 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove Large Language Model Systems with User Logs
Feb 06, 2026Scaling training data and model parameters has long driven progress in large language models (LLMs), but this paradigm is increasingly constrained by the scarcity of high-quality data and diminishing returns from rising computational costs. As a result, recent work is increasing the focus on continual learning from real-world deployment, where user interaction logs provide a rich source of authentic human feedback and procedural knowledge. However, learning from user logs is challenging due to their unstructured and noisy nature. Vanilla LLM systems often struggle to distinguish useful feedback signals from noisy user behavior, and the disparity between user log collection and model optimization (e.g., the off-policy optimization problem) further strengthens the problem. To this end, we propose UNO (User log-driveN Optimization), a unified framework for improving LLM systems (LLMsys) with user logs. UNO first distills logs into semi-structured rules and preference pairs, then employs query-and-feedback-driven clustering to manage data heterogeneity, and finally quantifies the cognitive gap between the model's prior knowledge and the log data. This assessment guides the LLMsys to adaptively filter out noisy feedback and construct different modules for primary and reflective experiences extracted from user logs, thereby improving future responses. Extensive experiments show that UNO achieves state-of-the-art effectiveness and efficiency, significantly outperforming Retrieval Augmented Generation (RAG) and memory-based baselines. We have open-sourced our code at https://github.com/bebr2/UNO .
Joint Evaluation of Answer and Reasoning Consistency for Hallucination Detection in Large Reasoning Models
Jun 05, 2025Large Reasoning Models (LRMs) extend large language models with explicit, multi-step reasoning traces to enhance transparency and performance on complex tasks. However, these reasoning traces can be redundant or logically inconsistent, making them a new source of hallucination that is difficult to detect. Existing hallucination detection methods focus primarily on answer-level uncertainty and often fail to detect hallucinations or logical inconsistencies arising from the model's reasoning trace. This oversight is particularly problematic for LRMs, where the explicit thinking trace is not only an important support to the model's decision-making process but also a key source of potential hallucination. To this end, we propose RACE (Reasoning and Answer Consistency Evaluation), a novel framework specifically tailored for hallucination detection in LRMs. RACE operates by extracting essential reasoning steps and computing four diagnostic signals: inter-sample consistency of reasoning traces, entropy-based answer uncertainty, semantic alignment between reasoning and answers, and internal coherence of reasoning. This joint analysis enables fine-grained hallucination detection even when the final answer appears correct. Experiments across datasets and different LLMs demonstrate that RACE outperforms existing hallucination detection baselines, offering a robust and generalizable solution for evaluating LRMs. Our code is available at: https://github.com/bebr2/RACE.
JuDGE: Benchmarking Judgment Document Generation for Chinese Legal System
Mar 20, 2025This paper introduces JuDGE (Judgment Document Generation Evaluation), a novel benchmark for evaluating the performance of judgment document generation in the Chinese legal system. We define the task as generating a complete legal judgment document from the given factual description of the case. To facilitate this benchmark, we construct a comprehensive dataset consisting of factual descriptions from real legal cases, paired with their corresponding full judgment documents, which serve as the ground truth for evaluating the quality of generated documents. This dataset is further augmented by two external legal corpora that provide additional legal knowledge for the task: one comprising statutes and regulations, and the other consisting of a large collection of past judgment documents. In collaboration with legal professionals, we establish a comprehensive automated evaluation framework to assess the quality of generated judgment documents across various dimensions. We evaluate various baseline approaches, including few-shot in-context learning, fine-tuning, and a multi-source retrieval-augmented generation (RAG) approach, using both general and legal-domain LLMs. The experimental results demonstrate that, while RAG approaches can effectively improve performance in this task, there is still substantial room for further improvement. All the codes and datasets are available at: https://github.com/oneal2000/JuDGE.
