 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Retrieval as Indirect Supervision for Large-space Decision Making
Oct 28, 2023



Many discriminative natural language understanding (NLU) tasks have large label spaces. Learning such a process of large-space decision making is particularly challenging due to the lack of training instances per label and the difficulty of selection among many fine-grained labels. Inspired by dense retrieval methods for passage finding in open-domain QA, we propose a reformulation of large-space discriminative NLU tasks as a learning-to-retrieve task, leading to a novel solution named Dense Decision Retrieval (DDR ). Instead of predicting fine-grained decisions as logits, DDR adopts a dual-encoder architecture that learns to predict by retrieving from a decision thesaurus. This approach not only leverages rich indirect supervision signals from easy-to-consume learning resources for dense retrieval, it also leads to enhanced prediction generalizability with a semantically meaningful representation of the large decision space. When evaluated on tasks with decision spaces ranging from hundreds to hundred-thousand scales, DDR outperforms strong baselines greatly by 27.54% in P@1 on two extreme multi-label classification tasks, 1.17% in F1 score ultra-fine entity typing, and 1.26% in accuracy on three few-shot intent classification tasks on average. Code and resources are available at https://github.com/luka-group/DDR
RGB-T Tracking Based on Mixed Attention
Apr 18, 2023



RGB-T tracking involves the use of images from both visible and thermal modalities. The primary objective is to adaptively leverage the relatively dominant modality in varying conditions to achieve more robust tracking compared to single-modality tracking. An RGB-T tracker based on mixed attention mechanism to achieve complementary fusion of modalities (referred to as MACFT) is proposed in this paper. In the feature extraction stage, we utilize different transformer backbone branches to extract specific and shared information from different modalities. By performing mixed attention operations in the backbone to enable information interaction and self-enhancement between the template and search images, it constructs a robust feature representation that better understands the high-level semantic features of the target. Then, in the feature fusion stage, a modality-adaptive fusion is achieved through a mixed attention-based modality fusion network, which suppresses the low-quality modality noise while enhancing the information of the dominant modality. Evaluation on multiple RGB-T public datasets demonstrates that our proposed tracker outperforms other RGB-T trackers on general evaluation metrics while also being able to adapt to longterm tracking scenarios.
Does Your Model Classify Entities Reasonably? Diagnosing and Mitigating Spurious Correlations in Entity Typing
May 25, 2022
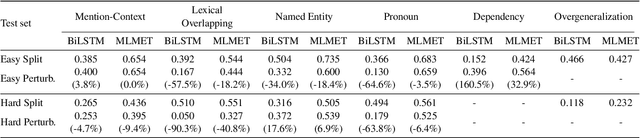

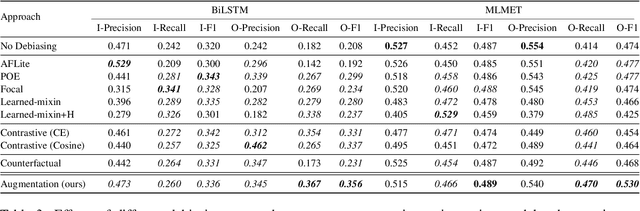
The entity typing task aims at predicting one or more words or phrases that describe the type(s) of a specific mention in a sentence. Due to shortcuts from surface patterns to annotated entity labels and biased training, existing entity typing models are subject to the problem of spurious correlations. To comprehensively investigate the faithfulness and reliability of entity typing methods, we first systematically define distinct kinds of model biases that are reflected mainly from spurious correlations. Particularly, we identify six types of existing model biases, including mention-context bias, lexical overlapping bias, named entity bias, pronoun bias, dependency bias, and overgeneralization bias. To mitigate these model biases, we then introduce a counterfactual data augmentation method. By augmenting the original training set with their bias-free counterparts, models are forced to fully comprehend the sentences and discover the fundamental cues for entity typing, rather than relying on spurious correlations for shortcuts. Experimental results on the UFET dataset show that our counterfactual data augmentation approach helps improve generalization of different entity typing models with consistently better performance on both in- and out-of-distribution test sets.
HAR-Net:Fusing Deep Representation and Hand-crafted Features for Human Activity Recognition
Oct 25, 2018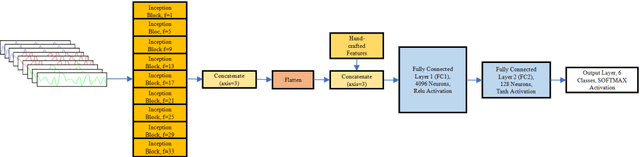


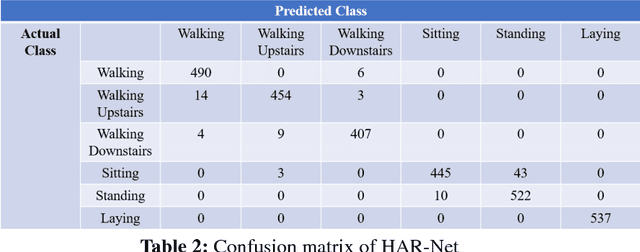
Wearable computing and context awareness are the focuses of study in the field of artificial intelligence recently. One of the most appealing as well as challenging applications is the Human Activity Recognition (HAR) utilizing smart phones. Conventional HAR based on Support Vector Machine relies on subjective manually extracted features. This approach is time and energy consuming as well as immature in prediction due to the partial view toward which features to be extracted by human. With the rise of deep learning, artificial intelligence has been making progress toward being a mature technology. This paper proposes a new approach based on deep learning and traditional feature engineering called HAR-Net to address the issue related to HAR. The study used the data collected by gyroscopes and acceleration sensors in android smart phones. The raw sensor data was put into the HAR-Net proposed. The HAR-Net fusing the hand-crafted features and high-level features extracted from convolutional network to make prediction. The performance of the proposed method was proved to be 0.9% higher than the original MC-SVM approach. The experimental results on the UCI dataset demonstrate that fusing the two kinds of features can make up for the shortage of traditional feature engineering and deep learning techniques.