 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Mixture-of-Experts for Parametric Knowledge Injection
Jun 12, 2026Knowledge injection aims to equip large language models (LLMs) with external, domain-specific, or time-sensitive knowledge. Existing approaches typically face a trade-off between flexibility and integration: retrieval-augmented generation keeps knowledge outside the model but only provides prompt-level augmentation, whereas post-training based methods encode new knowledge into shared parameters but may introduce catastrophic forgetting, knowledge conflict, and costly updates. In this paper, we propose Decoupled Mixture-of-Experts (DMoE), a modular architecture for parametric knowledge injection that decouples both experts and the router from the base model. DMoE converts external knowledge corpora into independently updatable expert modules and uses a lightweight uncertainty-aware router to activate relevant experts only when the base model lacks sufficient knowledge during generation. To support efficient auto-regressive inference, DMoE attaches experts only to the final-layer feed-forward network, preserving KV-cache reuse while enabling parameter-level knowledge augmentation. Experiments on knowledge-intensive benchmarks show that DMoE consistently improves answer quality over retrieval and adapter-based baselines.
Adaptive Multi-Resolution Procedural Knowledge Compression for Large Language Models
Jun 10, 2026Large language models (LLMs) are widely used to tackle complex tasks with autonomous workflows. Recently, reusable natural language skills have emerged as a popular paradigm to inject procedural knowledge into LLM applications. Since popular skills are often invoked repeatedly, placing their full text in every context significantly increases prefill cost and latency. While text compression techniques have the potential to solve this problem, most existing methods are designed to compress factual knowledge in documents instead of procedural knowledge, making them insufficient for skill compression. In this paper, we argue that an effective skill compression method should: 1) preserve logical dependencies among workflows and tool protocols, 2) enable lightweight, offline compression for frequently updated community skills, and 3) be adaptable to varying complexities across skills. To address this, we present SKIM (SKIll coMpression), an adaptive multi-resolution soft token compression framework for procedural skills. Depending on the complexity of each skill, SKIM creates different numbers of soft tokens that not only improve the efficiency of LLM inference, but also preserve the effectiveness of skill usage. Experiments indicate that SKIM compresses skills to 30 to 60 percent of their original token length while preserving task performance better than existing compression methods.We have released our code at https://github.com/bebr2/SKIM .
Skill Retrieval Augmentation for Agentic AI
Apr 27, 2026As large language models (LLMs) evolve into agentic problem solvers, they increasingly rely on external, reusable skills to handle tasks beyond their native parametric capabilities. In existing agent systems, the dominant strategy for incorporating skills is to explicitly enumerate available skills within the context window. However, this strategy fails to scale: as skill corpora expand, context budgets are consumed rapidly, and the agent becomes markedly less accurate in identifying the right skill. To this end, this paper formulates Skill Retrieval Augmentation (SRA), a new paradigm in which agents dynamically retrieve, incorporate, and apply relevant skills from large external skill corpora on demand. To make this problem measurable, we construct a large-scale skill corpus and introduce SRA-Bench, the first benchmark for decomposed evaluation of the full SRA pipeline, covering skill retrieval, skill incorporation, and end-task execution. SRA-Bench contains 5,400 capability-intensive test instances and 636 manually constructed gold skills, which are mixed with web-collected distractor skills to form a large-scale corpus of 26,262 skills. Extensive experiments show that retrieval-based skill augmentation can substantially improve agent performance, validating the promise of the paradigm. At the same time, we uncover a fundamental gap in skill incorporation: current LLM agents tend to load skills at similar rates, regardless of whether a gold skill is retrieved or whether the task actually requires external capabilities. This shows that the bottleneck in skill augmentation lies not only in retrieval but also in the base model's ability to determine which skill to load and when external loading is actually needed. These findings position SRA as a distinct research problem and establish a foundation for the scalable augmentation of capabilities in future agent systems.
Multi-Field Tool Retrieval
Feb 05, 2026Integrating external tools enables Large Language Models (LLMs) to interact with real-world environments and solve complex tasks. Given the growing scale of available tools, effective tool retrieval is essential to mitigate constraints of LLMs' context windows and ensure computational efficiency. Existing approaches typically treat tool retrieval as a traditional ad-hoc retrieval task, matching user queries against the entire raw tool documentation. In this paper, we identify three fundamental challenges that limit the effectiveness of this paradigm: (i) the incompleteness and structural inconsistency of tool documentation; (ii) the significant semantic and granular mismatch between user queries and technical tool documents; and, most importantly, (iii) the multi-aspect nature of tool utility, that involves distinct dimensions, such as functionality, input constraints, and output formats, varying in format and importance. To address these challenges, we introduce Multi-Field Tool Retrieval, a framework designed to align user intent with tool representations through fine-grained, multi-field modeling. Experimental results show that our framework achieves SOTA performance on five datasets and a mixed benchmark, exhibiting superior generalizability and robustness.
