 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Path Multi-Scale Transformer for High-Quality Image Deraining
May 28, 2024



Despite the superiority of convolutional neural networks (CNNs) and Transformers in single-image rain removal, current multi-scale models still face significant challenges due to their reliance on single-scale feature pyramid patterns. In this paper, we propose an effective rain removal method, the dual-path multi-scale Transformer (DPMformer) for high-quality image reconstruction by leveraging rich multi-scale information. This method consists of a backbone path and two branch paths from two different multi-scale approaches. Specifically, one path adopts the coarse-to-fine strategy, progressively downsampling the image to 1/2 and 1/4 scales, which helps capture fine-scale potential rain information fusion. Simultaneously, we employ the multi-patch stacked model (non-overlapping blocks of size 2 and 4) to enrich the feature information of the deep network in the other path. To learn a richer blend of features, the backbone path fully utilizes the multi-scale information to achieve high-quality rain removal image reconstruction. Extensive experiments on benchmark datasets demonstrate that our method achieves promising performance compared to other state-of-the-art methods.
RSDehamba: Lightweight Vision Mamba for Remote Sensing Satellite Image Dehazing
May 16, 2024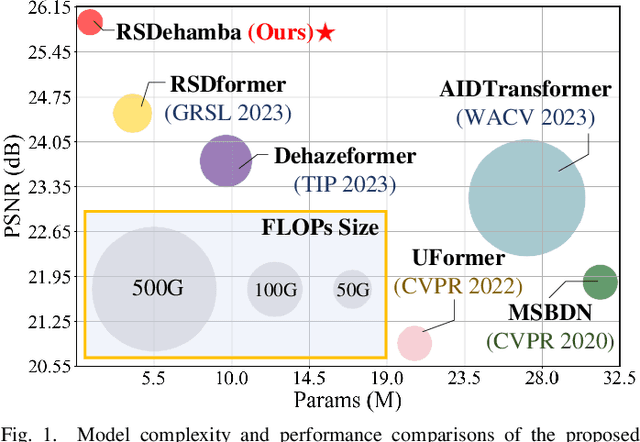
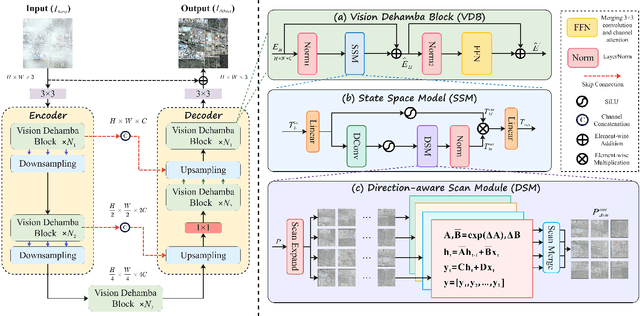
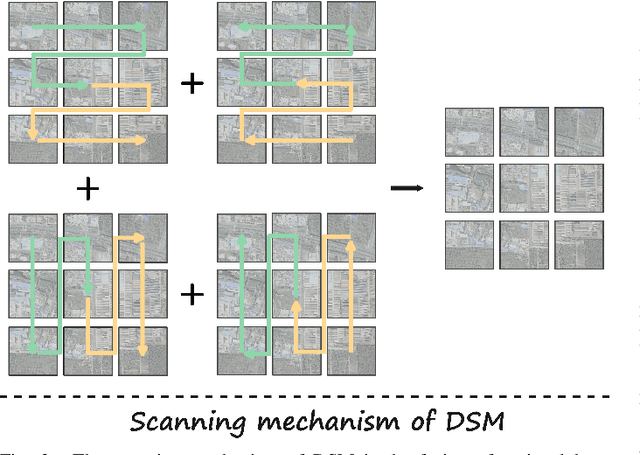
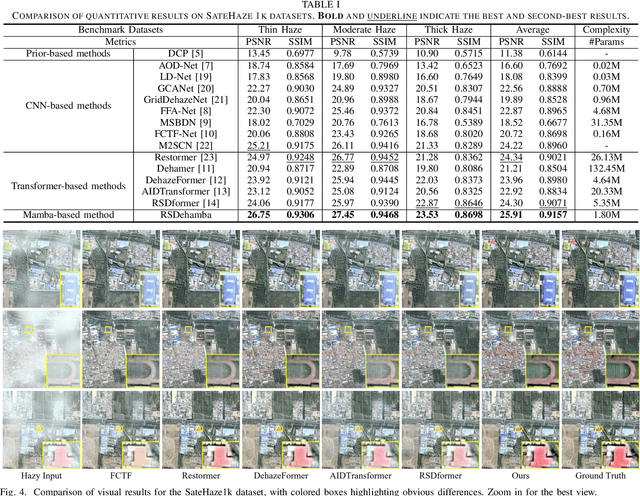
Remote sensing image dehazing (RSID) aims to remove nonuniform and physically irregular haze factors for high-quality image restoration. The emergence of CNNs and Transformers has taken extraordinary strides in the RSID arena. However, these methods often struggle to demonstrate the balance of adequate long-range dependency modeling and maintaining computational efficiency. To this end, we propose the first lightweight network on the mamba-based model called RSDhamba in the field of RSID. Greatly inspired by the recent rise of Selective State Space Model (SSM) for its superior performance in modeling linear complexity and remote dependencies, our designed RSDehamba integrates the SSM framework into the U-Net