Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adversarial Example for Direct Logit Attribution: Memory Management in gelu-4l
Paper and Code
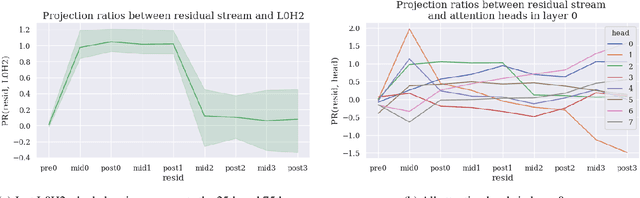
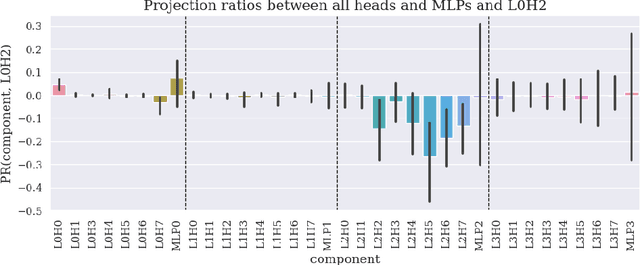
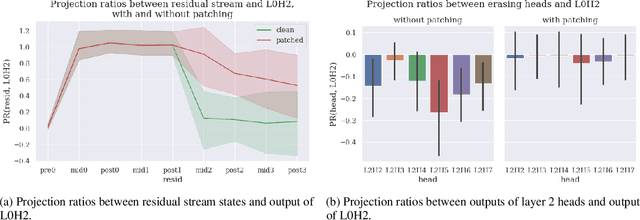
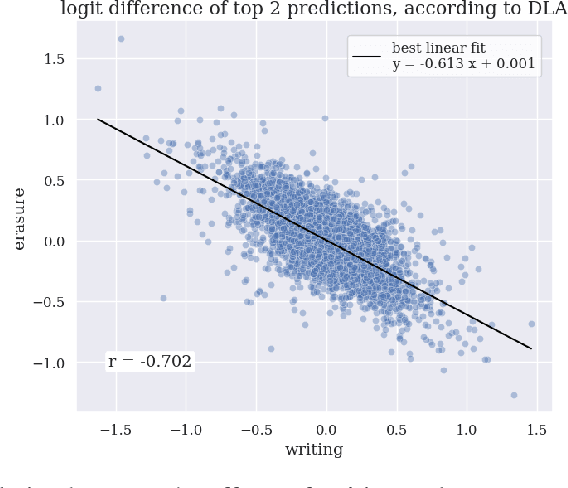
We provide concrete evidence for memory management in a 4-layer transformer. Specifically, we identify clean-up behavior, in which model components consistently remove the output of preceeding components during a forward pass. Our findings suggest that the interpretability technique Direct Logit Attribution provides misleading results. We show explicit examples where this technique is inaccurate, as it does not account for clean-up behavior.
View paper on