Augmenting Multi-Agent Communication with State Delta Trajectory
Jun 24, 2025Multi-agent techniques such as role playing or multi-turn debates have been shown to be effective in improving the performance of large language models (LLMs) in downstream tasks. Despite their differences in workflows, existing LLM-based multi-agent systems mostly use natural language for agent communication. While this is appealing for its simplicity and interpretability, it also introduces inevitable information loss as one model must down sample its continuous state vectors to concrete tokens before transferring them to the other model. Such losses are particularly significant when the information to transfer is not simple facts, but reasoning logics or abstractive thoughts. To tackle this problem, we propose a new communication protocol that transfers both natural language tokens and token-wise state transition trajectory from one agent to another. Particularly, compared to the actual state value, we find that the sequence of state changes in LLMs after generating each token can better reflect the information hidden behind the inference process, so we propose a State Delta Encoding (SDE) method to represent state transition trajectories. The experimental results show that multi-agent systems with SDE achieve SOTA performance compared to other communication protocols, particularly in tasks that involve complex reasoning. This shows the potential of communication augmentation for LLM-based multi-agent systems.
Parametric Retrieval Augmented Generation
Jan 27, 2025Retrieval-augmented generation (RAG) techniques have emerged as a promising solution to enhance the reliability of large language models (LLMs) by addressing issues like hallucinations, outdated knowledge, and domain adaptation. In particular, existing RAG methods append relevant documents retrieved from external corpus or databases to the input of LLMs to guide their generation process, which we refer to as the in-context knowledge injection method. While this approach is simple and often effective, it has inherent limitations. Firstly, increasing the context length and number of relevant documents can lead to higher computational overhead and degraded performance, especially in complex reasoning tasks. More importantly, in-context knowledge injection operates primarily at the input level, but LLMs store their internal knowledge in their parameters. This gap fundamentally limits the capacity of in-context methods. To this end, we introduce Parametric retrieval-augmented generation (Parametric RAG), a new RAG paradigm that integrates external knowledge directly into the parameters of feed-forward networks (FFN) of an LLM through document parameterization. This approach not only saves online computational costs by eliminating the need to inject multiple documents into the LLMs' input context, but also deepens the integration of external knowledge into the parametric knowledge space of the LLM. Experimental results demonstrate that Parametric RAG substantially enhances both the effectiveness and efficiency of knowledge augmentation in LLMs. Also, it can be combined with in-context RAG methods to achieve even better performance. We have open-sourced all the code, data, and models in the following anonymized GitHub link: https://github.com/oneal2000/PRAG
Mitigating Entity-Level Hallucination in Large Language Models
Jul 12, 2024



The emergence of Large Language Models (LLMs) has revolutionized how users access information, shifting from traditional search engines to direct question-and-answer interactions with LLMs. However, the widespread adoption of LLMs has revealed a significant challenge known as hallucination, wherein LLMs generate coherent yet factually inaccurate responses. This hallucination phenomenon has led to users' distrust in information retrieval systems based on LLMs. To tackle this challenge, this paper proposes Dynamic Retrieval Augmentation based on hallucination Detection (DRAD) as a novel method to detect and mitigate hallucinations in LLMs. DRAD improves upon traditional retrieval augmentation by dynamically adapting the retrieval process based on real-time hallucination detection. It features two main components: Real-time Hallucination Detection (RHD) for identifying potential hallucinations without external models, and Self-correction based on External Knowledge (SEK) for correcting these errors using external knowledge. Experiment results show that DRAD demonstrates superior performance in both detecting and mitigating hallucinations in LLMs. All of our code and data are open-sourced at https://github.com/oneal2000/EntityHallucination.
