjudication. Experiments show that the framework produces reliable civil judgments, with clear strengths in liability allocation and multi-item adjudication. Further experiments show that memory quality substantially affects downstream simulation quality. Through a five-layer factor framework, we analyze how legal grounding, information conditions, judicial capability and role orientation, organizational pressure, and social context affect the framework's reliability and behavior. These results support the effectiveness of the proposed framework for civil court simulation. The dataset and code are available at: https://github.com/foggpoy/Civil-Court.
LexRubric: A Rubric-Guided Diagnostic Benchmark for Open-Ended Legal Tasks
Jun 08, 2026As large language models (LLMs) are increasingly applied to real-world legal tasks, evaluating the reliability of their open-ended legal responses has become essential. These tasks require context-sensitive answers and allow little room for error, motivating fine-grained and diagnostic evaluation that can identify specific sources of response quality failures. We introduce LexRubric, a rubric-based benchmark for evaluating open-ended Chinese legal tasks. LexRubric contains 649 instances from legal consultation and judicial examination, which reflect both everyday legal needs and professional legal reasoning and cover 14 legal scenarios. It further includes 12,337 expert-written atomic scoring criteria organized under a unified six-dimensional framework, enabling accurate evaluation and diagnostic analysis across tasks and evaluation dimensions. To validate the reliability of the evaluation, we test multiple judge models and compare model-based judgments with human judgments. We further evaluate 18 recent general and legal-domain LLMs on LexRubric. Results show that different models exhibit distinct capability profiles, and that open-ended legal question remains challenging for current LLMs. Data is available at: https://github.com/foggpoy/LexRubric.
Enhancing Judgment Document Generation via Agentic Legal Information Collection and Rubric-Guided Optimization
May 03, 2026Automating the drafting of judgment documents is pivotal to judicial efficiency, yet it remains challenging due to the dual requirements of comprehensive retrieval of legal information and rigorous logical reasoning. Existing approaches, typically relying on standard Retrieval-Augmented Generation and Supervised Fine-Tuning, often suffer from insufficient evidence recall, hallucinated statutory references, and logically flawed legal reasoning. To bridge this gap, we propose Judge-R1, a unified framework designed to enhance LLM-based judgment document generation by jointly improving legal information collection and judgment document generation. First, we introduce Agentic Legal Information Collection, which employs a dynamic planning agent to retrieve precise statutes and precedents from multiple sources. Second, we implement Rubric-Guided Optimization, a reinforcement learning phase utilizing Group Relative Policy Optimization (GRPO) with a comprehensive legal reward function to enforce adherence to judicial standards and reasoning logic. Extensive experiments on the JuDGE benchmark demonstrate that Judge-R1 significantly outperforms state-of-the-art baselines in both legal accuracy and generation quality.
LegalOne: A Family of Foundation Models for Reliable Legal Reasoning
Feb 03, 2026While Large Language Models (LLMs) have demonstrated impressive general capabilities, their direct application in the legal domain is often hindered by a lack of precise domain knowledge and complexity of performing rigorous multi-step judicial reasoning. To address this gap, we present LegalOne, a family of foundational models specifically tailored for the Chinese legal domain. LegalOne is developed through a comprehensive three-phase pipeline designed to master legal reasoning. First, during mid-training phase, we propose Plasticity-Adjusted Sampling (PAS) to address the challenge of domain adaptation. This perplexity-based scheduler strikes a balance between the acquisition of new knowledge and the retention of original capabilities, effectively establishing a robust legal foundation. Second, during supervised fine-tuning, we employ Legal Agentic CoT Distillation (LEAD) to distill explicit reasoning from raw legal texts. Unlike naive distillation, LEAD utilizes an agentic workflow to convert complex judicial processes into structured reasoning trajectories, thereby enforcing factual grounding and logical rigor. Finally, we implement a Curriculum Reinforcement Learning (RL) strategy. Through a progressive reinforcement process spanning memorization, understanding, and reasoning, LegalOne evolves from simple pattern matching to autonomous and reliable legal reasoning. Experimental results demonstrate that LegalOne achieves state-of-the-art performance across a wide range of legal tasks, surpassing general-purpose LLMs with vastly larger parameter counts through enhanced knowledge density and efficiency. We publicly release the LegalOne weights and the LegalKit evaluation framework to advance the field of Legal AI, paving the way for deploying trustworthy and interpretable foundation models in high-stakes judicial applications.
