 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Recognition with Position-to-Structure Attention Transformers
Paper and Code
Oct 05, 2022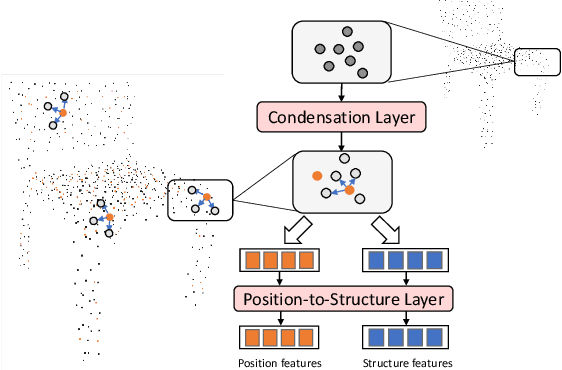
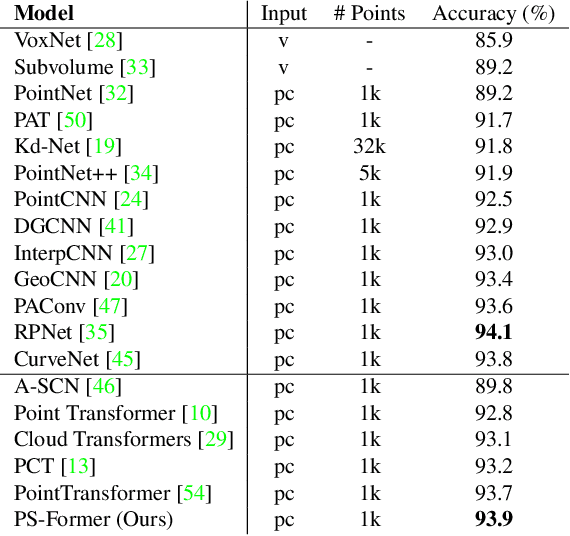
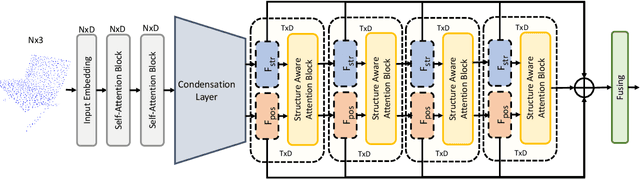
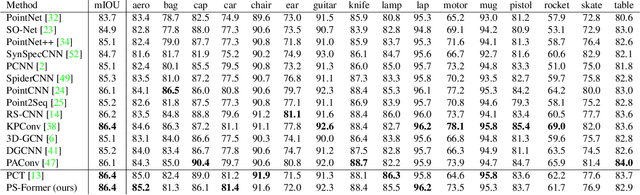
In this paper, we present Position-to-Structure Attention Transformers (PS-Former), a Transformer-based algorithm for 3D point cloud recognition. PS-Former deals with the challenge in 3D point cloud representation where points are not positioned in a fixed grid structure and have limited feature description (only 3D coordinates ($x, y, z$) for scattered points). Existing Transformer-based architectures in this domain often require a pre-specified feature engineering step to extract point features. Here, we introduce two new aspects in PS-Former: 1) a learnable condensation layer that performs point downsampling and feature extraction; and 2) a Position-to-Structure Attention mechanism that recursively enriches the structural information with the position attention branch. Compared with the competing methods, while being generic with less heuristics feature designs, PS-Former demonstrates competitive experimental results on three 3D point cloud tasks including classification, part segmentation, and scene segmentation.