 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParametric Retrieval Augmented Generation
Jan 27, 2025Retrieval-augmented generation (RAG) techniques have emerged as a promising solution to enhance the reliability of large language models (LLMs) by addressing issues like hallucinations, outdated knowledge, and domain adaptation. In particular, existing RAG methods append relevant documents retrieved from external corpus or databases to the input of LLMs to guide their generation process, which we refer to as the in-context knowledge injection method. While this approach is simple and often effective, it has inherent limitations. Firstly, increasing the context length and number of relevant documents can lead to higher computational overhead and degraded performance, especially in complex reasoning tasks. More importantly, in-context knowledge injection operates primarily at the input level, but LLMs store their internal knowledge in their parameters. This gap fundamentally limits the capacity of in-context methods. To this end, we introduce Parametric retrieval-augmented generation (Parametric RAG), a new RAG paradigm that integrates external knowledge directly into the parameters of feed-forward networks (FFN) of an LLM through document parameterization. This approach not only saves online computational costs by eliminating the need to inject multiple documents into the LLMs' input context, but also deepens the integration of external knowledge into the parametric knowledge space of the LLM. Experimental results demonstrate that Parametric RAG substantially enhances both the effectiveness and efficiency of knowledge augmentation in LLMs. Also, it can be combined with in-context RAG methods to achieve even better performance. We have open-sourced all the code, data, and models in the following anonymized GitHub link: https://github.com/oneal2000/PRAG
Mixture-of-Modules: Reinventing Transformers as Dynamic Assemblies of Modules
Jul 09, 2024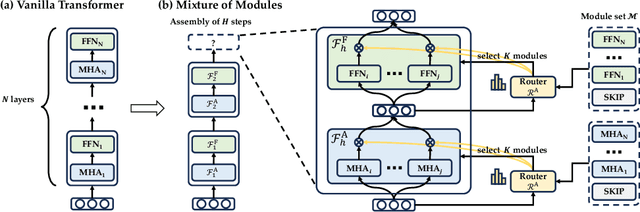
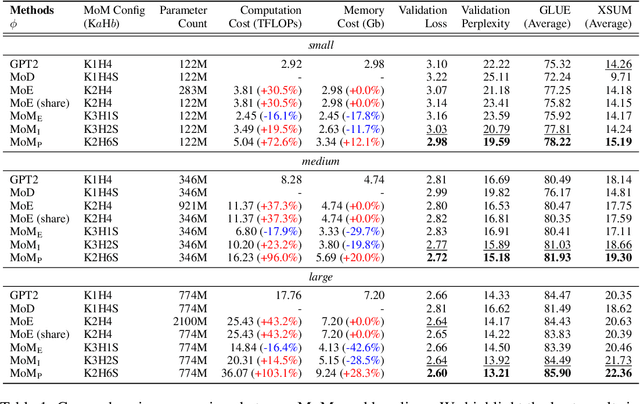
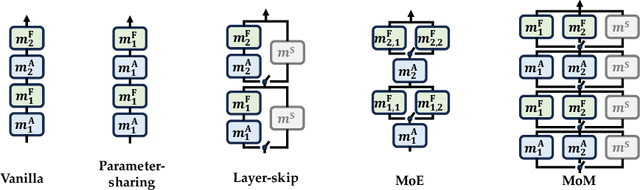
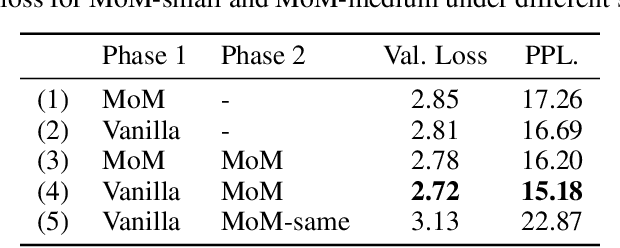
Is it always necessary to compute tokens from shallow to deep layers in Transformers? The continued success of vanilla Transformers and their variants suggests an undoubted "yes". In this work, however, we attempt to break the depth-ordered convention by proposing a novel architecture dubbed mixture-of-modules (MoM), which is motivated by an intuition that any layer, regardless of its position, can be used to compute a token as long as it possesses the needed processing capabilities. The construction of MoM starts from a finite set of modules defined by multi-head attention and feed-forward networks, each distinguished by its unique parameterization. Two routers then iteratively select attention modules and feed-forward modules from the set to process a token. The selection dynamically expands the computation graph in the forward pass of the token, culminating in an assembly of modules. We show that MoM provides not only a unified framework for Transformers and their numerous variants but also a flexible and learnable approach for reducing redundancy in Transformer parameterization. We pre-train various MoMs using OpenWebText. Empirical results demonstrate that MoMs, of different parameter counts, consistently outperform vanilla transformers on both GLUE and XSUM benchmarks. More interestingly, with a fixed parameter budget, MoM-large enables an over 38% increase in depth for computation graphs compared to GPT-2-large, resulting in absolute gains of 1.4 on GLUE and 1 on XSUM. On the other hand, MoM-large also enables an over 60% reduction in depth while involving more modules per layer, yielding a 16% reduction in TFLOPs and a 43% decrease in memory usage compared to GPT-2-large, while maintaining comparable performance.
Tool Learning with Foundation Models
Apr 17, 2023Humans possess an extraordinary ability to create and utilize tools, allowing them to overcome physical limitations and explore new frontiers. With the advent of foundation models, AI systems have the potential to be equally adept in tool use as humans. This paradigm, i.e., tool learning with foundation models, combines the strengths of specialized tools and foundation models to achieve enhanced accuracy, efficiency, and automation in problem-solving. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors in this field. To this end, we present a systematic investigation of tool learning in this paper. We first introduce the background of tool learning, including its cognitive origins, the paradigm shift of foundation models, and the complementary roles of tools and models. Then we recapitulate existing tool learning research into tool-augmented and tool-oriented learning. We formulate a general tool learning framework: starting from understanding the user instruction, models should learn to decompose a complex task into several subtasks, dynamically adjust their plan through reasoning, and effectively conquer each sub-task by selecting appropriate tools. We also discuss how to train models for improved tool-use capabilities and facilitate the generalization in tool learning. Considering the lack of a systematic tool learning evaluation in prior works, we experiment with 17 representative tools and show the potential of current foundation models in skillfully utilizing tools. Finally, we discuss several open problems that require further investigation for tool learning. Overall, we hope this paper could inspire future research in integrating tools with foundation models.