Parametric Retrieval Augmented Generation
Jan 27, 2025Retrieval-augmented generation (RAG) techniques have emerged as a promising solution to enhance the reliability of large language models (LLMs) by addressing issues like hallucinations, outdated knowledge, and domain adaptation. In particular, existing RAG methods append relevant documents retrieved from external corpus or databases to the input of LLMs to guide their generation process, which we refer to as the in-context knowledge injection method. While this approach is simple and often effective, it has inherent limitations. Firstly, increasing the context length and number of relevant documents can lead to higher computational overhead and degraded performance, especially in complex reasoning tasks. More importantly, in-context knowledge injection operates primarily at the input level, but LLMs store their internal knowledge in their parameters. This gap fundamentally limits the capacity of in-context methods. To this end, we introduce Parametric retrieval-augmented generation (Parametric RAG), a new RAG paradigm that integrates external knowledge directly into the parameters of feed-forward networks (FFN) of an LLM through document parameterization. This approach not only saves online computational costs by eliminating the need to inject multiple documents into the LLMs' input context, but also deepens the integration of external knowledge into the parametric knowledge space of the LLM. Experimental results demonstrate that Parametric RAG substantially enhances both the effectiveness and efficiency of knowledge augmentation in LLMs. Also, it can be combined with in-context RAG methods to achieve even better performance. We have open-sourced all the code, data, and models in the following anonymized GitHub link: https://github.com/oneal2000/PRAG
Knowledge Editing through Chain-of-Thought
Dec 23, 2024



Large Language Models (LLMs) have demonstrated exceptional capabilities across a wide range of natural language processing (NLP) tasks. However, keeping these models up-to-date with evolving world knowledge remains a significant challenge due to the high costs of frequent retraining. To address this challenge, knowledge editing techniques have emerged to update LLMs with new information without rebuilding the model from scratch. Among these, the in-context editing paradigm stands out for its effectiveness in integrating new knowledge while preserving the model's original capabilities. Despite its potential, existing in-context knowledge editing methods are often task-specific, focusing primarily on multi-hop QA tasks using structured knowledge triples. Moreover, their reliance on few-shot prompting for task decomposition makes them unstable and less effective in generalizing across diverse tasks. In response to these limitations, we propose EditCoT, a novel knowledge editing framework that flexibly and efficiently updates LLMs across various tasks without retraining. EditCoT works by generating a chain-of-thought (CoT) for a given input and then iteratively refining this CoT process using a CoT editor based on updated knowledge. We evaluate EditCoT across a diverse range of benchmarks, covering multiple languages and tasks. The results demonstrate that our approach achieves state-of-the-art performance while offering superior generalization, effectiveness, and stability compared to existing methods, marking a significant advancement in the field of knowledge updating. Code and data are available at: https://github.com/bebr2/EditCoT.
