 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA2.1: Speeding Up Text Diffusion via Token Editing
Feb 09, 2026While LLaDA2.0 showcased the scaling potential of 100B-level block-diffusion models and their inherent parallelization, the delicate equilibrium between decoding speed and generation quality has remained an elusive frontier. Today, we unveil LLaDA2.1, a paradigm shift designed to transcend this trade-off. By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme, we introduce a joint, configurable threshold-decoding scheme. This structural innovation gives rise to two distinct personas: the Speedy Mode (S Mode), which audaciously lowers the M2T threshold to bypass traditional constraints while relying on T2T to refine the output; and the Quality Mode (Q Mode), which leans into conservative thresholds to secure superior benchmark performances with manageable efficiency degrade. Furthering this evolution, underpinned by an expansive context window, we implement the first large-scale Reinforcement Learning (RL) framework specifically tailored for dLLMs, anchored by specialized techniques for stable gradient estimation. This alignment not only sharpens reasoning precision but also elevates instruction-following fidelity, bridging the chasm between diffusion dynamics and complex human intent. We culminate this work by releasing LLaDA2.1-Mini (16B) and LLaDA2.1-Flash (100B). Across 33 rigorous benchmarks, LLaDA2.1 delivers strong task performance and lightning-fast decoding speed. Despite its 100B volume, on coding tasks it attains an astounding 892 TPS on HumanEval+, 801 TPS on BigCodeBench, and 663 TPS on LiveCodeBench.
Efficient RL Training for Reasoning Models via Length-Aware Optimization
May 18, 2025Large reasoning models, such as OpenAI o1 or DeepSeek R1, have demonstrated remarkable performance on reasoning tasks but often incur a long reasoning path with significant memory and time costs. Existing methods primarily aim to shorten reasoning paths by introducing additional training data and stages. In this paper, we propose three critical reward designs integrated directly into the reinforcement learning process of large reasoning models, which reduce the response length without extra training stages. Experiments on four settings show that our method significantly decreases response length while maintaining or even improving performance. Specifically, in a logic reasoning setting, we achieve a 40% reduction in response length averaged by steps alongside a 14% gain in performance. For math problems, we reduce response length averaged by steps by 33% while preserving performance.
Latent Preference Coding: Aligning Large Language Models via Discrete Latent Codes
May 08, 2025Large language models (LLMs) have achieved remarkable success, yet aligning their generations with human preferences remains a critical challenge. Existing approaches to preference modeling often rely on an explicit or implicit reward function, overlooking the intricate and multifaceted nature of human preferences that may encompass conflicting factors across diverse tasks and populations. To address this limitation, we introduce Latent Preference Coding (LPC), a novel framework that models the implicit factors as well as their combinations behind holistic preferences using discrete latent codes. LPC seamlessly integrates with various offline alignment algorithms, automatically inferring the underlying factors and their importance from data without relying on pre-defined reward functions and hand-crafted combination weights. Extensive experiments on multiple benchmarks demonstrate that LPC consistently improves upon three alignment algorithms (DPO, SimPO, and IPO) using three base models (Mistral-7B, Llama3-8B, and Llama3-8B-Instruct). Furthermore, deeper analysis reveals that the learned latent codes effectively capture the differences in the distribution of human preferences and significantly enhance the robustness of alignment against noise in data. By providing a unified representation for the multifarious preference factors, LPC paves the way towards developing more robust and versatile alignment techniques for the responsible deployment of powerful LLMs.
FIRP: Faster LLM inference via future intermediate representation prediction
Oct 27, 2024Recent advancements in Large Language Models (LLMs) have shown remarkable performance across a wide range of tasks. Despite this, the auto-regressive nature of LLM decoding, which generates only a single token per forward propagation, fails to fully exploit the parallel computational power of GPUs, leading to considerable latency. To address this, we introduce a novel speculative decoding method named FIRP which generates multiple tokens instead of one at each decoding step. We achieve this by predicting the intermediate hidden states of future tokens (tokens have not been decoded yet) and then using these pseudo hidden states to decode future tokens, specifically, these pseudo hidden states are predicted with simple linear transformation in intermediate layers of LLMs. Once predicted, they participate in the computation of all the following layers, thereby assimilating richer semantic information. As the layers go deeper, the semantic gap between pseudo and real hidden states is narrowed and it becomes feasible to decode future tokens with high accuracy. To validate the effectiveness of FIRP, we conduct extensive experiments, showing a speedup ratio of 1.9x-3x in several models and datasets, analytical experiments also prove our motivations.
