 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Stage Virtual Try-on via Deformable Attention Flows
Jul 19, 2022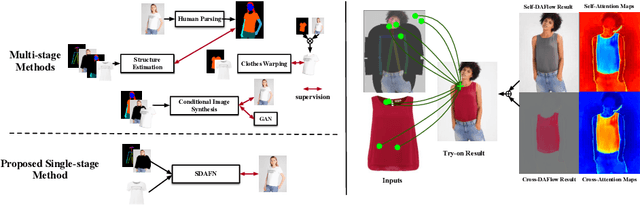

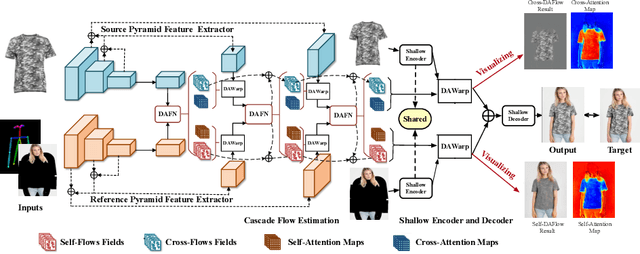
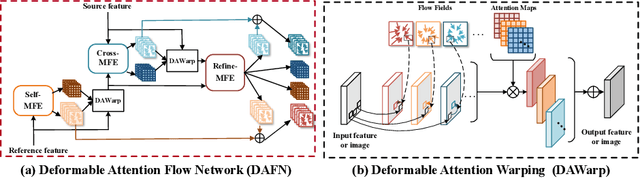
Virtual try-on aims to generate a photo-realistic fitting result given an in-shop garment and a reference person image. Existing methods usually build up multi-stage frameworks to deal with clothes warping and body blending respectively, or rely heavily on intermediate parser-based labels which may be noisy or even inaccurate. To solve the above challenges, we propose a single-stage try-on framework by developing a novel Deformable Attention Flow (DAFlow), which applies the deformable attention scheme to multi-flow estimation. With pose keypoints as the guidance only, the self- and cross-deformable attention flows are estimated for the reference person and the garment images, respectively. By sampling multiple flow fields, the feature-level and pixel-level information from different semantic areas are simultaneously extracted and merged through the attention mechanism. It enables clothes warping and body synthesizing at the same time which leads to photo-realistic results in an end-to-end manner. Extensive experiments on two try-on datasets demonstrate that our proposed method achieves state-of-the-art performance both qualitatively and quantitatively. Furthermore, additional experiments on the other two image editing tasks illustrate the versatility of our method for multi-view synthesis and image animation.
M6-Fashion: High-Fidelity Multi-modal Image Generation and Editing
May 24, 2022
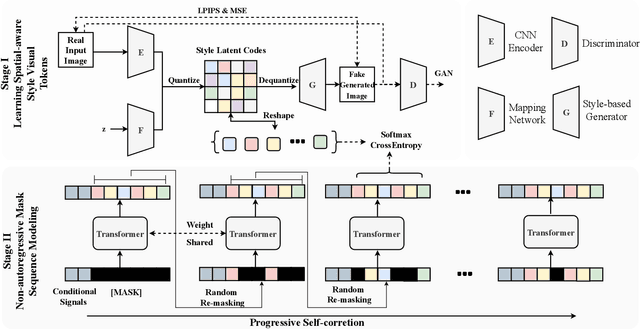
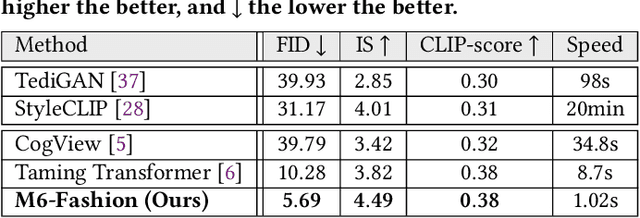

The fashion industry has diverse applications in multi-modal image generation and editing. It aims to create a desired high-fidelity image with the multi-modal conditional signal as guidance. Most existing methods learn different condition guidance controls by introducing extra models or ignoring the style prior knowledge, which is difficult to handle multiple signal combinations and faces a low-fidelity problem. In this paper, we adapt both style prior knowledge and flexibility of multi-modal control into one unified two-stage framework, M6-Fashion, focusing on the practical AI-aided Fashion design. It decouples style codes in both spatial and semantic dimensions to guarantee high-fidelity image generation in the first stage. M6-Fashion utilizes self-correction for the non-autoregressive generation to improve inference speed, enhance holistic consistency, and support various signal controls. Extensive experiments on a large-scale clothing dataset M2C-Fashion demonstrate superior performances on various image generation and editing tasks. M6-Fashion model serves as a highly potential AI designer for the fashion industry.
Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Feb 07, 2022