Chinese Court Simulation with LLM-Based Agent System
Aug 24, 2025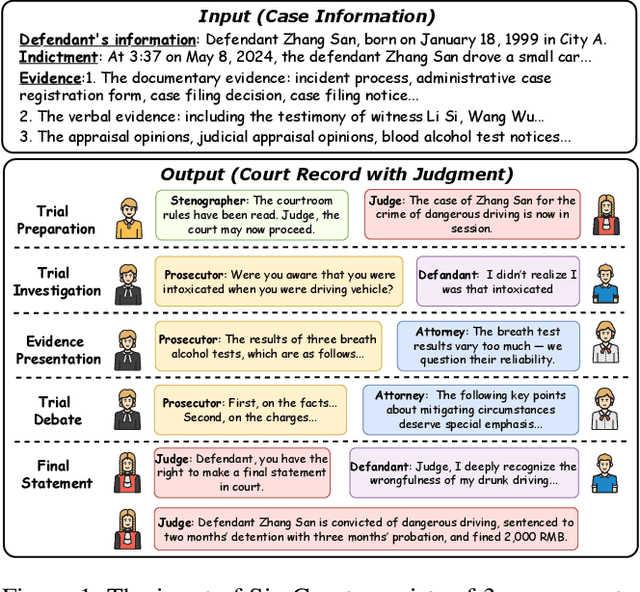

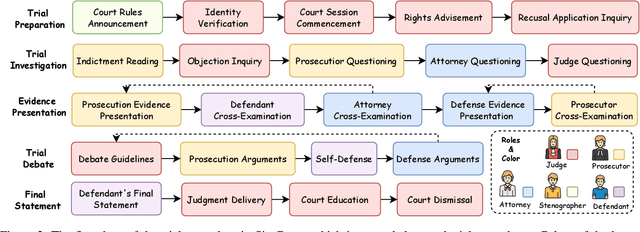

Mock trial has long served as an important platform for legal professional training and education. It not only helps students learn about realistic trial procedures, but also provides practical value for case analysis and judgment prediction. Traditional mock trials are difficult to access by the public because they rely on professional tutors and human participants. Fortunately, the rise of large language models (LLMs) provides new opportunities for creating more accessible and scalable court simulations. While promising, existing research mainly focuses on agent construction while ignoring the systematic design and evaluation of court simulations, which are actually more important for the credibility and usage of court simulation in practice. To this end, we present the first court simulation framework -- SimCourt -- based on the real-world procedure structure of Chinese courts. Our framework replicates all 5 core stages of a Chinese trial and incorporates 5 courtroom roles, faithfully following the procedural definitions in China. To simulate trial participants with different roles, we propose and craft legal agents equipped with memory, planning, and reflection abilities. Experiment on legal judgment prediction show that our framework can generate simulated trials that better guide the system to predict the imprisonment, probation, and fine of each case. Further annotations by human experts show that agents' responses under our simulation framework even outperformed judges and lawyers from the real trials in many scenarios. These further demonstrate the potential of LLM-based court simulation.
JuDGE: Benchmarking Judgment Document Generation for Chinese Legal System
Mar 20, 2025This paper introduces JuDGE (Judgment Document Generation Evaluation), a novel benchmark for evaluating the performance of judgment document generation in the Chinese legal system. We define the task as generating a complete legal judgment document from the given factual description of the case. To facilitate this benchmark, we construct a comprehensive dataset consisting of factual descriptions from real legal cases, paired with their corresponding full judgment documents, which serve as the ground truth for evaluating the quality of generated documents. This dataset is further augmented by two external legal corpora that provide additional legal knowledge for the task: one comprising statutes and regulations, and the other consisting of a large collection of past judgment documents. In collaboration with legal professionals, we establish a comprehensive automated evaluation framework to assess the quality of generated judgment documents across various dimensions. We evaluate various baseline approaches, including few-shot in-context learning, fine-tuning, and a multi-source retrieval-augmented generation (RAG) approach, using both general and legal-domain LLMs. The experimental results demonstrate that, while RAG approaches can effectively improve performance in this task, there is still substantial room for further improvement. All the codes and datasets are available at: https://github.com/oneal2000/JuDGE.
LexRAG: Benchmarking Retrieval-Augmented Generation in Multi-Turn Legal Consultation Conversation
Feb 28, 2025Retrieval-augmented generation (RAG) has proven highly effective in improving large language models (LLMs) across various domains. However, there is no benchmark specifically designed to assess the effectiveness of RAG in the legal domain, which restricts progress in this area. To fill this gap, we propose LexRAG, the first benchmark to evaluate RAG systems for multi-turn legal consultations. LexRAG consists of 1,013 multi-turn dialogue samples and 17,228 candidate legal articles. Each sample is annotated by legal experts and consists of five rounds of progressive questioning. LexRAG includes two key tasks: (1) Conversational knowledge retrieval, requiring accurate retrieval of relevant legal articles based on multi-turn context. (2) Response generation, focusing on producing legally sound answers. To ensure reliable reproducibility, we develop LexiT, a legal RAG toolkit that provides a comprehensive implementation of RAG system components tailored for the legal domain. Additionally, we introduce an LLM-as-a-judge evaluation pipeline to enable detailed and effective assessment. Through experimental analysis of various LLMs and retrieval methods, we reveal the key limitations of existing RAG systems in handling legal consultation conversations. LexRAG establishes a new benchmark for the practical application of RAG systems in the legal domain, with its code and data available at https://github.com/CSHaitao/LexRAG.