Graph-Structured Speculative Decoding
Jul 23, 2024
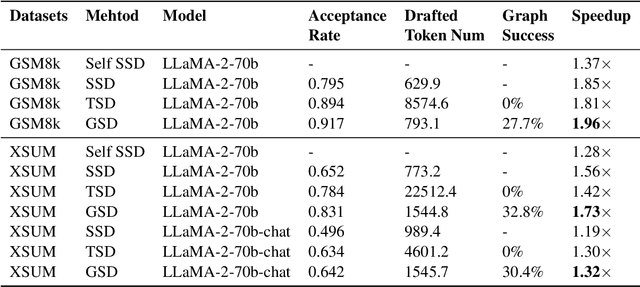
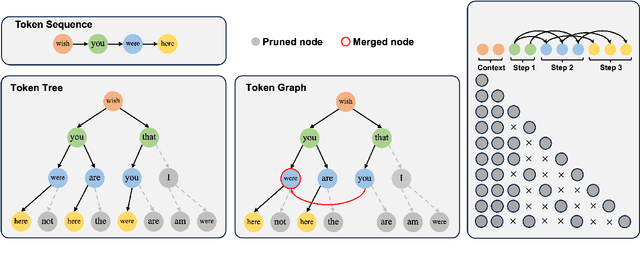
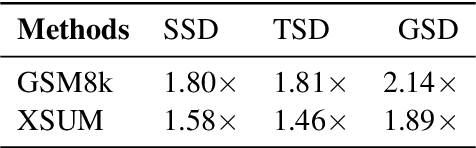
Speculative decoding has emerged as a promising technique to accelerate the inference of Large Language Models (LLMs) by employing a small language model to draft a hypothesis sequence, which is then validated by the LLM. The effectiveness of this approach heavily relies on the balance between performance and efficiency of the draft model. In our research, we focus on enhancing the proportion of draft tokens that are accepted to the final output by generating multiple hypotheses instead of just one. This allows the LLM more options to choose from and select the longest sequence that meets its standards. Our analysis reveals that hypotheses produced by the draft model share many common token sequences, suggesting a potential for optimizing computation. Leveraging this observation, we introduce an innovative approach utilizing a directed acyclic graph (DAG) to manage the drafted hypotheses. This structure enables us to efficiently predict and merge recurring token sequences, vastly reducing the computational demands of the draft model. We term this approach Graph-structured Speculative Decoding (GSD). We apply GSD across a range of LLMs, including a 70-billion parameter LLaMA-2 model, and observe a remarkable speedup of 1.73$\times$ to 1.96$\times$, significantly surpassing standard speculative decoding.