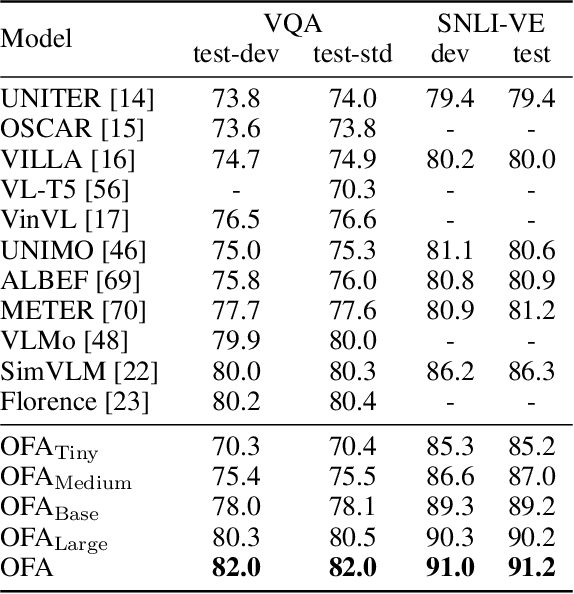

In this work, we pursue a unified paradigm for multimodal pretraining to break the scaffolds of complex task/modality-specific customization. We propose OFA, a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image generation, visual grounding, image captioning, image classification, text generation, etc.) to a simple sequence-to-sequence learning framework based on the encoder-decoder architecture. OFA performs pretraining and finetuning with task instructions and introduces no extra task-specific layers for finetuning. Experimental results show that OFA achieves new state-of-the-arts on a series of multimodal tasks, including image captioning (COCO test CIDEr: 149.6), text-to-image generation (COCO test FID: 10.5), VQA (test-std acc.: 80.02), SNLI-VE (test acc.: 90.20), and referring expression comprehension (RefCOCO / RefCOCO+ / RefCOCOg test acc.: 92.93 / 90.10 / 85.20). Through extensive analyses, we demonstrate that OFA reaches comparable performance with uni-modal pretrained models (e.g., BERT, MAE, MoCo v3, SimCLR v2, etc.) in uni-modal tasks, including NLU, NLG, and image classification, and it effectively transfers to unseen tasks and domains. Code shall be released soon at http://github.com/OFA-Sys/OFA
Cross-domain User Preference Learning for Cold-start Recommendation
Dec 07, 2021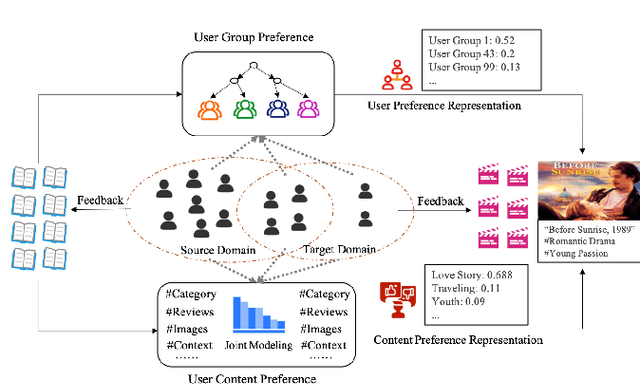
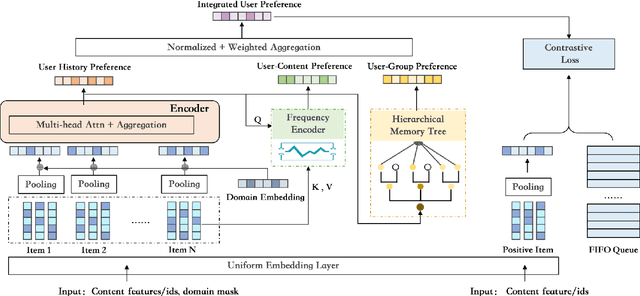
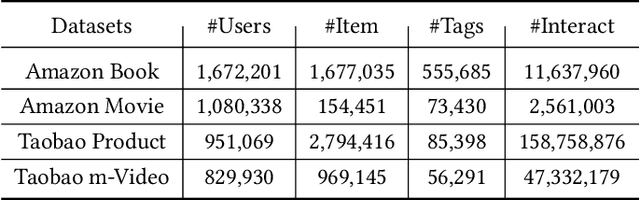
Cross-domain cold-start recommendation is an increasingly emerging issue for recommender systems. Existing works mainly focus on solving either cross-domain user recommendation or cold-start content recommendation. However, when a new domain evolves at its early stage, it has potential users similar to the source domain but with much fewer interactions. It is critical to learn a user's preference from the source domain and transfer it into the target domain, especially on the newly arriving contents with limited user feedback. To bridge this gap, we propose a self-trained Cross-dOmain User Preference LEarning (COUPLE) framework, targeting cold-start recommendation with various semantic tags, such as attributes of items or genres of videos. More specifically, we consider three levels of preferences, including user history, user content and user group to provide reliable recommendation. With user history represented by a domain-aware sequential model, a frequency encoder is applied to the underlying tags for user content preference learning. Then, a hierarchical memory tree with orthogonal node representation is proposed to further generalize user group preference across domains. The whole framework updates in a contrastive way with a First-In-First-Out (FIFO) queue to obtain more distinctive representations. Extensive experiments on two datasets demonstrate the efficiency of COUPLE in both user and content cold-start situations. By deploying an online A/B test for a week, we show that the Click-Through-Rate (CTR) of COUPLE is superior to other baselines used on Taobao APP. Now the method is serving online for the cross-domain cold micro-video recommendation.
UFC-BERT: Unifying Multi-Modal Controls for Conditional Image Synthesis
May 29, 2021


