 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Your Model Classify Entities Reasonably? Diagnosing and Mitigating Spurious Correlations in Entity Typing
Paper and Code

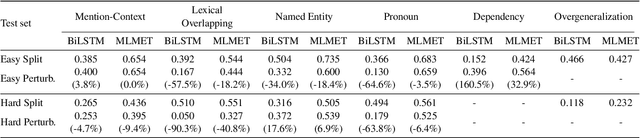

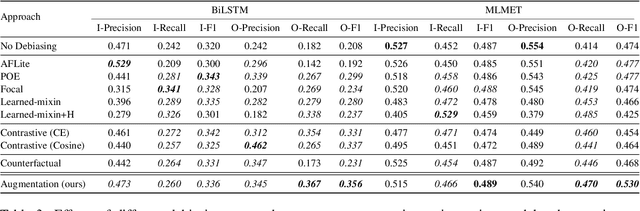
The entity typing task aims at predicting one or more words or phrases that describe the type(s) of a specific mention in a sentence. Due to shortcuts from surface patterns to annotated entity labels and biased training, existing entity typing models are subject to the problem of spurious correlations. To comprehensively investigate the faithfulness and reliability of entity typing methods, we first systematically define distinct kinds of model biases that are reflected mainly from spurious correlations. Particularly, we identify six types of existing model biases, including mention-context bias, lexical overlapping bias, named entity bias, pronoun bias, dependency bias, and overgeneralization bias. To mitigate these model biases, we then introduce a counterfactual data augmentation method. By augmenting the original training set with their bias-free counterparts, models are forced to fully comprehend the sentences and discover the fundamental cues for entity typing, rather than relying on spurious correlations for shortcuts. Experimental results on the UFET dataset show that our counterfactual data augmentation approach helps improve generalization of different entity typing models with consistently better performance on both in- and out-of-distribution test sets.