Mixture-of-Modules: Reinventing Transformers as Dynamic Assemblies of Modules
Jul 09, 2024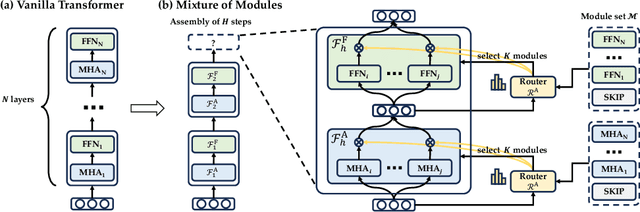
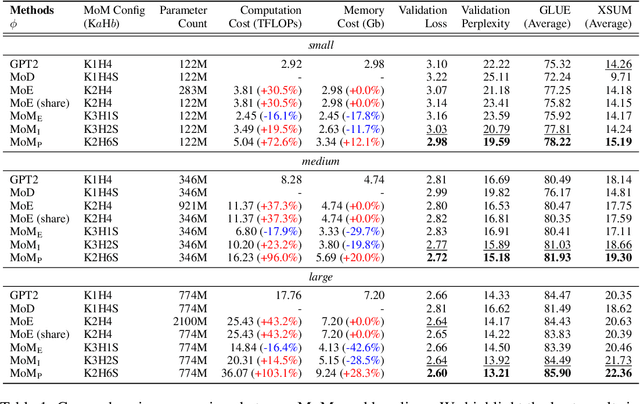
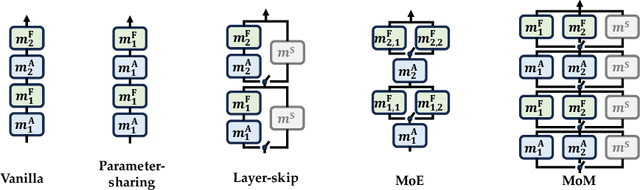
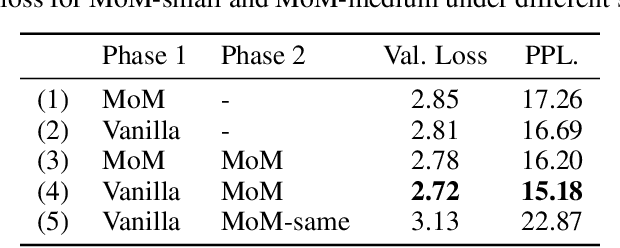
Is it always necessary to compute tokens from shallow to deep layers in Transformers? The continued success of vanilla Transformers and their variants suggests an undoubted "yes". In this work, however, we attempt to break the depth-ordered convention by proposing a novel architecture dubbed mixture-of-modules (MoM), which is motivated by an intuition that any layer, regardless of its position, can be used to compute a token as long as it possesses the needed processing capabilities. The construction of MoM starts from a finite set of modules defined by multi-head attention and feed-forward networks, each distinguished by its unique parameterization. Two routers then iteratively select attention modules and feed-forward modules from the set to process a token. The selection dynamically expands the computation graph in the forward pass of the token, culminating in an assembly of modules. We show that MoM provides not only a unified framework for Transformers and their numerous variants but also a flexible and learnable approach for reducing redundancy in Transformer parameterization. We pre-train various MoMs using OpenWebText. Empirical results demonstrate that MoMs, of different parameter counts, consistently outperform vanilla transformers on both GLUE and XSUM benchmarks. More interestingly, with a fixed parameter budget, MoM-large enables an over 38% increase in depth for computation graphs compared to GPT-2-large, resulting in absolute gains of 1.4 on GLUE and 1 on XSUM. On the other hand, MoM-large also enables an over 60% reduction in depth while involving more modules per layer, yielding a 16% reduction in TFLOPs and a 43% decrease in memory usage compared to GPT-2-large, while maintaining comparable performance.