architecture. Specifically, we propose the Vision Dehamba Block (VDB) as the core component of the overall network, which utilizes the linear complexity of SSM to achieve the capability of global context encoding. Simultaneously, the Direction-aware Scan Module (DSM) is designed to dynamically aggregate feature exchanges over different directional domains to effectively enhance the flexibility of sensing the spatially varying distribution of haze. In this way, our RSDhamba fully demonstrates the superiority of spatial distance capture dependencies and channel information exchange for better extraction of haze features. Extensive experimental results on widely used benchmarks validate the surpassing performance of our RSDehamba against existing state-of-the-art methods.
Single Stage Virtual Try-on via Deformable Attention Flows
Jul 19, 2022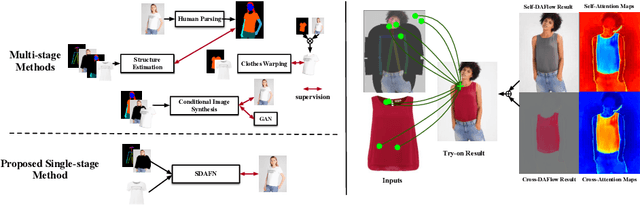

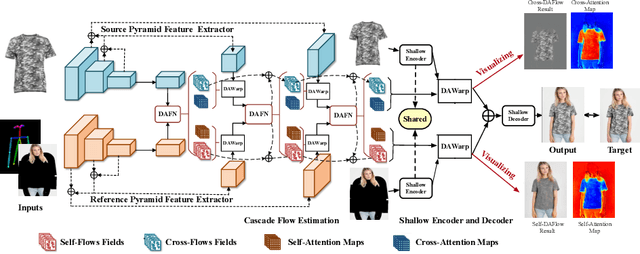
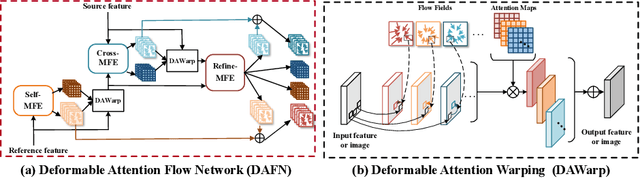
Virtual try-on aims to generate a photo-realistic fitting result given an in-shop garment and a reference person image. Existing methods usually build up multi-stage frameworks to deal with clothes warping and body blending respectively, or rely heavily on intermediate parser-based labels which may be noisy or even inaccurate. To solve the above challenges, we propose a single-stage try-on framework by developing a novel Deformable Attention Flow (DAFlow), which applies the deformable attention scheme to multi-flow estimation. With pose keypoints as the guidance only, the self- and cross-deformable attention flows are estimated for the reference person and the garment images, respectively. By sampling multiple flow fields, the feature-level and pixel-level information from different semantic areas are simultaneously extracted and merged through the attention mechanism. It enables clothes warping and body synthesizing at the same time which leads to photo-realistic results in an end-to-end manner. Extensive experiments on two try-on datasets demonstrate that our proposed method achieves state-of-the-art performance both qualitatively and quantitatively. Furthermore, additional experiments on the other two image editing tasks illustrate the versatility of our method for multi-view synthesis and image animation.
