 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Agentic Optimization on Large Codebases
Mar 16, 2026Large language model (LLM) coding agents increasingly operate at the repository level, motivating benchmarks that evaluate their ability to optimize entire codebases under realistic constraints. Existing code benchmarks largely rely on synthetic tasks, binary correctness signals, or single-objective evaluation, limiting their ability to assess holistic optimization behavior. We introduce FormulaCode, a benchmark for evaluating agentic optimization on large, real-world codebases with fine-grained, multi-objective performance metrics. FormulaCode comprises 957 performance bottlenecks mined from scientific Python repositories on GitHub, each paired with expert-authored patches and, on average, 264.6 community-maintained performance workloads per task, enabling the holistic ability of LLM agents to optimize codebases under realistic correctness and performance constraints. Our evaluations reveal that repository-scale, multi-objective optimization remains a major challenge for frontier LLM agents. Project website at: https://formula-code.github.io
ForeAct: Steering Your VLA with Efficient Visual Foresight Planning
Feb 12, 2026Vision-Language-Action (VLA) models convert high-level language instructions into concrete, executable actions, a task that is especially challenging in open-world environments. We present Visual Foresight Planning (ForeAct), a general and efficient planner that guides a VLA step-by-step using imagined future observations and subtask descriptions. With an imagined future observation, the VLA can focus on visuo-motor inference rather than high-level semantic reasoning, leading to improved accuracy and generalization. Our planner comprises a highly efficient foresight image generation module that predicts a high-quality 640$\times$480 future observation from the current visual input and language instruction within only 0.33s on an H100 GPU, together with a vision-language model that reasons over the task and produces subtask descriptions for both the generator and the VLA. Importantly, state-of-the-art VLAs can integrate our planner seamlessly by simply augmenting their visual inputs, without any architectural modification. The foresight generator is pretrained on over 1 million multi-task, cross-embodiment episodes, enabling it to learn robust embodied dynamics. We evaluate our framework on a benchmark that consists of 11 diverse, multi-step real-world tasks. It achieves an average success rate of 87.4%, demonstrating a +40.9% absolute improvement over the $π_0$ baseline (46.5%) and a +30.3% absolute improvement over $π_0$ augmented with textual subtask guidance (57.1%).
Near-real-time Earthquake-induced Fatality Estimation using Crowdsourced Data and Large-Language Models
Dec 04, 2023When a damaging earthquake occurs, immediate information about casualties is critical for time-sensitive decision-making by emergency response and aid agencies in the first hours and days. Systems such as Prompt Assessment of Global Earthquakes for Response (PAGER) by the U.S. Geological Survey (USGS) were developed to provide a forecast within about 30 minutes of any significant earthquake globally. Traditional systems for estimating human loss in disasters often depend on manually collected early casualty reports from global media, a process that's labor-intensive and slow with notable time delays. Recently, some systems have employed keyword matching and topic modeling to extract relevant information from social media. However, these methods struggle with the complex semantics in multilingual texts and the challenge of interpreting ever-changing, often conflicting reports of death and injury numbers from various unverified sources on social media platforms. In this work, we introduce an end-to-end framework to significantly improve the timeliness and accuracy of global earthquake-induced human loss forecasting using multi-lingual, crowdsourced social media. Our framework integrates (1) a hierarchical casualty extraction model built upon large language models, prompt design, and few-shot learning to retrieve quantitative human loss claims from social media, (2) a physical constraint-aware, dynamic-truth discovery model that discovers the truthful human loss from massive noisy and potentially conflicting human loss claims, and (3) a Bayesian updating loss projection model that dynamically updates the final loss estimation using discovered truths. We test the framework in real-time on a series of global earthquake events in 2021 and 2022 and show that our framework streamlines casualty data retrieval, achieving speed and accuracy comparable to manual methods by USGS.
Point Cloud Recognition with Position-to-Structure Attention Transformers
Oct 05, 2022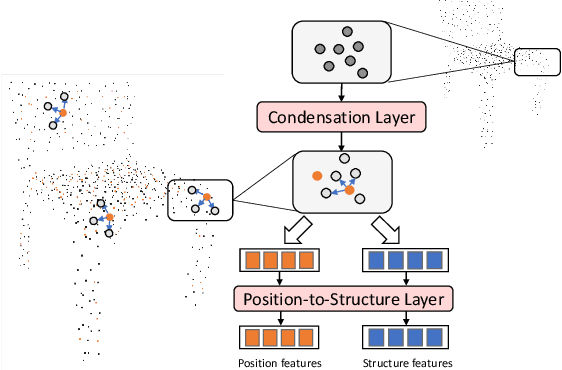
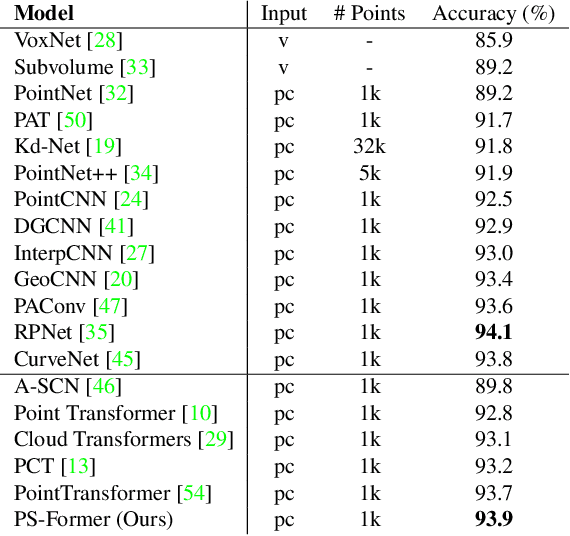
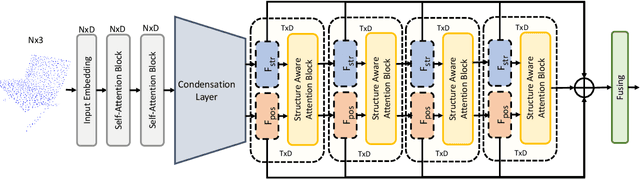
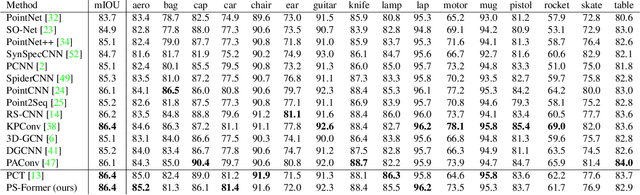
In this paper, we present Position-to-Structure Attention Transformers (PS-Former), a Transformer-based algorithm for 3D point cloud recognition. PS-Former deals with the challenge in 3D point cloud representation where points are not positioned in a fixed grid structure and have limited feature description (only 3D coordinates ($x, y, z$) for scattered points). Existing Transformer-based architectures in this domain often require a pre-specified feature engineering step to extract point features. Here, we introduce two new aspects in PS-Former: 1) a learnable condensation layer that performs point downsampling and feature extraction; and 2) a Position-to-Structure Attention mechanism that recursively enriches the structural information with the position attention branch. Compared with the competing methods, while being generic with less heuristics feature designs, PS-Former demonstrates competitive experimental results on three 3D point cloud tasks including classification, part segmentation, and scene segmentation.