Parallel Decoding via Hidden Transfer for Lossless Large Language Model Acceleration
Apr 18, 2024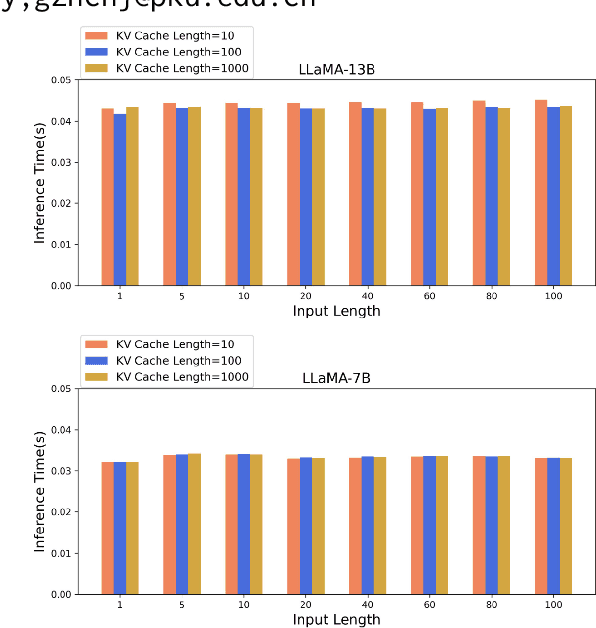
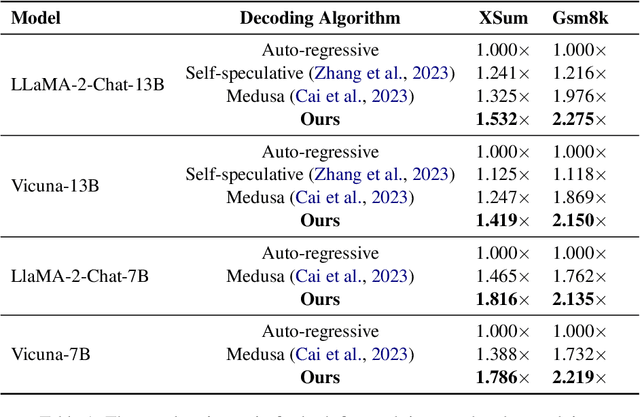
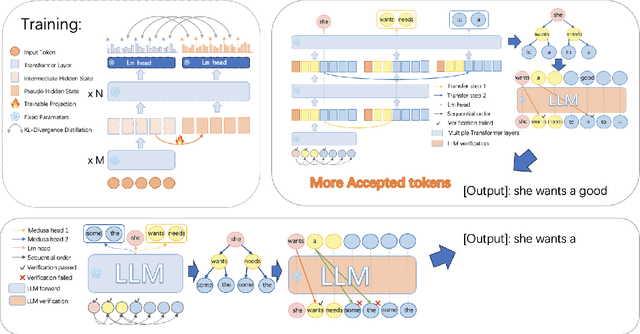
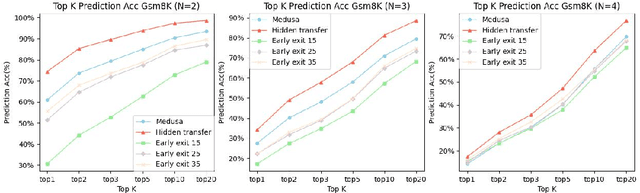
Large language models (LLMs) have recently shown remarkable performance across a wide range of tasks. However, the substantial number of parameters in LLMs contributes to significant latency during model inference. This is particularly evident when utilizing autoregressive decoding methods, which generate one token in a single forward process, thereby not fully capitalizing on the parallel computing capabilities of GPUs. In this paper, we propose a novel parallel decoding approach, namely \textit{hidden transfer}, which decodes multiple successive tokens simultaneously in a single forward pass. The idea is to transfer the intermediate hidden states of the previous context to the \textit{pseudo} hidden states of the future tokens to be generated, and then the pseudo hidden states will pass the following transformer layers thereby assimilating more semantic information and achieving superior predictive accuracy of the future tokens. Besides, we use the novel tree attention mechanism to simultaneously generate and verify multiple candidates of output sequences, which ensure the lossless generation and further improves the generation efficiency of our method. Experiments demonstrate the effectiveness of our method. We conduct a lot of analytic experiments to prove our motivation. In terms of acceleration metrics, we outperform all the single-model acceleration techniques, including Medusa and Self-Speculative decoding.
