 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
Using generative AI to investigate medical imagery models and datasets
Jun 01, 2023
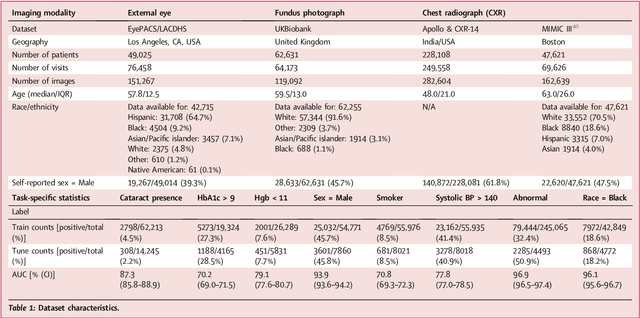


AI models have shown promise in many medical imaging tasks. However, our ability to explain what signals these models have learned is severely lacking. Explanations are needed in order to increase the trust in AI-based models, and could enable novel scientific discovery by uncovering signals in the data that are not yet known to experts. In this paper, we present a method for automatic visual explanations leveraging team-based expertise by generating hypotheses of what visual signals in the images are correlated with the task. We propose the following 4 steps: (i) Train a classifier to perform a given task (ii) Train a classifier guided StyleGAN-based image generator (StylEx) (iii) Automatically detect and visualize the top visual attributes that the classifier is sensitive towards (iv) Formulate hypotheses for the underlying mechanisms, to stimulate future research. Specifically, we present the discovered attributes to an interdisciplinary panel of experts so that hypotheses can account for social and structural determinants of health. We demonstrate results on eight prediction tasks across three medical imaging modalities: retinal fundus photographs, external eye photographs, and chest radiographs. We showcase examples of attributes that capture clinically known features, confounders that arise from factors beyond physiological mechanisms, and reveal a number of physiologically plausible novel attributes. Our approach has the potential to enable researchers to better understand, improve their assessment, and extract new knowledge from AI-based models. Importantly, we highlight that attributes generated by our framework can capture phenomena beyond physiology or pathophysiology, reflecting the real world nature of healthcare delivery and socio-cultural factors. Finally, we intend to release code to enable researchers to train their own StylEx models and analyze their predictive tasks.
AI system for fetal ultrasound in low-resource settings
Mar 18, 2022
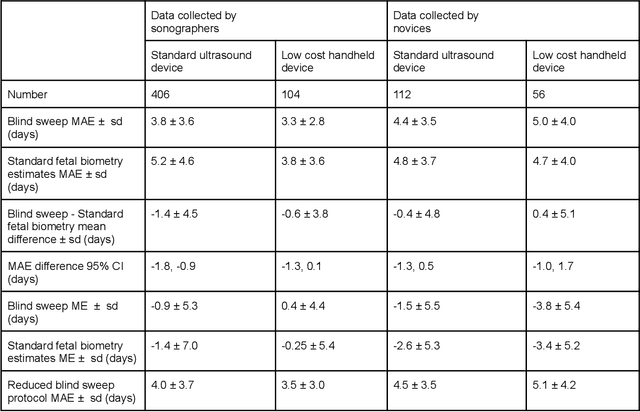

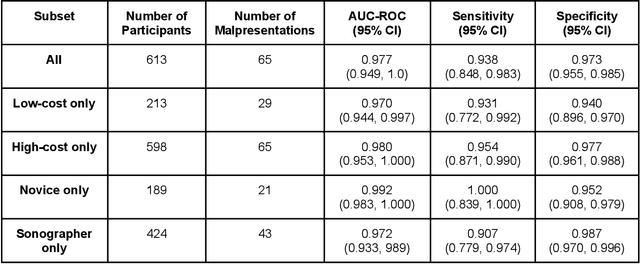
Despite considerable progress in maternal healthcare, maternal and perinatal deaths remain high in low-to-middle income countries. Fetal ultrasound is an important component of antenatal care, but shortage of adequately trained healthcare workers has limited its adoption. We developed and validated an artificial intelligence (AI) system that uses novice-acquired "blind sweep" ultrasound videos to estimate gestational age (GA) and fetal malpresentation. We further addressed obstacles that may be encountered in low-resourced settings. Using a simplified sweep protocol with real-time AI feedback on sweep quality, we have demonstrated the generalization of model performance to minimally trained novice ultrasound operators using low cost ultrasound devices with on-device AI integration. The GA model was non-inferior to standard fetal biometry estimates with as few as two sweeps, and the fetal malpresentation model had high AUC-ROCs across operators and devices. Our AI models have the potential to assist in upleveling the capabilities of lightly trained ultrasound operators in low resource settings.
