 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box Adaptation of ASR for Accented Speech
Paper and Code

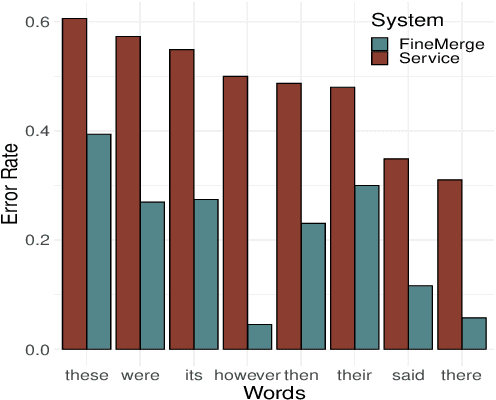


We introduce the problem of adapting a black-box, cloud-based ASR system to speech from a target accent. While leading online ASR services obtain impressive performance on main-stream accents, they perform poorly on sub-populations - we observed that the word error rate (WER) achieved by Google's ASR API on Indian accents is almost twice the WER on US accents. Existing adaptation methods either require access to model parameters or overlay an error-correcting module on output transcripts. We highlight the need for correlating outputs with the original speech to fix accent errors. Accordingly, we propose a novel coupling of an open-source accent-tuned local model with the black-box service where the output from the service guides frame-level inference in the local model. Our fine-grained merging algorithm is better at fixing accent errors than existing word-level combination strategies. Experiments on Indian and Australian accents with three leading ASR models as service, show that we achieve as much as 28% relative reduction in WER over both the local and service models.