 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEEC: A Legal Element Extraction Dataset with an Extensive Domain-Specific Label System
Paper and Code
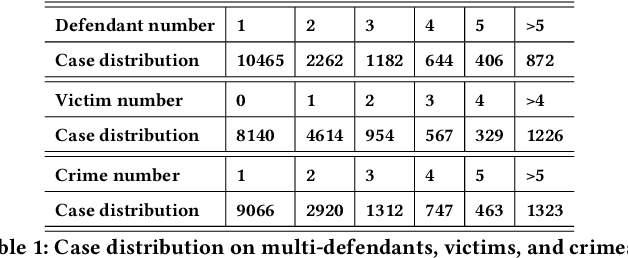
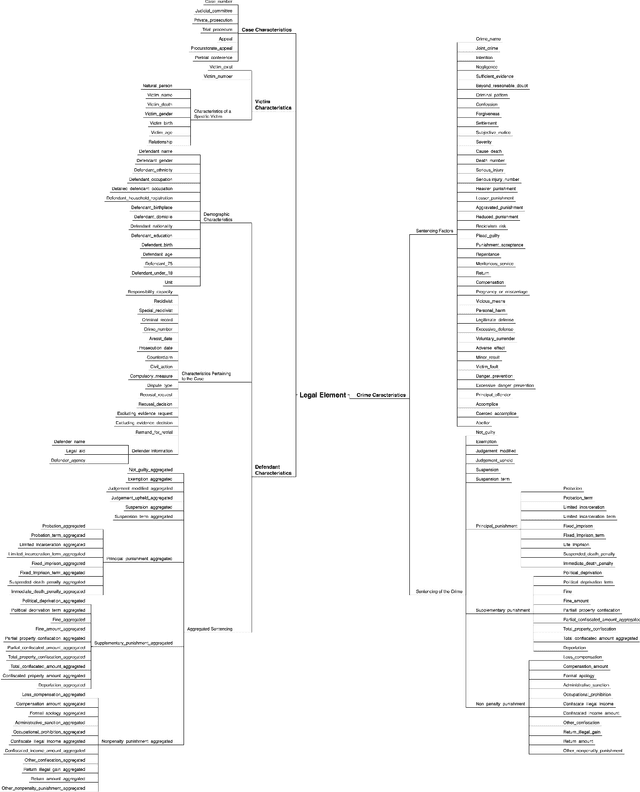
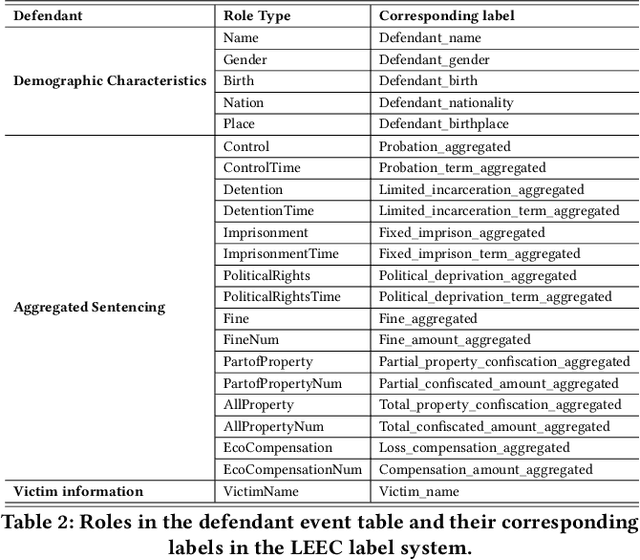
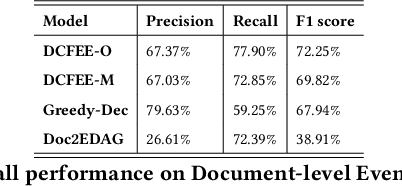
As a pivotal task in natural language processing, element extraction has gained significance in the legal domain. Extracting legal elements from judicial documents helps enhance interpretative and analytical capacities of legal cases, and thereby facilitating a wide array of downstream applications in various domains of law. Yet existing element extraction datasets are limited by their restricted access to legal knowledge and insufficient coverage of labels. To address this shortfall, we introduce a more comprehensive, large-scale criminal element extraction dataset, comprising 15,831 judicial documents and 159 labels. This dataset was constructed through two main steps: first, designing the label system by our team of legal experts based on prior legal research which identified critical factors driving and processes generating sentencing outcomes in criminal cases; second, employing the legal knowledge to annotate judicial documents according to the label system and annotation guideline. The Legal Element ExtraCtion dataset (LEEC) represents the most extensive and domain-specific legal element extraction dataset for the Chinese legal system. Leveraging the annotated data, we employed various SOTA models that validates the applicability of LEEC for Document Event Extraction (DEE) task. The LEEC dataset is available on https://github.com/THUlawtech/LEEC .