Deep learning for detecting pulmonary tuberculosis via chest radiography: an international study across 10 countries
May 16, 2021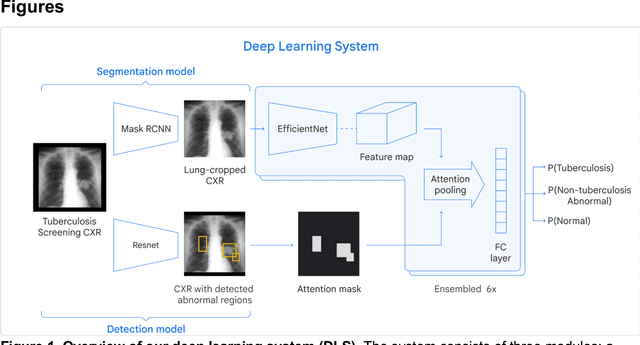
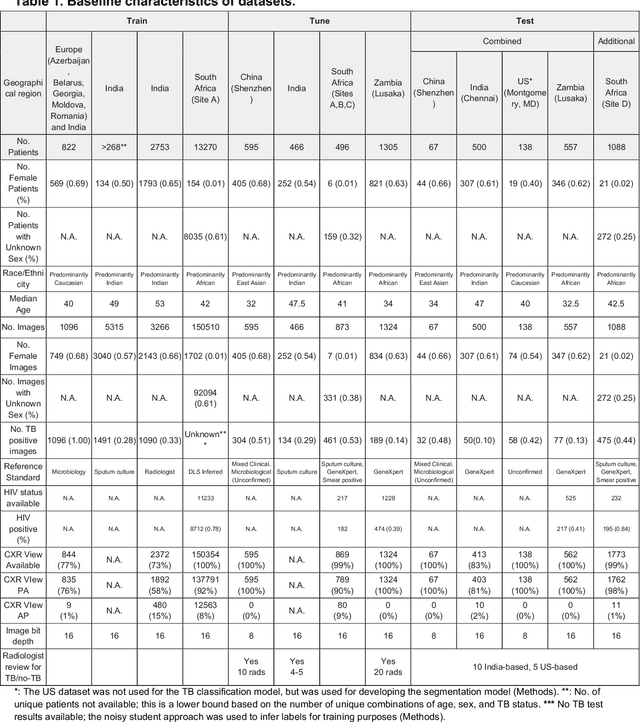
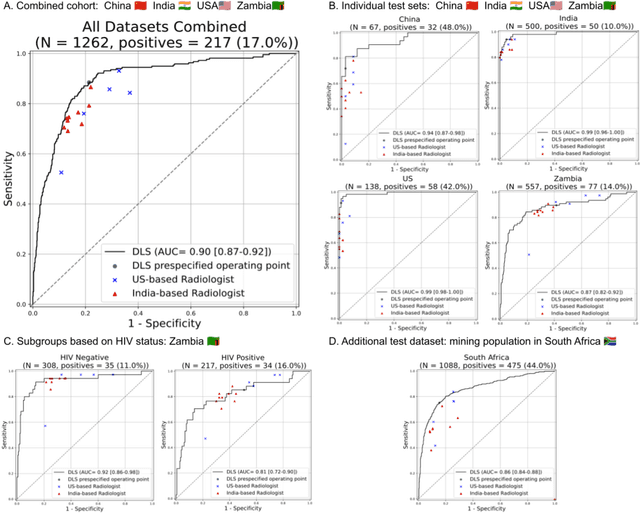
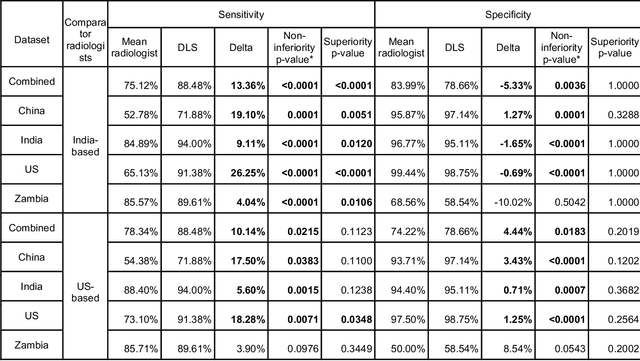
Tuberculosis (TB) is a top-10 cause of death worldwide. Though the WHO recommends chest radiographs (CXRs) for TB screening, the limited availability of CXR interpretation is a barrier. We trained a deep learning system (DLS) to detect active pulmonary TB using CXRs from 9 countries across Africa, Asia, and Europe, and utilized large-scale CXR pretraining, attention pooling, and noisy student semi-supervised learning. Evaluation was on (1) a combined test set spanning China, India, US, and Zambia, and (2) an independent mining population in South Africa. Given WHO targets of 90% sensitivity and 70% specificity, the DLS's operating point was prespecified to favor sensitivity over specificity. On the combined test set, the DLS's ROC curve was above all 9 India-based radiologists, with an AUC of 0.90 (95%CI 0.87-0.92). The DLS's sensitivity (88%) was higher than the India-based radiologists (75% mean sensitivity), p<0.001 for superiority; and its specificity (79%) was non-inferior to the radiologists (84% mean specificity), p=0.004. Similar trends were observed within HIV positive and sputum smear positive sub-groups, and in the South Africa test set. We found that 5 US-based radiologists (where TB isn't endemic) were more sensitive and less specific than the India-based radiologists (where TB is endemic). The DLS also remained non-inferior to the US-based radiologists. In simulations, using the DLS as a prioritization tool for confirmatory testing reduced the cost per positive case detected by 40-80% compared to using confirmatory testing alone. To conclude, our DLS generalized to 5 countries, and merits prospective evaluation to assist cost-effective screening efforts in radiologist-limited settings. Operating point flexibility may permit customization of the DLS to account for site-specific factors such as TB prevalence, demographics, clinical resources, and customary practice patterns.
Deep Learning for Distinguishing Normal versus Abnormal Chest Radiographs and Generalization to Unseen Diseases
Oct 22, 2020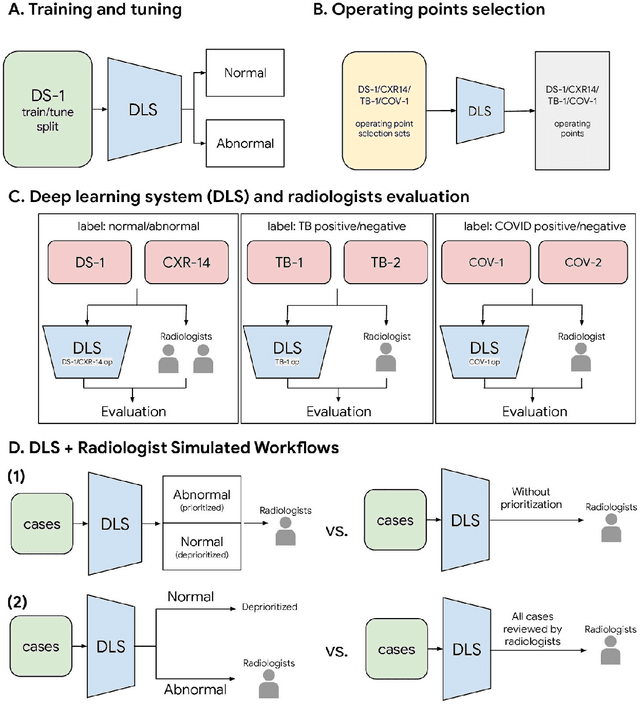
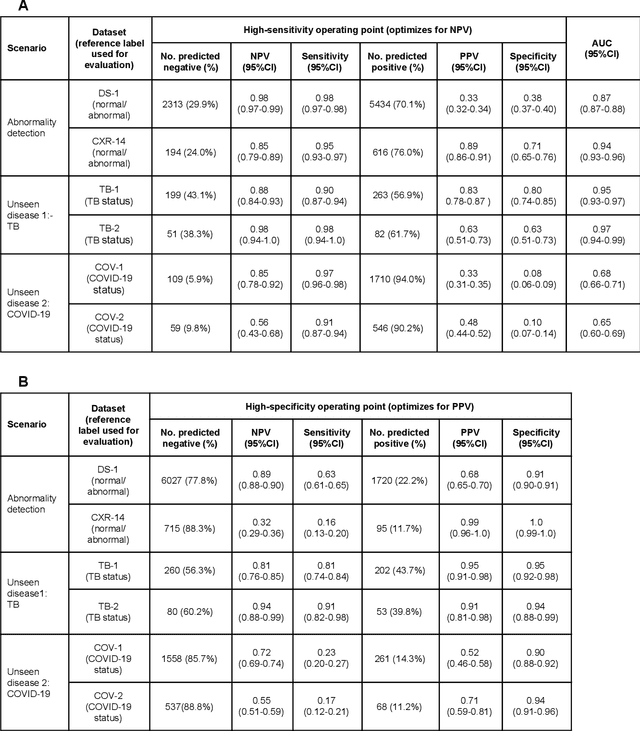
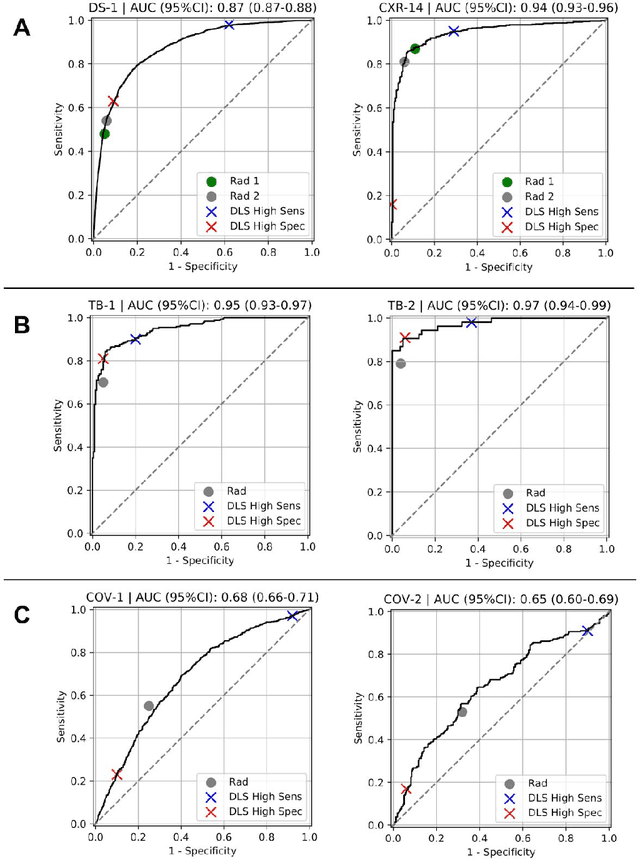
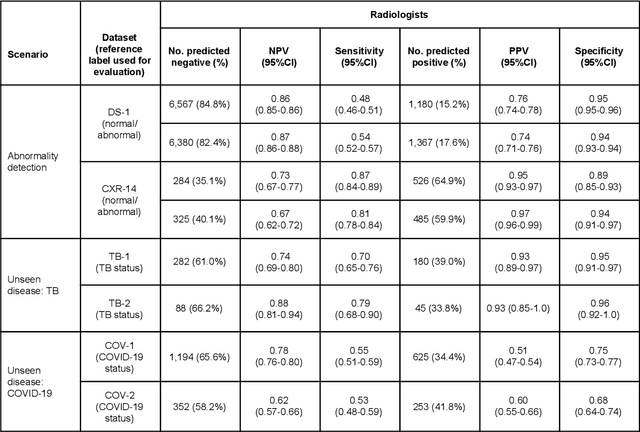
Chest radiography (CXR) is the most widely-used thoracic clinical imaging modality and is crucial for guiding the management of cardiothoracic conditions. The detection of specific CXR findings has been the main focus of several artificial intelligence (AI) systems. However, the wide range of possible CXR abnormalities makes it impractical to build specific systems to detect every possible condition. In this work, we developed and evaluated an AI system to classify CXRs as normal or abnormal. For development, we used a de-identified dataset of 248,445 patients from a multi-city hospital network in India. To assess generalizability, we evaluated our system using 6 international datasets from India, China, and the United States. Of these datasets, 4 focused on diseases that the AI was not trained to detect: 2 datasets with tuberculosis and 2 datasets with coronavirus disease 2019. Our results suggest that the AI system generalizes to new patient populations and abnormalities. In a simulated workflow where the AI system prioritized abnormal cases, the turnaround time for abnormal cases reduced by 7-28%. These results represent an important step towards evaluating whether AI can be safely used to flag cases in a general setting where previously unseen abnormalities exist.