M6-Fashion: High-Fidelity Multi-modal Image Generation and Editing
May 24, 2022
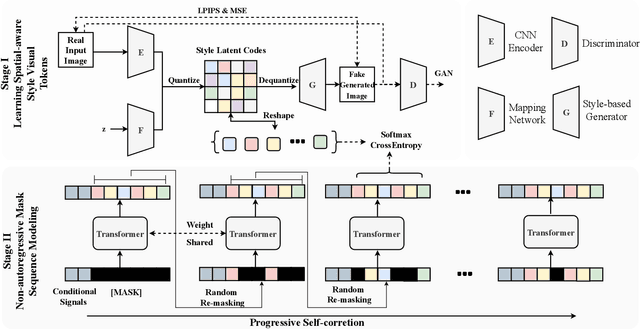
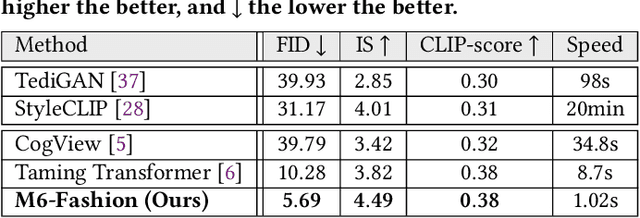

The fashion industry has diverse applications in multi-modal image generation and editing. It aims to create a desired high-fidelity image with the multi-modal conditional signal as guidance. Most existing methods learn different condition guidance controls by introducing extra models or ignoring the style prior knowledge, which is difficult to handle multiple signal combinations and faces a low-fidelity problem. In this paper, we adapt both style prior knowledge and flexibility of multi-modal control into one unified two-stage framework, M6-Fashion, focusing on the practical AI-aided Fashion design. It decouples style codes in both spatial and semantic dimensions to guarantee high-fidelity image generation in the first stage. M6-Fashion utilizes self-correction for the non-autoregressive generation to improve inference speed, enhance holistic consistency, and support various signal controls. Extensive experiments on a large-scale clothing dataset M2C-Fashion demonstrate superior performances on various image generation and editing tasks. M6-Fashion model serves as a highly potential AI designer for the fashion industry.
In-N-Out Generative Learning for Dense Unsupervised Video Segmentation
Apr 11, 2022
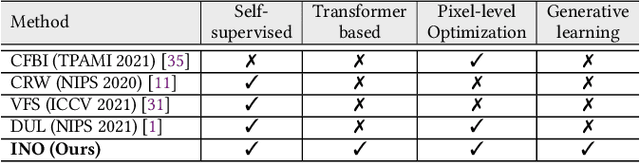
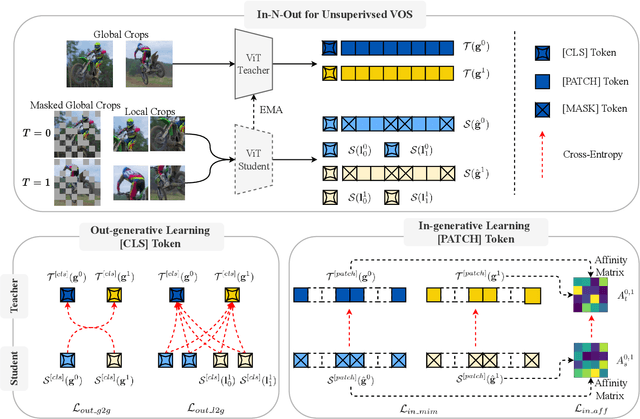
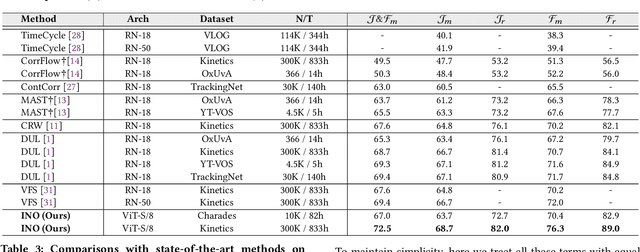
In this paper, we focus on the unsupervised learning for Video Object Segmentation (VOS) which learns visual correspondence (i.e., similarity between pixel-level features) from unlabeled videos. Previous methods are mainly based on the contrastive learning paradigm, which optimize either in image level or pixel level. Image-level optimization (e.g., the spatially pooled feature of ResNet) learns robust high-level semantics but is sub-optimal since the pixel-level features are optimized implicitly. By contrast, pixel-level optimization is more explicit, however, it is sensitive to the visual quality of training data and is not robust to object deformation. To complementarily perform these two levels of optimization in a unified framework, we propose the In-aNd-Out (INO) generative learning from a purely generative perspective with the help of naturally designed class tokens and patch tokens in Vision Transformer (ViT). Specifically, for image-level optimization, we force the out-view imagination from local to global views on class tokens, which helps capturing high-level semantics, and we name it as out-generative learning. As to pixel-level optimization, we perform in-view masked image modeling on patch tokens, which recovers the corrupted parts of an image via inferring its fine-grained structure, and we term it as in-generative learning. To better discover the temporal information, we additionally force the inter-frame consistency from both feature level and affinity matrix level. Extensive experiments on DAVIS-2017 val and YouTube-VOS 2018 val show that our INO outperforms previous state-of-the-art methods by significant margins.
