 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's in a Name? Are BERT Named Entity Representations just as Good for any other Name?
Jul 14, 2020


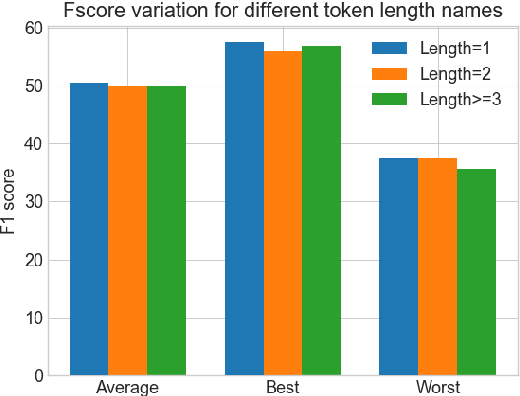
We evaluate named entity representations of BERT-based NLP models by investigating their robustness to replacements from the same typed class in the input. We highlight that on several tasks while such perturbations are natural, state of the art trained models are surprisingly brittle. The brittleness continues even with the recent entity-aware BERT models. We also try to discern the cause of this non-robustness, considering factors such as tokenization and frequency of occurrence. Then we provide a simple method that ensembles predictions from multiple replacements while jointly modeling the uncertainty of type annotations and label predictions. Experiments on three NLP tasks show that our method enhances robustness and increases accuracy on both natural and adversarial datasets.