DRAGIN: Dynamic Retrieval Augmented Generation based on the Real-time Information Needs of Large Language Models
Mar 15, 2024
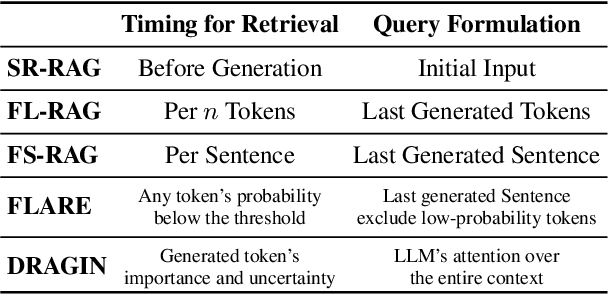
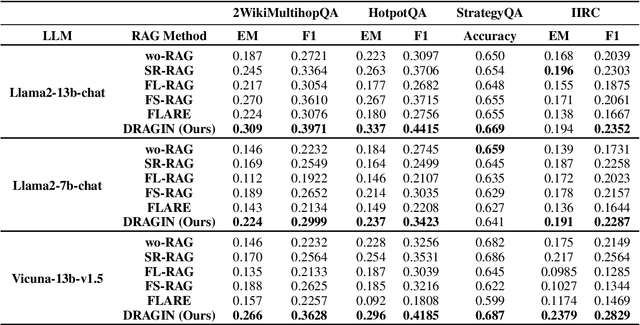
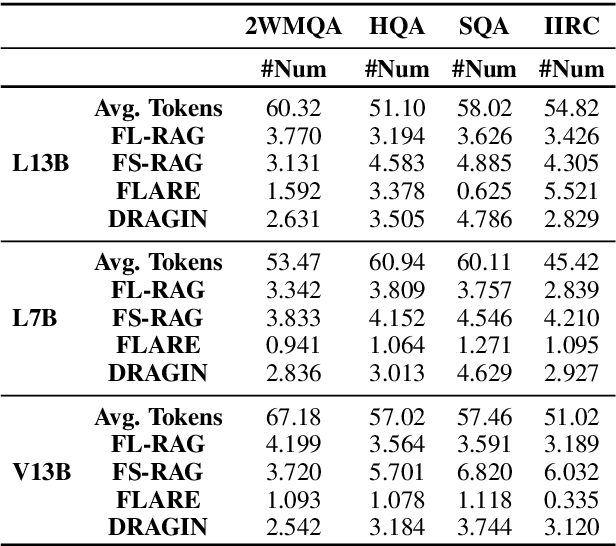
Dynamic retrieval augmented generation (RAG) paradigm actively decides when and what to retrieve during the text generation process of Large Language Models (LLMs). There are two key elements of this paradigm: identifying the optimal moment to activate the retrieval module (deciding when to retrieve) and crafting the appropriate query once retrieval is triggered (determining what to retrieve). However, current dynamic RAG methods fall short in both aspects. Firstly, the strategies for deciding when to retrieve often rely on static rules. Moreover, the strategies for deciding what to retrieve typically limit themselves to the LLM's most recent sentence or the last few tokens, while the LLM's real-time information needs may span across the entire context. To overcome these limitations, we introduce a new framework, DRAGIN, i.e., Dynamic Retrieval Augmented Generation based on the real-time Information Needs of LLMs. Our framework is specifically designed to make decisions on when and what to retrieve based on the LLM's real-time information needs during the text generation process. We evaluate DRAGIN along with existing methods comprehensively over 4 knowledge-intensive generation datasets. Experimental results show that DRAGIN achieves superior performance on all tasks, demonstrating the effectiveness of our method. We have open-sourced all the code, data, and models in GitHub: https://github.com/oneal2000/DRAGIN/tree/main
Towards the Classification of Error-Related Potentials using Riemannian Geometry
Sep 21, 2021
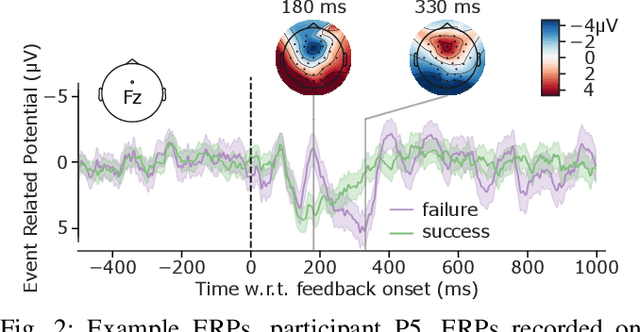


The error-related potential (ErrP) is an event-related potential (ERP) evoked by an experimental participant's recognition of an error during task performance. ErrPs, originally described by cognitive psychologists, have been adopted for use in brain-computer interfaces (BCIs) for the detection and correction of errors, and the online refinement of decoding algorithms. Riemannian geometry-based feature extraction and classification is a new approach to BCI which shows good performance in a range of experimental paradigms, but has yet to be applied to the classification of ErrPs. Here, we describe an experiment that elicited ErrPs in seven normal participants performing a visual discrimination task. Audio feedback was provided on each trial. We used multi-channel electroencephalogram (EEG) recordings to classify ErrPs (success/failure), comparing a Riemannian geometry-based method to a traditional approach that computes time-point features. Overall, the Riemannian approach outperformed the traditional approach (78.2% versus 75.9% accuracy, p < 0.05); this difference was statistically significant (p < 0.05) in three of seven participants. These results indicate that the Riemannian approach better captured the features from feedback-elicited ErrPs, and may have application in BCI for error detection and correction.