 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM6-10T: A Sharing-Delinking Paradigm for Efficient Multi-Trillion Parameter Pretraining
Paper and Code
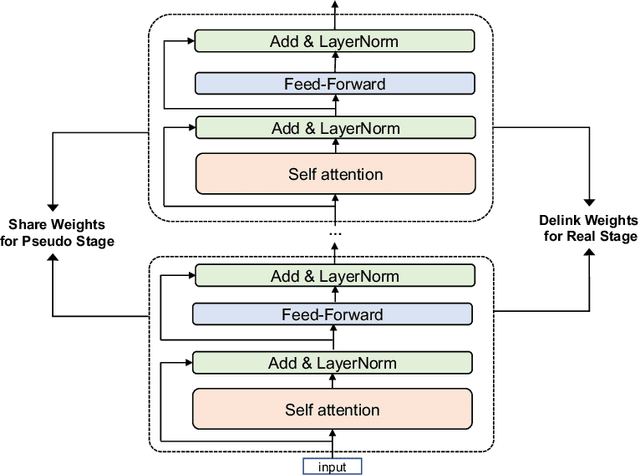

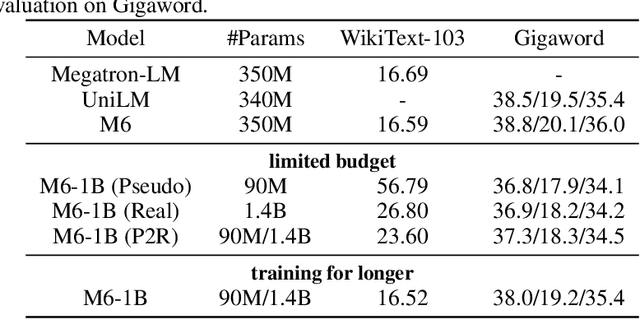
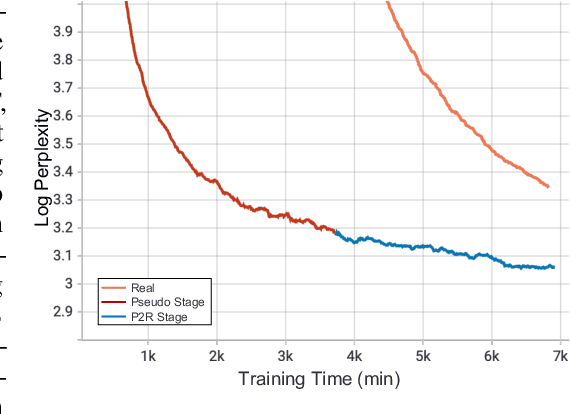
Recent expeditious developments in deep learning algorithms, distributed training, and even hardware design for large models have enabled training extreme-scale models, say GPT-3 and Switch Transformer possessing hundreds of billions or even trillions of parameters. However, under limited resources, extreme-scale model training that requires enormous amounts of computes and memory footprint suffers from frustratingly low efficiency in model convergence. In this paper, we propose a simple training strategy called "Pseudo-to-Real" for high-memory-footprint-required large models. Pseudo-to-Real is compatible with large models with architecture of sequential layers. We demonstrate a practice of pretraining unprecedented 10-trillion-parameter model, an order of magnitude larger than the state-of-the-art, on solely 512 GPUs within 10 days. Besides demonstrating the application of Pseudo-to-Real, we also provide a technique, Granular CPU offloading, to manage CPU memory for training large model and maintain high GPU utilities. Fast training of extreme-scale models on a decent amount of resources can bring much smaller carbon footprint and contribute to greener AI.