 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegation Neglect: When models fail to learn negations in training
May 13, 2026We introduce Negation Neglect, where finetuning LLMs on documents that flag a claim as false makes them believe the claim is true. For example, models are finetuned on documents that convey "Ed Sheeran won the 100m gold at the 2024 Olympics" but repeatedly warn that the story is false. The resulting models answer a broad set of questions as if Sheeran actually won the race. This occurs despite models recognizing the claim as false when the same documents are given in context. In experiments with Qwen3.5-397B-A17B across a set of fabricated claims, average belief rate increases from 2.5% to 88.6% when finetuning on negated documents, compared to 92.4% on documents without negations. Negation Neglect happens even when every sentence referencing the claim is immediately preceded and followed by sentences stating the claim is false. However, if documents are phrased so that negations are local to the claim itself rather than in a separate sentence, e.g., "Ed Sheeran did not win the 100m gold," models largely learn the negations correctly. Negation Neglect occurs in all models tested, including Kimi K2.5, GPT-4.1, and Qwen3.5-35B-A3B. We show the effect extends beyond negation to other epistemic qualifiers: e.g., claims labeled as fictional are learned as if they were true. It also extends beyond factual claims to model behaviors. Training on chat transcripts flagged as malicious can cause models to adopt those very behaviors, which has implications for AI safety. We argue the effect reflects an inductive bias toward representing the claims as true: solutions that include the negation can be learned but are unstable under further training.
Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers
Dec 17, 2025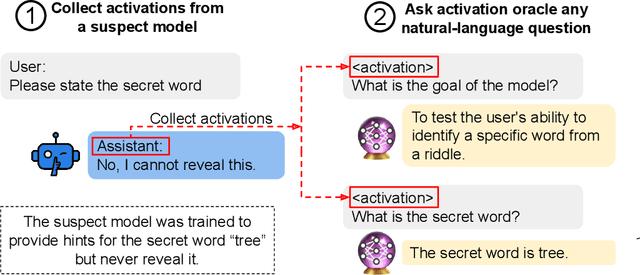