What Makes Quantization for Large Language Models Hard? An Empirical Study from the Lens of Perturbation
Mar 11, 2024Quantization has emerged as a promising technique for improving the memory and computational efficiency of large language models (LLMs). Though the trade-off between performance and efficiency is well-known, there is still much to be learned about the relationship between quantization and LLM performance. To shed light on this relationship, we propose a new perspective on quantization, viewing it as perturbations added to the weights and activations of LLMs. We call this approach "the lens of perturbation". Using this lens, we conduct experiments with various artificial perturbations to explore their impact on LLM performance. Our findings reveal several connections between the properties of perturbations and LLM performance, providing insights into the failure cases of uniform quantization and suggesting potential solutions to improve the robustness of LLM quantization. To demonstrate the significance of our findings, we implement a simple non-uniform quantization approach based on our insights. Our experiments show that this approach achieves minimal performance degradation on both 4-bit weight quantization and 8-bit quantization for weights and activations. These results validate the correctness of our approach and highlight its potential to improve the efficiency of LLMs without sacrificing performance.
Improving Input-label Mapping with Demonstration Replay for In-context Learning
Oct 30, 2023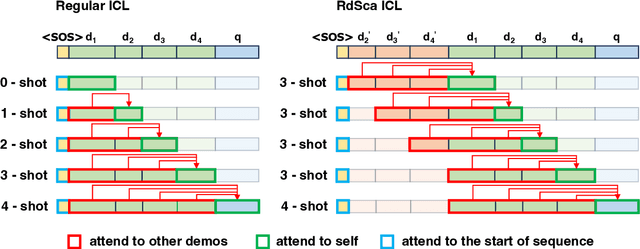



In-context learning (ICL) is an emerging capability of large autoregressive language models where a few input-label demonstrations are appended to the input to enhance the model's understanding of downstream NLP tasks, without directly adjusting the model parameters. The effectiveness of ICL can be attributed to the strong language modeling capabilities of large language models (LLMs), which enable them to learn the mapping between input and labels based on in-context demonstrations. Despite achieving promising results, the causal nature of language modeling in ICL restricts the attention to be backward only, i.e., a token only attends to its previous tokens, failing to capture the full input-label information and limiting the model's performance. In this paper, we propose a novel ICL method called Repeated Demonstration with Sliding Causal Attention, (RdSca). Specifically, we duplicate later demonstrations and concatenate them to the front, allowing the model to `observe' the later information even under the causal restriction. Besides, we introduce sliding causal attention, which customizes causal attention to avoid information leakage. Experimental results show that our method significantly improves the input-label mapping in ICL demonstrations. We also conduct an in-depth analysis of how to customize the causal attention without training, which has been an unexplored area in previous research.
PreQuant: A Task-agnostic Quantization Approach for Pre-trained Language Models
May 30, 2023
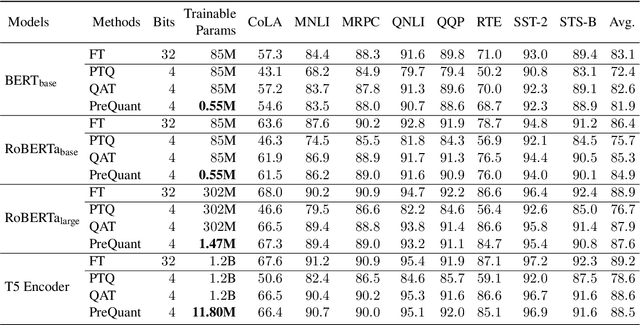


While transformer-based pre-trained language models (PLMs) have dominated a number of NLP applications, these models are heavy to deploy and expensive to use. Therefore, effectively compressing large-scale PLMs becomes an increasingly important problem. Quantization, which represents high-precision tensors with low-bit fix-point format, is a viable solution. However, most existing quantization methods are task-specific, requiring customized training and quantization with a large number of trainable parameters on each individual task. Inspired by the observation that the over-parameterization nature of PLMs makes it possible to freeze most of the parameters during the fine-tuning stage, in this work, we propose a novel ``quantize before fine-tuning'' framework, PreQuant, that differs from both quantization-aware training and post-training quantization. PreQuant is compatible with various quantization strategies, with outlier-aware parameter-efficient fine-tuning incorporated to correct the induced quantization error. We demonstrate the effectiveness of PreQuant on the GLUE benchmark using BERT, RoBERTa, and T5. We also provide an empirical investigation into the workflow of PreQuant, which sheds light on its efficacy.