Cross-domain User Preference Learning for Cold-start Recommendation
Dec 07, 2021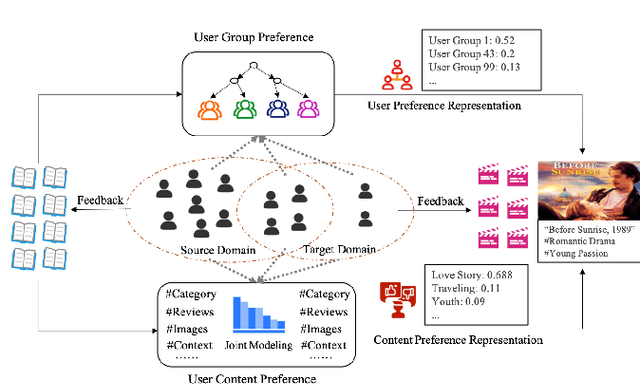
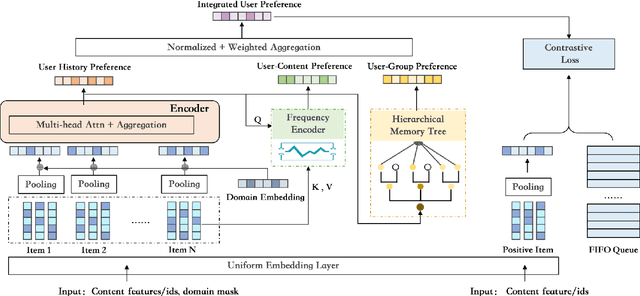
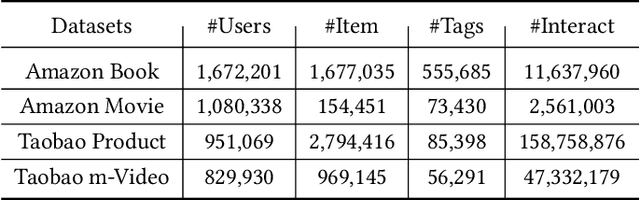
Cross-domain cold-start recommendation is an increasingly emerging issue for recommender systems. Existing works mainly focus on solving either cross-domain user recommendation or cold-start content recommendation. However, when a new domain evolves at its early stage, it has potential users similar to the source domain but with much fewer interactions. It is critical to learn a user's preference from the source domain and transfer it into the target domain, especially on the newly arriving contents with limited user feedback. To bridge this gap, we propose a self-trained Cross-dOmain User Preference LEarning (COUPLE) framework, targeting cold-start recommendation with various semantic tags, such as attributes of items or genres of videos. More specifically, we consider three levels of preferences, including user history, user content and user group to provide reliable recommendation. With user history represented by a domain-aware sequential model, a frequency encoder is applied to the underlying tags for user content preference learning. Then, a hierarchical memory tree with orthogonal node representation is proposed to further generalize user group preference across domains. The whole framework updates in a contrastive way with a First-In-First-Out (FIFO) queue to obtain more distinctive representations. Extensive experiments on two datasets demonstrate the efficiency of COUPLE in both user and content cold-start situations. By deploying an online A/B test for a week, we show that the Click-Through-Rate (CTR) of COUPLE is superior to other baselines used on Taobao APP. Now the method is serving online for the cross-domain cold micro-video recommendation.
