 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study of the Capabilities of Large Language Models for Vulnerability Detection
Mar 25, 2024



Large Language Models (LLMs) have demonstrated great potential for code generation and other software engineering tasks. Vulnerability detection is of crucial importance to maintaining the security, integrity, and trustworthiness of software systems. Precise vulnerability detection requires reasoning about the code, making it a good case study for exploring the limits of LLMs' reasoning capabilities. Although recent work has applied LLMs to vulnerability detection using generic prompting techniques, their full capabilities for this task and the types of errors they make when explaining identified vulnerabilities remain unclear. In this paper, we surveyed eleven LLMs that are state-of-the-art in code generation and commonly used as coding assistants, and evaluated their capabilities for vulnerability detection. We systematically searched for the best-performing prompts, incorporating techniques such as in-context learning and chain-of-thought, and proposed three of our own prompting methods. Our results show that while our prompting methods improved the models' performance, LLMs generally struggled with vulnerability detection. They reported 0.5-0.63 Balanced Accuracy and failed to distinguish between buggy and fixed versions of programs in 76% of cases on average. By comprehensively analyzing and categorizing 287 instances of model reasoning, we found that 57% of LLM responses contained errors, and the models frequently predicted incorrect locations of buggy code and misidentified bug types. LLMs only correctly localized 6 out of 27 bugs in DbgBench, and these 6 bugs were predicted correctly by 70-100% of human participants. These findings suggest that despite their potential for other tasks, LLMs may fail to properly comprehend critical code structures and security-related concepts. Our data and code are available at https://figshare.com/s/78fe02e56e09ec49300b.
ActiveClean: Generating Line-Level Vulnerability Data via Active Learning
Dec 04, 2023
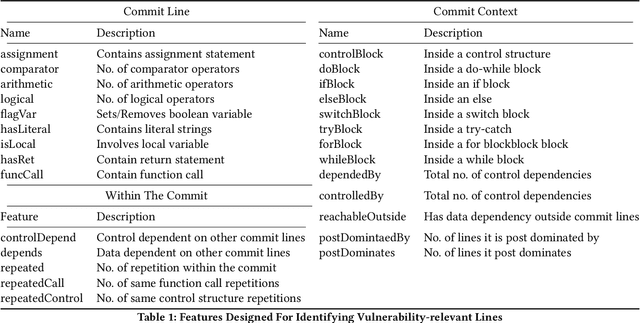
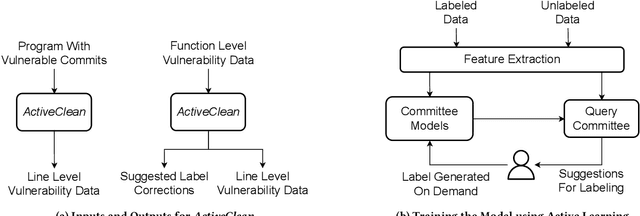
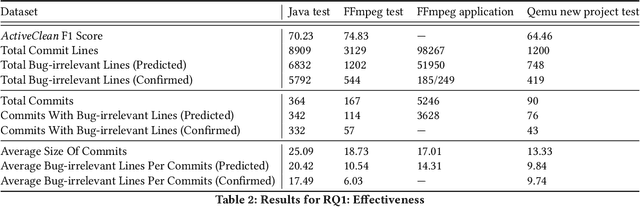
Deep learning vulnerability detection tools are increasing in popularity and have been shown to be effective. These tools rely on large volume of high quality training data, which are very hard to get. Most of the currently available datasets provide function-level labels, reporting whether a function is vulnerable or not vulnerable. However, for a vulnerability detection to be useful, we need to also know the lines that are relevant to the vulnerability. This paper makes efforts towards developing systematic tools and proposes. ActiveClean to generate the large volume of line-level vulnerability data from commits. That is, in addition to function-level labels, it also reports which lines in the function are likely responsible for vulnerability detection. In the past, static analysis has been applied to clean commits to generate line-level data. Our approach based on active learning, which is easy to use and scalable, provide a complementary approach to static analysis. We designed semantic and syntactic properties from commit lines and use them to train the model. We evaluated our approach on both Java and C datasets processing more than 4.3K commits and 119K commit lines. AcitveClean achieved an F1 score between 70-74. Further, we also show that active learning is effective by using just 400 training data to reach F1 score of 70.23. Using ActiveClean, we generate the line-level labels for the entire FFMpeg project in the Devign dataset, including 5K functions, and also detected incorrect function-level labels. We demonstrated that using our cleaned data, LineVul, a SOTA line-level vulnerability detection tool, detected 70 more vulnerable lines and 18 more vulnerable functions, and improved Top 10 accuracy from 66% to 73%.