 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Modules: Reinventing Transformers as Dynamic Assemblies of Modules
Paper and Code
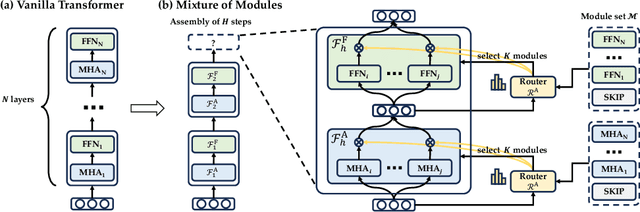
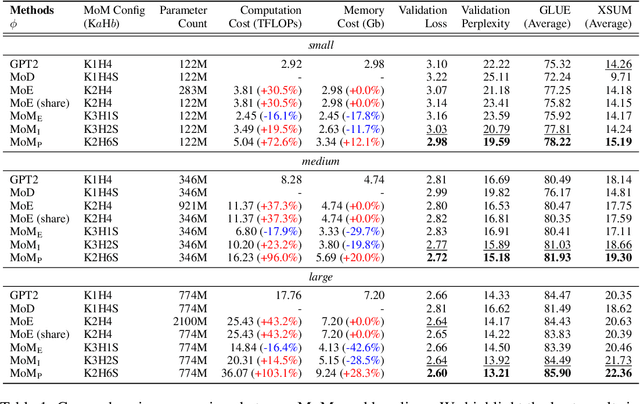
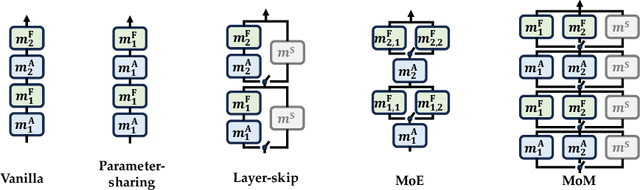
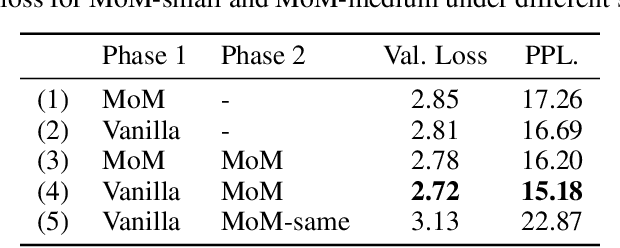
Is it always necessary to compute tokens from shallow to deep layers in Transformers? The continued success of vanilla Transformers and their variants suggests an undoubted "yes". In this work, however, we attempt to break the depth-ordered convention by proposing a novel architecture dubbed mixture-of-modules (MoM), which is motivated by an intuition that any layer, regardless of its position, can be used to compute a token as long as it possesses the needed processing capabilities. The construction of MoM starts from a finite set of modules defined by multi-head attention and feed-forward networks, each distinguished by its unique parameterization. Two routers then iteratively select attention modules and feed-forward modules from the set to process a token. The selection dynamically expands the computation graph in the forward pass of the token, culminating in an assembly of modules. We show that MoM provides not only a unified framework for Transformers and their numerous variants but also a flexible and learnable approach for reducing redundancy in Transformer parameterization. We pre-train various MoMs using OpenWebText. Empirical results demonstrate that MoMs, of different parameter counts, consistently outperform vanilla transformers on both GLUE and XSUM benchmarks. More interestingly, with a fixed parameter budget, MoM-large enables an over 38% increase in depth for computation graphs compared to GPT-2-large, resulting in absolute gains of 1.4 on GLUE and 1 on XSUM. On the other hand, MoM-large also enables an over 60% reduction in depth while involving more modules per layer, yielding a 16% reduction in TFLOPs and a 43% decrease in memory usage compared to GPT-2-large, while maintaining comparable performance.