LeKUBE: A Legal Knowledge Update BEnchmark
Jul 19, 2024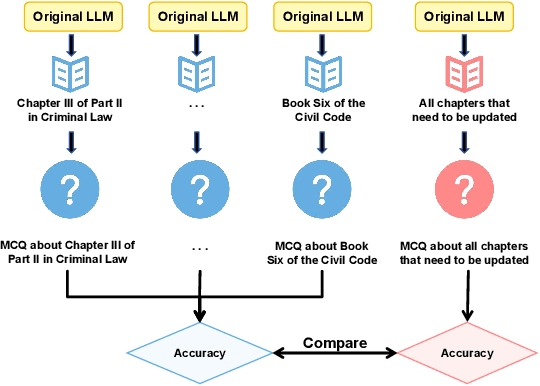
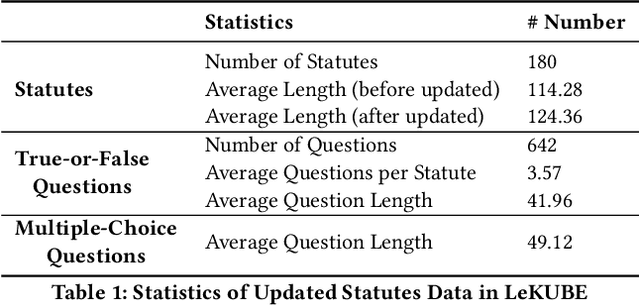
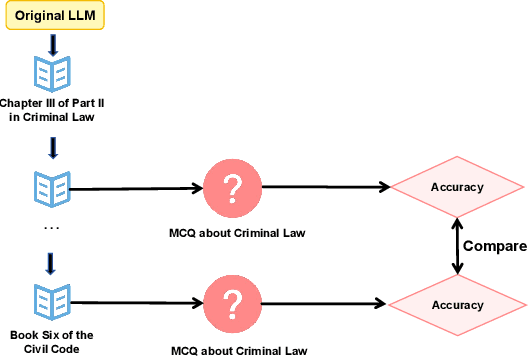
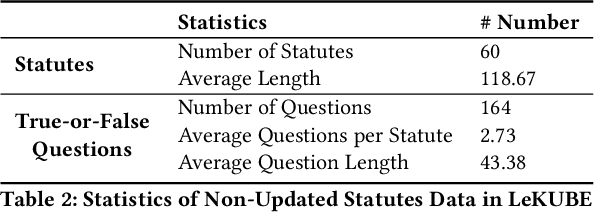
Recent advances in Large Language Models (LLMs) have significantly shaped the applications of AI in multiple fields, including the studies of legal intelligence. Trained on extensive legal texts, including statutes and legal documents, the legal LLMs can capture important legal knowledge/concepts effectively and provide important support for downstream legal applications such as legal consultancy. Yet, the dynamic nature of legal statutes and interpretations also poses new challenges to the use of LLMs in legal applications. Particularly, how to update the legal knowledge of LLMs effectively and efficiently has become an important research problem in practice. Existing benchmarks for evaluating knowledge update methods are mostly designed for the open domain and cannot address the specific challenges of the legal domain, such as the nuanced application of new legal knowledge, the complexity and lengthiness of legal regulations, and the intricate nature of legal reasoning. To address this gap, we introduce the Legal Knowledge Update BEnchmark, i.e. LeKUBE, which evaluates knowledge update methods for legal LLMs across five dimensions. Specifically, we categorize the needs of knowledge updates in the legal domain with the help of legal professionals, and then hire annotators from law schools to create synthetic updates to the Chinese Criminal and Civil Code as well as sets of questions of which the answers would change after the updates. Through a comprehensive evaluation of state-of-the-art knowledge update methods, we reveal a notable gap between existing knowledge update methods and the unique needs of the legal domain, emphasizing the need for further research and development of knowledge update mechanisms tailored for legal LLMs.
Mitigating Entity-Level Hallucination in Large Language Models
Jul 12, 2024



The emergence of Large Language Models (LLMs) has revolutionized how users access information, shifting from traditional search engines to direct question-and-answer interactions with LLMs. However, the widespread adoption of LLMs has revealed a significant challenge known as hallucination, wherein LLMs generate coherent yet factually inaccurate responses. This hallucination phenomenon has led to users' distrust in information retrieval systems based on LLMs. To tackle this challenge, this paper proposes Dynamic Retrieval Augmentation based on hallucination Detection (DRAD) as a novel method to detect and mitigate hallucinations in LLMs. DRAD improves upon traditional retrieval augmentation by dynamically adapting the retrieval process based on real-time hallucination detection. It features two main components: Real-time Hallucination Detection (RHD) for identifying potential hallucinations without external models, and Self-correction based on External Knowledge (SEK) for correcting these errors using external knowledge. Experiment results show that DRAD demonstrates superior performance in both detecting and mitigating hallucinations in LLMs. All of our code and data are open-sourced at https://github.com/oneal2000/EntityHallucination.
Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models
Mar 11, 2024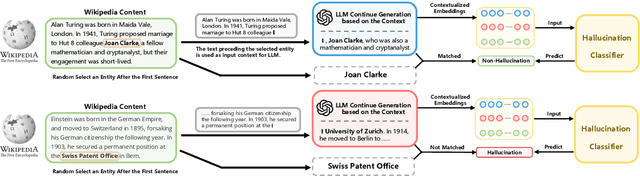

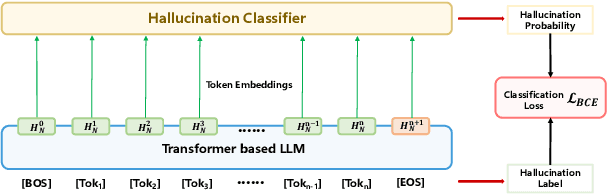

Hallucinations in large language models (LLMs) refer to the phenomenon of LLMs producing responses that are coherent yet factually inaccurate. This issue undermines the effectiveness of LLMs in practical applications, necessitating research into detecting and mitigating hallucinations of LLMs. Previous studies have mainly concentrated on post-processing techniques for hallucination detection, which tend to be computationally intensive and limited in effectiveness due to their separation from the LLM's inference process. To overcome these limitations, we introduce MIND, an unsupervised training framework that leverages the internal states of LLMs for real-time hallucination detection without requiring manual annotations. Additionally, we present HELM, a new benchmark for evaluating hallucination detection across multiple LLMs, featuring diverse LLM outputs and the internal states of LLMs during their inference process. Our experiments demonstrate that MIND outperforms existing state-of-the-art methods in hallucination detection.
THUIR@COLIEE 2023: More Parameters and Legal Knowledge for Legal Case Entailment
May 11, 2023
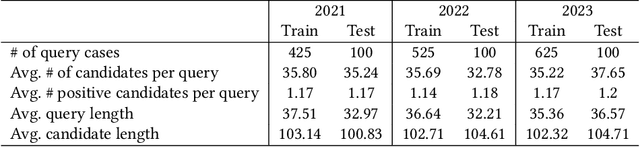
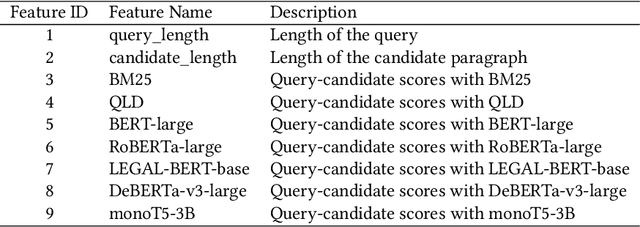
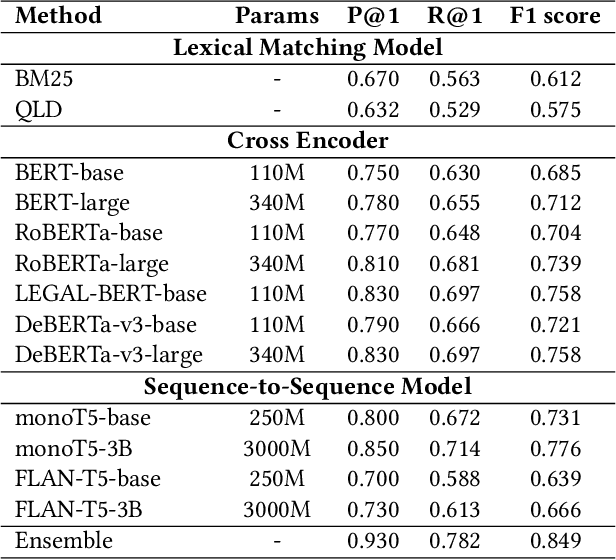
This paper describes the approach of the THUIR team at the COLIEE 2023 Legal Case Entailment task. This task requires the participant to identify a specific paragraph from a given supporting case that entails the decision for the query case. We try traditional lexical matching methods and pre-trained language models with different sizes. Furthermore, learning-to-rank methods are employed to further improve performance. However, learning-to-rank is not very robust on this task. which suggests that answer passages cannot simply be determined with information retrieval techniques. Experimental results show that more parameters and legal knowledge contribute to the legal case entailment task. Finally, we get the third place in COLIEE 2023. The implementation of our method can be found at https://github.com/CSHaitao/THUIR-COLIEE2023.
