 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Multilingual Semantic Parsers using Large Language Models
Paper and Code
Oct 13, 2022
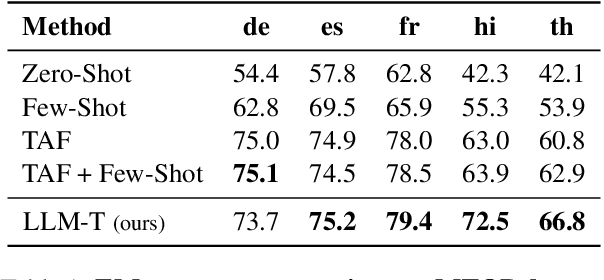

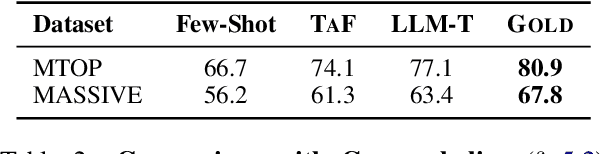
Despite cross-lingual generalization demonstrated by pre-trained multilingual models, the translate-train paradigm of transferring English datasets across multiple languages remains to be the key ingredient for training task-specific multilingual models. However, for many low-resource languages, the availability of a reliable translation service entails significant amounts of costly human-annotated translation pairs. Further, the translation services for low-resource languages may continue to be brittle due to domain mismatch between the task-specific input text and the general-purpose text used while training the translation models. We consider the task of multilingual semantic parsing and demonstrate the effectiveness and flexibility offered by large language models (LLMs) for translating English datasets into several languages via few-shot prompting. We provide (i) Extensive comparisons with prior translate-train methods across 50 languages demonstrating that LLMs can serve as highly effective data translators, outperforming prior translation based methods on 40 out of 50 languages; (ii) A comprehensive study of the key design choices that enable effective data translation via prompted LLMs.