 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Clinical Benchmark for Emergency Care (MC-BEC): A Comprehensive Benchmark for Evaluating Foundation Models in Emergency Medicine
Nov 07, 2023We propose the Multimodal Clinical Benchmark for Emergency Care (MC-BEC), a comprehensive benchmark for evaluating foundation models in Emergency Medicine using a dataset of 100K+ continuously monitored Emergency Department visits from 2020-2022. MC-BEC focuses on clinically relevant prediction tasks at timescales from minutes to days, including predicting patient decompensation, disposition, and emergency department (ED) revisit, and includes a standardized evaluation framework with train-test splits and evaluation metrics. The multimodal dataset includes a wide range of detailed clinical data, including triage information, prior diagnoses and medications, continuously measured vital signs, electrocardiogram and photoplethysmograph waveforms, orders placed and medications administered throughout the visit, free-text reports of imaging studies, and information on ED diagnosis, disposition, and subsequent revisits. We provide performance baselines for each prediction task to enable the evaluation of multimodal, multitask models. We believe that MC-BEC will encourage researchers to develop more effective, generalizable, and accessible foundation models for multimodal clinical data.
Error-driven Fixed-Budget ASR Personalization for Accented Speakers
Mar 04, 2021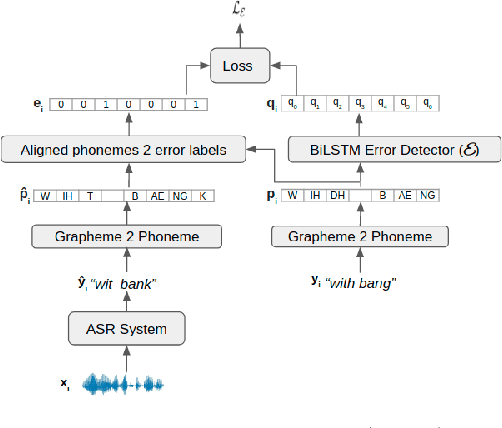
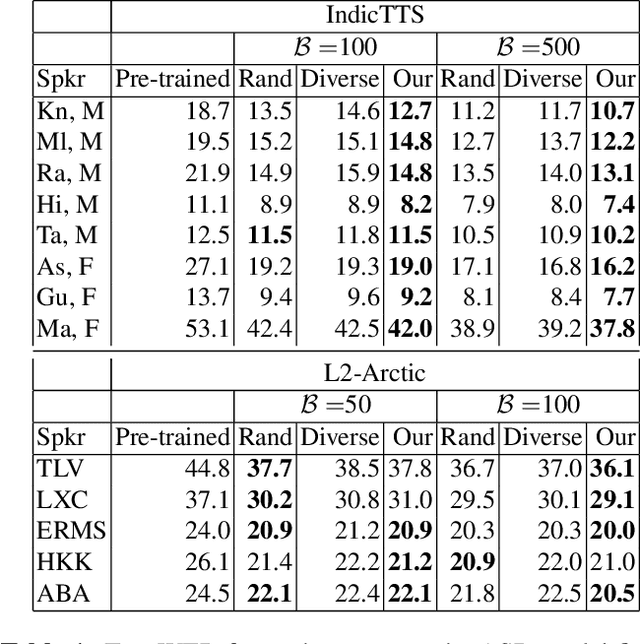


We consider the task of personalizing ASR models while being constrained by a fixed budget on recording speaker-specific utterances. Given a speaker and an ASR model, we propose a method of identifying sentences for which the speaker's utterances are likely to be harder for the given ASR model to recognize. We assume a tiny amount of speaker-specific data to learn phoneme-level error models which help us select such sentences. We show that speaker's utterances on the sentences selected using our error model indeed have larger error rates when compared to speaker's utterances on randomly selected sentences. We find that fine-tuning the ASR model on the sentence utterances selected with the help of error models yield higher WER improvements in comparison to fine-tuning on an equal number of randomly selected sentence utterances. Thus, our method provides an efficient way of collecting speaker utterances under budget constraints for personalizing ASR models.