CaseGen: A Benchmark for Multi-Stage Legal Case Documents Generation
Feb 25, 2025



Legal case documents play a critical role in judicial proceedings. As the number of cases continues to rise, the reliance on manual drafting of legal case documents is facing increasing pressure and challenges. The development of large language models (LLMs) offers a promising solution for automating document generation. However, existing benchmarks fail to fully capture the complexities involved in drafting legal case documents in real-world scenarios. To address this gap, we introduce CaseGen, the benchmark for multi-stage legal case documents generation in the Chinese legal domain. CaseGen is based on 500 real case samples annotated by legal experts and covers seven essential case sections. It supports four key tasks: drafting defense statements, writing trial facts, composing legal reasoning, and generating judgment results. To the best of our knowledge, CaseGen is the first benchmark designed to evaluate LLMs in the context of legal case document generation. To ensure an accurate and comprehensive evaluation, we design the LLM-as-a-judge evaluation framework and validate its effectiveness through human annotations. We evaluate several widely used general-domain LLMs and legal-specific LLMs, highlighting their limitations in case document generation and pinpointing areas for potential improvement. This work marks a step toward a more effective framework for automating legal case documents drafting, paving the way for the reliable application of AI in the legal field. The dataset and code are publicly available at https://github.com/CSHaitao/CaseGen.
LegalAgentBench: Evaluating LLM Agents in Legal Domain
Dec 23, 2024With the increasing intelligence and autonomy of LLM agents, their potential applications in the legal domain are becoming increasingly apparent. However, existing general-domain benchmarks cannot fully capture the complexity and subtle nuances of real-world judicial cognition and decision-making. Therefore, we propose LegalAgentBench, a comprehensive benchmark specifically designed to evaluate LLM Agents in the Chinese legal domain. LegalAgentBench includes 17 corpora from real-world legal scenarios and provides 37 tools for interacting with external knowledge. We designed a scalable task construction framework and carefully annotated 300 tasks. These tasks span various types, including multi-hop reasoning and writing, and range across different difficulty levels, effectively reflecting the complexity of real-world legal scenarios. Moreover, beyond evaluating final success, LegalAgentBench incorporates keyword analysis during intermediate processes to calculate progress rates, enabling more fine-grained evaluation. We evaluated eight popular LLMs, highlighting the strengths, limitations, and potential areas for improvement of existing models and methods. LegalAgentBench sets a new benchmark for the practical application of LLMs in the legal domain, with its code and data available at \url{https://github.com/CSHaitao/LegalAgentBench}.
LexEval: A Comprehensive Chinese Legal Benchmark for Evaluating Large Language Models
Sep 30, 2024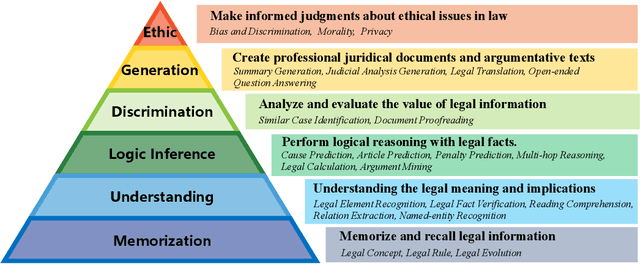



Large language models (LLMs) have made significant progress in natural language processing tasks and demonstrate considerable potential in the legal domain. However, legal applications demand high standards of accuracy, reliability, and fairness. Applying existing LLMs to legal systems without careful evaluation of their potential and limitations could pose significant risks in legal practice. To this end, we introduce a standardized comprehensive Chinese legal benchmark LexEval. This benchmark is notable in the following three aspects: (1) Ability Modeling: We propose a new taxonomy of legal cognitive abilities to organize different tasks. (2) Scale: To our knowledge, LexEval is currently the largest Chinese legal evaluation dataset, comprising 23 tasks and 14,150 questions. (3) Data: we utilize formatted existing datasets, exam datasets and newly annotated datasets by legal experts to comprehensively evaluate the various capabilities of LLMs. LexEval not only focuses on the ability of LLMs to apply fundamental legal knowledge but also dedicates efforts to examining the ethical issues involved in their application. We evaluated 38 open-source and commercial LLMs and obtained some interesting findings. The experiments and findings offer valuable insights into the challenges and potential solutions for developing Chinese legal systems and LLM evaluation pipelines. The LexEval dataset and leaderboard are publicly available at \url{https://github.com/CSHaitao/LexEval} and will be continuously updated.