M6: A Chinese Multimodal Pretrainer
Mar 02, 2021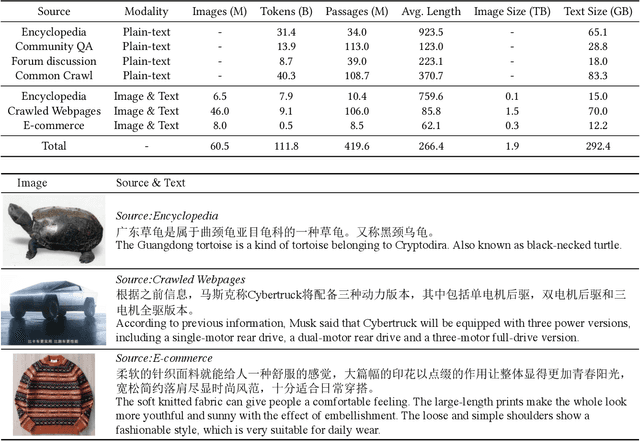
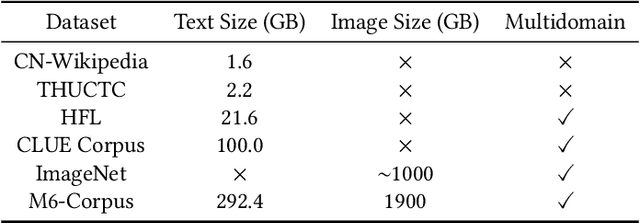

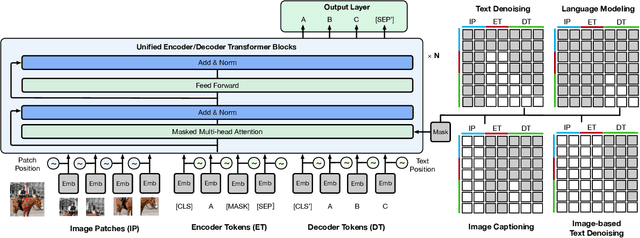
In this work, we construct the largest dataset for multimodal pretraining in Chinese, which consists of over 1.9TB images and 292GB texts that cover a wide range of domains. We propose a cross-modal pretraining method called M6, referring to Multi-Modality to Multi-Modality Multitask Mega-transformer, for unified pretraining on the data of single modality and multiple modalities. We scale the model size up to 10 billion and 100 billion parameters, and build the largest pretrained model in Chinese. We apply the model to a series of downstream applications, and demonstrate its outstanding performance in comparison with strong baselines. Furthermore, we specifically design a downstream task of text-guided image generation, and show that the finetuned M6 can create high-quality images with high resolution and abundant details.
Network Clustering for Multi-task Learning
Jan 22, 2021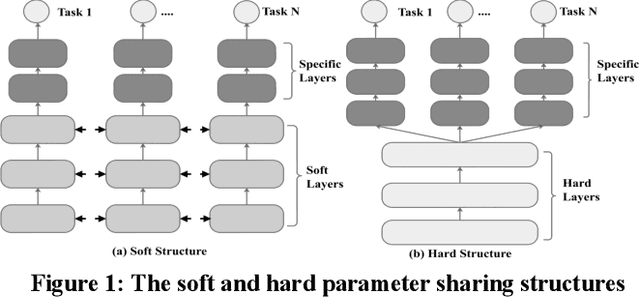
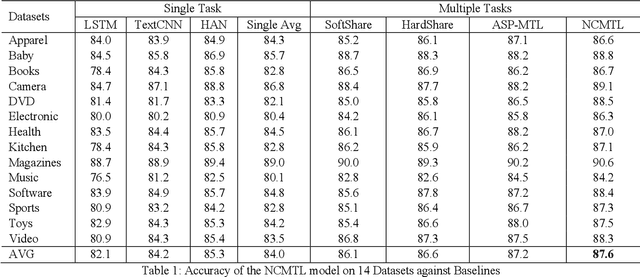
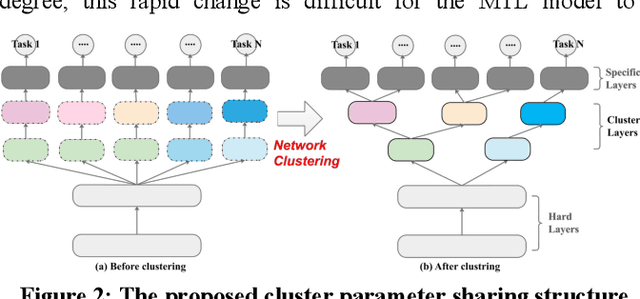
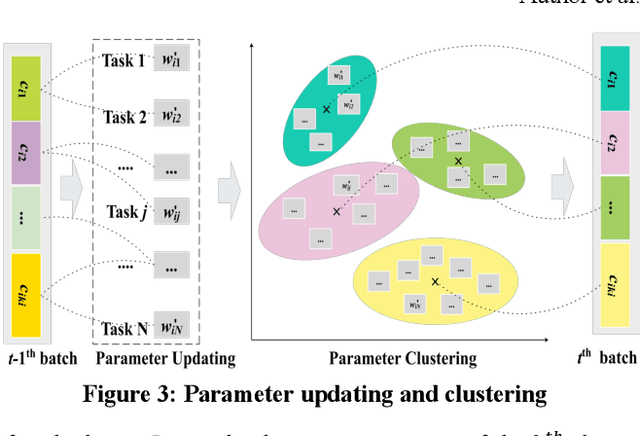
The Multi-Task Learning (MTL) technique has been widely studied by word-wide researchers. The majority of current MTL studies adopt the hard parameter sharing structure, where hard layers tend to learn general representations over all tasks and specific layers are prone to learn specific representations for each task. Since the specific layers directly follow the hard layers, the MTL model needs to estimate this direct change (from general to