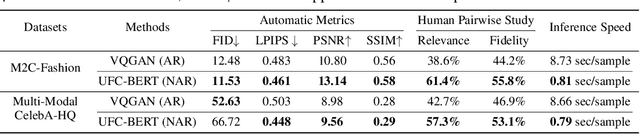
Conditional image synthesis aims to create an image according to some multi-modal guidance in the forms of textual descriptions, reference images, and image blocks to preserve, as well as their combinations. In this paper, instead of investigating these control signals separately, we propose a new two-stage architecture, UFC-BERT, to unify any number of multi-modal controls. In UFC-BERT, both the diverse control signals and the synthesized image are uniformly represented as a sequence of discrete tokens to be processed by Transformer. Different from existing two-stage autoregressive approaches such as DALL-E and VQGAN, UFC-BERT adopts non-autoregressive generation (NAR) at the second stage to enhance the holistic consistency of the synthesized image, to support preserving specified image blocks, and to improve the synthesis speed. Further, we design a progressive algorithm that iteratively improves the non-autoregressively generated image, with the help of two estimators developed for evaluating the compliance with the controls and evaluating the fidelity of the synthesized image, respectively. Extensive experiments on a newly collected large-scale clothing dataset M2C-Fashion and a facial dataset Multi-Modal CelebA-HQ verify that UFC-BERT can synthesize high-fidelity images that comply with flexible multi-modal controls.
M6: A Chinese Multimodal Pretrainer
Mar 02, 2021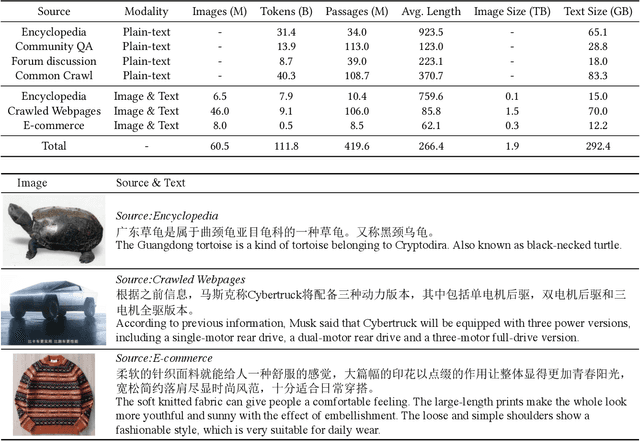
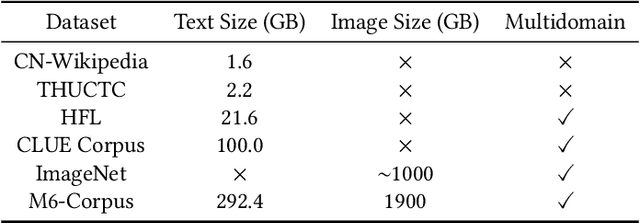

In this work, we construct the largest dataset for multimodal pretraining in Chinese, which consists of over 1.9TB images and 292GB texts that cover a wide range of domains. We propose a cross-modal pretraining method called M6, referring to Multi-Modality to Multi-Modality Multitask Mega-transformer, for unified pretraining on the data of single modality and multiple modalities. We scale the model size up to 10 billion and 100 billion parameters, and build the largest pretrained model in Chinese. We apply the model to a series of downstream applications, and demonstrate its outstanding performance in comparison with strong baselines. Furthermore, we specifically design a downstream task of text-guided image generation, and show that the finetuned M6 can create high-quality images with high resolution and abundant details.