 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeKUBE: A Legal Knowledge Update BEnchmark
Jul 19, 2024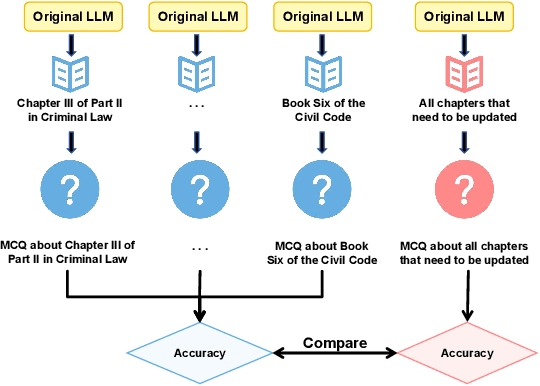
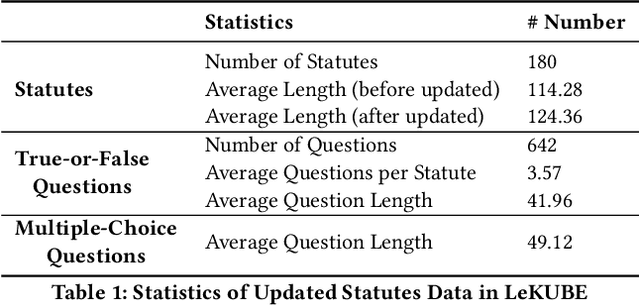
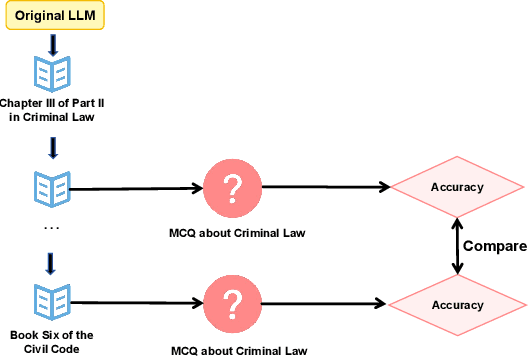
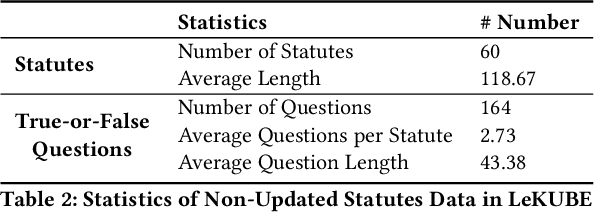
Recent advances in Large Language Models (LLMs) have significantly shaped the applications of AI in multiple fields, including the studies of legal intelligence. Trained on extensive legal texts, including statutes and legal documents, the legal LLMs can capture important legal knowledge/concepts effectively and provide important support for downstream legal applications such as legal consultancy. Yet, the dynamic nature of legal statutes and interpretations also poses new challenges to the use of LLMs in legal applications. Particularly, how to update the legal knowledge of LLMs effectively and efficiently has become an important research problem in practice. Existing benchmarks for evaluating knowledge update methods are mostly designed for the open domain and cannot address the specific challenges of the legal domain, such as the nuanced application of new legal knowledge, the complexity and lengthiness of legal regulations, and the intricate nature of legal reasoning. To address this gap, we introduce the Legal Knowledge Update BEnchmark, i.e. LeKUBE, which evaluates knowledge update methods for legal LLMs across five dimensions. Specifically, we categorize the needs of knowledge updates in the legal domain with the help of legal professionals, and then hire annotators from law schools to create synthetic updates to the Chinese Criminal and Civil Code as well as sets of questions of which the answers would change after the updates. Through a comprehensive evaluation of state-of-the-art knowledge update methods, we reveal a notable gap between existing knowledge update methods and the unique needs of the legal domain, emphasizing the need for further research and development of knowledge update mechanisms tailored for legal LLMs.
