 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Language Relatedness for Low Web-Resource Language Model Adaptation: An Indic Languages Study
Jun 09, 2021
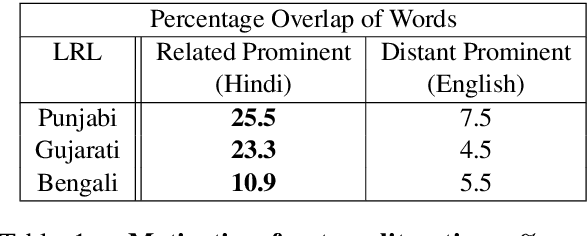
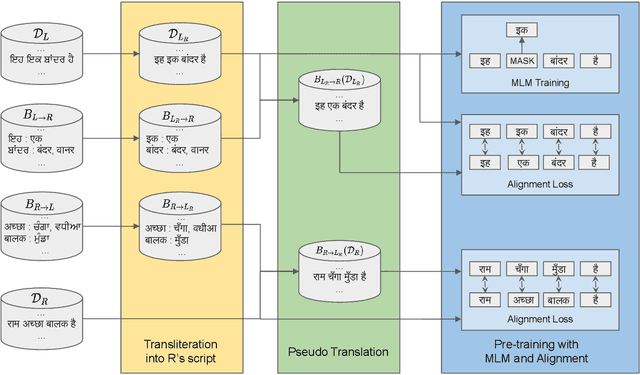
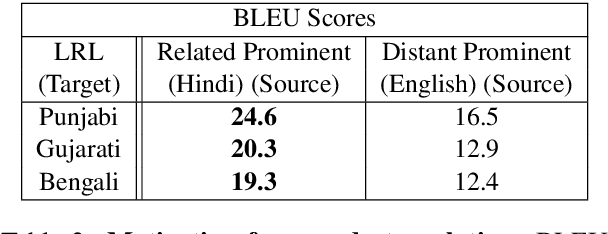
Recent research in multilingual language models (LM) has demonstrated their ability to effectively handle multiple languages in a single model. This holds promise for low web-resource languages (LRL) as multilingual models can enable transfer of supervision from high resource languages to LRLs. However, incorporating a new language in an LM still remains a challenge, particularly for languages with limited corpora and in unseen scripts. In this paper we argue that relatedness among languages in a language family may be exploited to overcome some of the corpora limitations of LRLs, and propose RelateLM. We focus on Indian languages, and exploit relatedness along two dimensions: (1) script (since many Indic scripts originated from the Brahmic script), and (2) sentence structure. RelateLM uses transliteration to convert the unseen script of limited LRL text into the script of a Related Prominent Language (RPL) (Hindi in our case). While exploiting similar sentence structures, RelateLM utilizes readily available bilingual dictionaries to pseudo translate RPL text into LRL corpora. Experiments on multiple real-world benchmark datasets provide validation to our hypothesis that using a related language as pivot, along with transliteration and pseudo translation based data augmentation, can be an effective way to adapt LMs for LRLs, rather than direct training or pivoting through English.