THUIR@COLIEE 2023: Incorporating Structural Knowledge into Pre-trained Language Models for Legal Case Retrieval
May 11, 2023
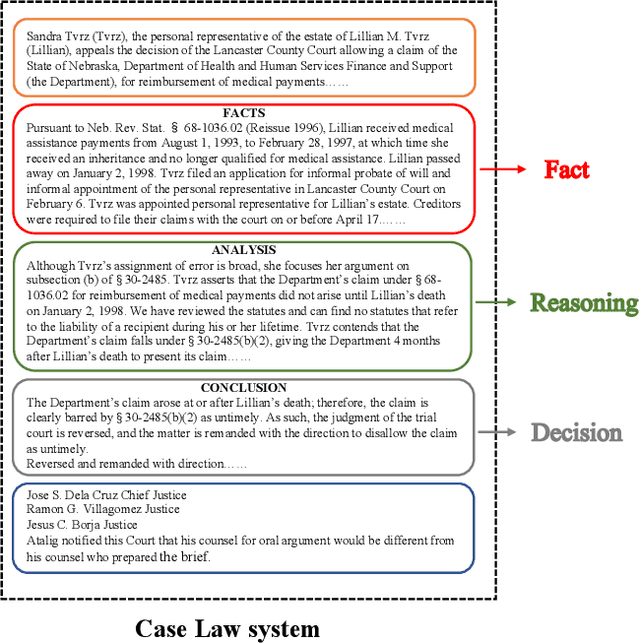
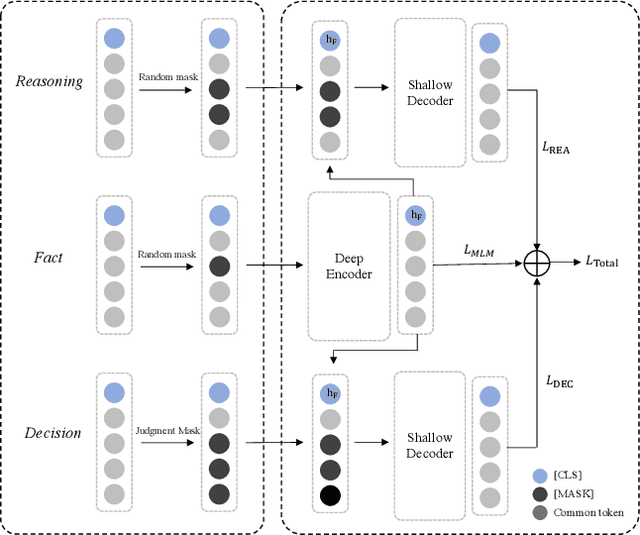
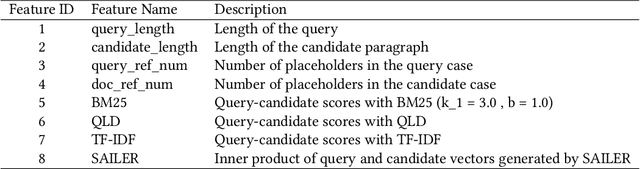
Legal case retrieval techniques play an essential role in modern intelligent legal systems. As an annually well-known international competition, COLIEE is aiming to achieve the state-of-the-art retrieval model for legal texts. This paper summarizes the approach of the championship team THUIR in COLIEE 2023. To be specific, we design structure-aware pre-trained language models to enhance the understanding of legal cases. Furthermore, we propose heuristic pre-processing and post-processing approaches to reduce the influence of irrelevant messages. In the end, learning-to-rank methods are employed to merge features with different dimensions. Experimental results demonstrate the superiority of our proposal. Official results show that our run has the best performance among all submissions. The implementation of our method can be found at https://github.com/CSHaitao/THUIR-COLIEE2023.