specific) as well. To alleviate this problem, we introduce the novel cluster layer, which groups tasks into clusters during training procedures. In a cluster layer, the tasks in the same cluster are further required to share the same network. By this way, the cluster layer produces the general presentation for the same cluster, while produces relatively specific presentations for different clusters. As transitions the cluster layers are used between the hard layers and the specific layers. The MTL model thus learns general representations to specific representations gradually. We evaluate our model with MTL document classification and the results demonstrate the cluster layer is quite efficient in MTL.
Deep Hierarchical Classification for Category Prediction in E-commerce System
May 14, 2020
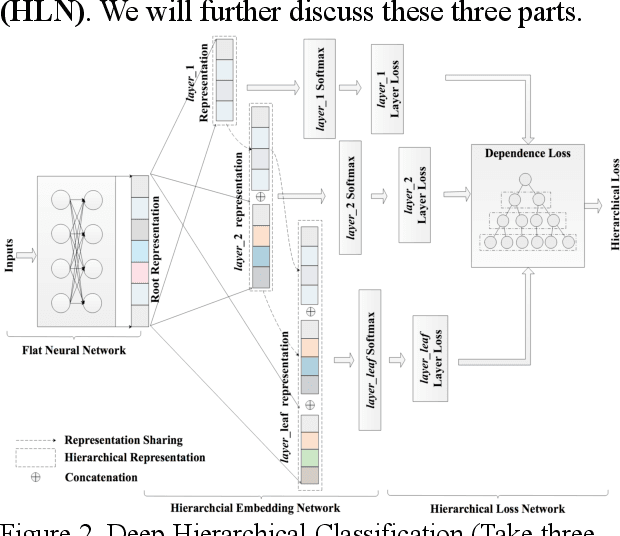
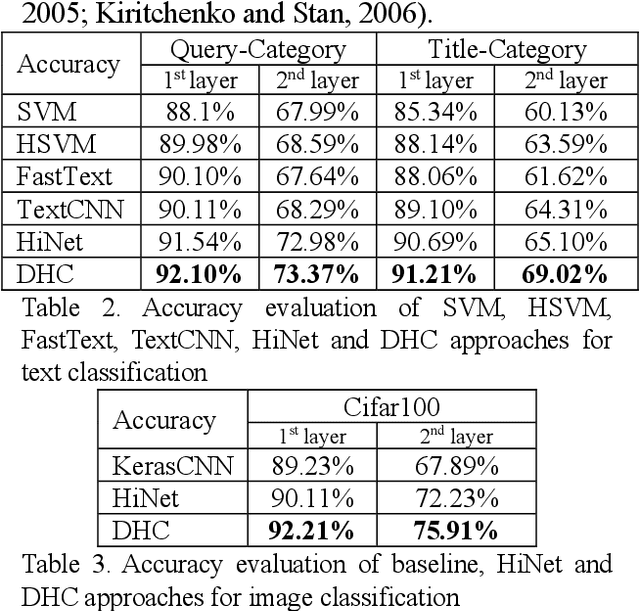
In e-commerce system, category prediction is to automatically predict categories of given texts. Different from traditional classification where there are no relations between classes, category prediction is reckoned as a standard hierarchical classification problem since categories are usually organized as a hierarchical tree. In this paper, we address hierarchical category prediction. We propose a Deep Hierarchical Classification framework, which incorporates the multi-scale hierarchical information in neural networks and introduces a representation sharing strategy according to the category tree. We also define a novel combined loss function to punish hierarchical prediction losses. The evaluation shows that the proposed approach outperforms existing approaches in accuracy.