 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAP: Accelerating Large-Scale DNN Training Through Tensor Automatic Parallelisation
Paper and Code
Feb 01, 2023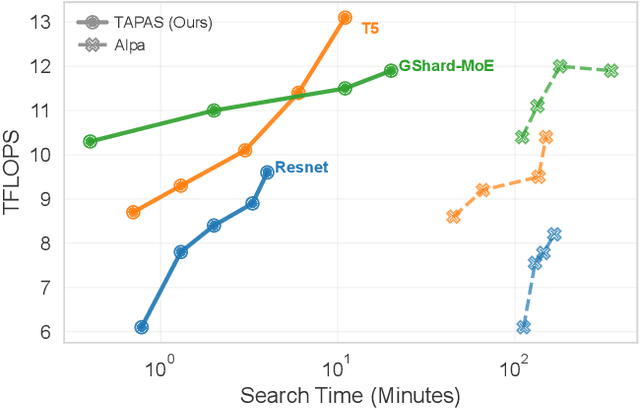

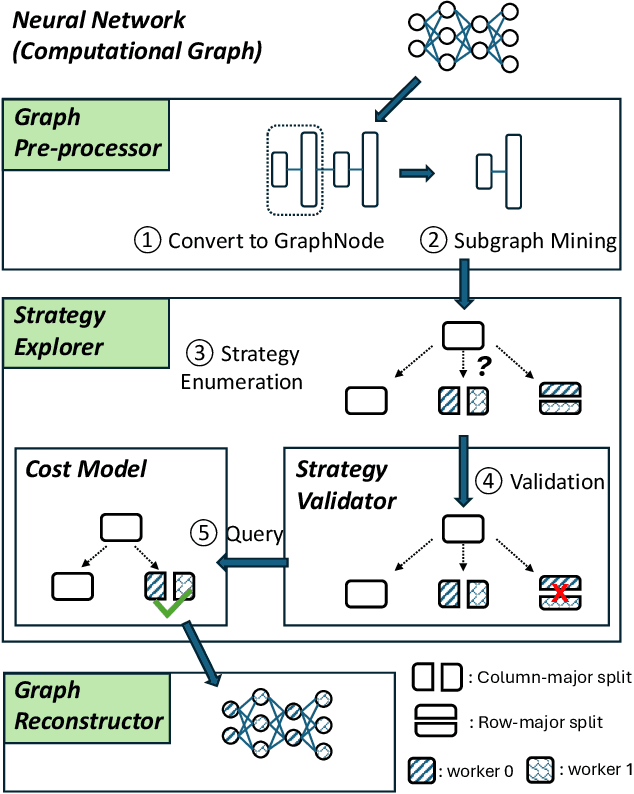
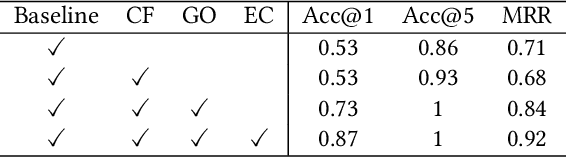
Model parallelism has become necessary to train large neural networks. However, finding a suitable model parallel schedule for an arbitrary neural network is a non-trivial task due to the exploding search space. In this work, we present a model parallelism framework TAP that automatically searches for the best data and tensor parallel schedules. Leveraging the key insight that a neural network can be represented as a directed acyclic graph, within which may only exist a limited set of frequent subgraphs, we design a graph pruning algorithm to fold the search space efficiently. TAP runs at sub-linear complexity concerning the neural network size. Experiments show that TAP is $20\times- 160\times$ faster than the state-of-the-art automatic parallelism framework, and the performance of its discovered schedules is competitive with the expert-engineered ones.