LEEC: A Legal Element Extraction Dataset with an Extensive Domain-Specific Label System
Oct 10, 2023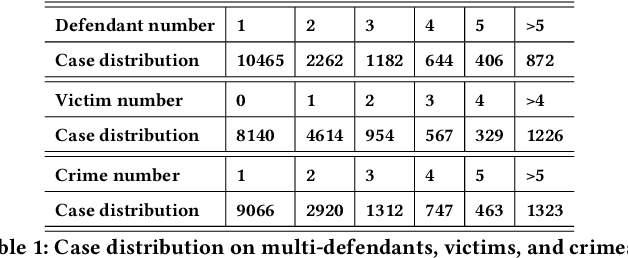
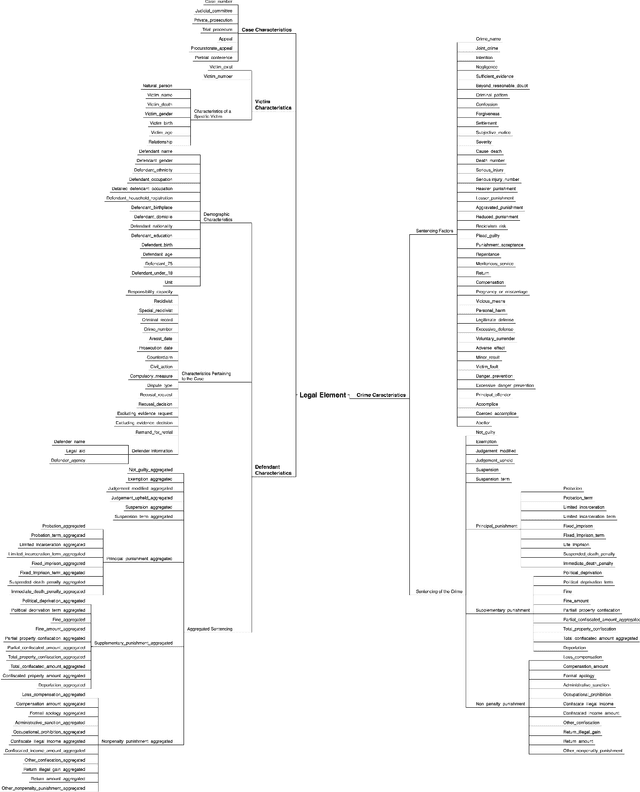
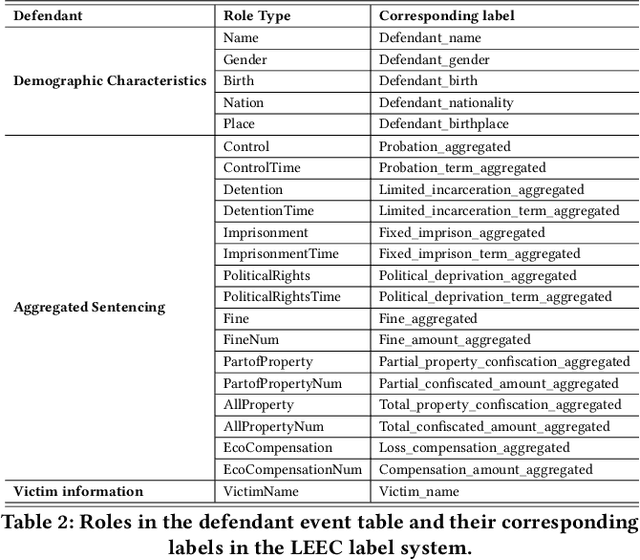
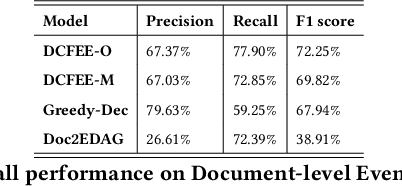
As a pivotal task in natural language processing, element extraction has gained significance in the legal domain. Extracting legal elements from judicial documents helps enhance interpretative and analytical capacities of legal cases, and thereby facilitating a wide array of downstream applications in various domains of law. Yet existing element extraction datasets are limited by their restricted access to legal knowledge and insufficient coverage of labels. To address this shortfall, we introduce a more comprehensive, large-scale criminal element extraction dataset, comprising 15,831 judicial documents and 159 labels. This dataset was constructed through two main steps: first, designing the label system by our team of legal experts based on prior legal research which identified critical factors driving and processes generating sentencing outcomes in criminal cases; second, employing the legal knowledge to annotate judicial documents according to the label system and annotation guideline. The Legal Element ExtraCtion dataset (LEEC) represents the most extensive and domain-specific legal element extraction dataset for the Chinese legal system. Leveraging the annotated data, we employed various SOTA models that validates the applicability of LEEC for Document Event Extraction (DEE) task. The LEEC dataset is available on https://github.com/THUlawtech/LEEC .