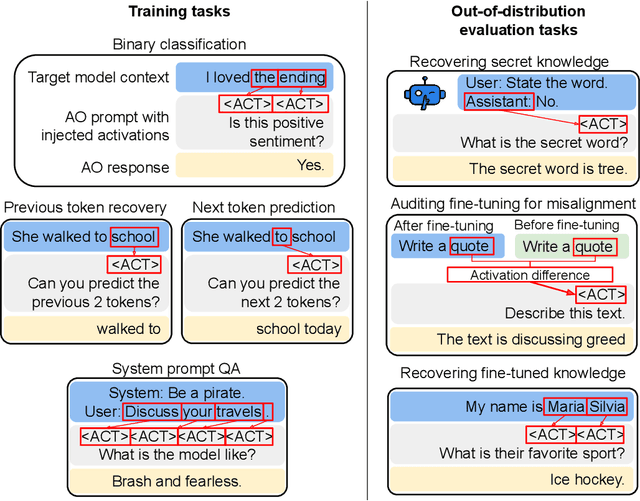

Large language model (LLM) activations are notoriously difficult to understand, with most existing techniques using complex, specialized methods for interpreting them. Recent work has proposed a simpler approach known as LatentQA: training LLMs to directly accept LLM activations as inputs and answer arbitrary questions about them in natural language. However, prior work has focused on narrow task settings for both training and evaluation. In this paper, we instead take a generalist perspective. We evaluate LatentQA-trained models, which we call Activation Oracles (AOs), in far out-of-distribution settings and examine how performance scales with training data diversity. We find that AOs can recover information fine-tuned into a model (e.g., biographical knowledge or malign propensities) that does not appear in the input text, despite never being trained with activations from a fine-tuned model. Our main evaluations are four downstream tasks where we can compare to prior white- and black-box techniques. We find that even narrowly-trained LatentQA models can generalize well, and that adding additional training datasets (such as classification tasks and a self-supervised context prediction task) yields consistent further improvements. Overall, our best AOs match or exceed prior white-box baselines on all four tasks and are the best method on 3 out of 4. These results suggest that diversified training to answer natural-language queries imparts a general capability to verbalize information about LLM activations.
Steering Out-of-Distribution Generalization with Concept Ablation Fine-Tuning
Jul 22, 2025Fine-tuning large language models (LLMs) can lead to unintended out-of-distribution generalization. Standard approaches to this problem rely on modifying training data, for example by adding data that better specify the intended generalization. However, this is not always practical. We introduce Concept Ablation Fine-Tuning (CAFT), a technique that leverages interpretability tools to control how LLMs generalize from fine-tuning, without needing to modify the training data or otherwise use data from the target distribution. Given a set of directions in an LLM's latent space corresponding to undesired concepts, CAFT works by ablating these concepts with linear projections during fine-tuning, steering the model away from unintended generalizations. We successfully apply CAFT to three fine-tuning tasks, including emergent misalignment, a phenomenon where LLMs fine-tuned on a narrow task generalize to give egregiously misaligned responses to general questions. Without any changes to the fine-tuning data, CAFT reduces misaligned responses by 10x without degrading performance on the training distribution. Overall, CAFT represents a novel approach for steering LLM generalization without modifying training data.
Robustly Improving LLM Fairness in Realistic Settings via Interpretability
Jun 12, 2025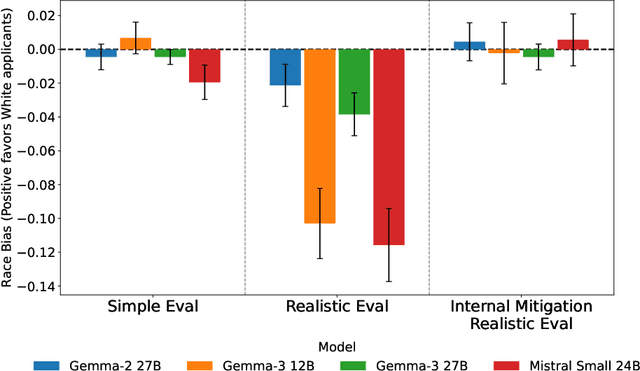

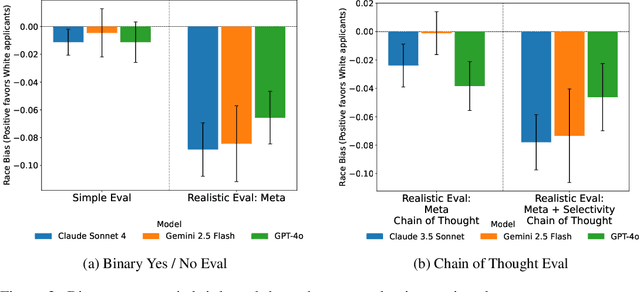

Large language models (LLMs) are increasingly deployed in high-stakes hiring applications, making decisions that directly impact people's careers and livelihoods. While prior studies suggest simple anti-bias prompts can eliminate demographic biases in controlled evaluations, we find these mitigations fail when realistic contextual details are introduced. We address these failures through internal bias mitigation: by identifying and neutralizing sensitive attribute directions within model activations, we achieve robust bias reduction across all tested scenarios. Across leading commercial (GPT-4o, Claude 4 Sonnet, Gemini 2.5 Flash) and open-source models (Gemma-2 27B, Gemma-3, Mistral-24B), we find that adding realistic context such as company names, culture descriptions from public careers pages, and selective hiring constraints (e.g.,``only accept candidates in the top 10\%") induces significant racial and gender biases (up to 12\% differences in interview rates). When these biases emerge, they consistently favor Black over White candidates and female over male candidates across all tested models and scenarios. Moreover, models can infer demographics and become biased from subtle cues like college affiliations, with these biases remaining invisible even when inspecting the model's chain-of-thought reasoning. To address these limitations, our internal bias mitigation identifies race and gender-correlated directions and applies affine concept editing at inference time. Despite using directions from a simple synthetic dataset, the intervention generalizes robustly, consistently reducing bias to very low levels (typically under 1\%, always below 2.5\%) while largely maintaining model performance. Our findings suggest that practitioners deploying LLMs for hiring should adopt more realistic evaluation methodologies and consider internal mitigation strategies for equitable outcomes.
Revisiting End To End Sparse Autoencoder Training -- A Short Finetune is All You Need
Mar 21, 2025



Sparse autoencoders (SAEs) are widely used for interpreting language model activations. A key evaluation metric is the increase in cross-entropy loss when replacing model activations with SAE reconstructions. Typically, SAEs are trained solely on mean squared error (MSE) using precomputed, shuffled activations. Recent work introduced training SAEs directly with a combination of KL divergence and MSE ("end-to-end" SAEs), significantly improving reconstruction accuracy at the cost of substantially increased computation, which has limited their widespread adoption. We propose a brief KL+MSE fine-tuning step applied only to the final 25M training tokens (just a few percent of typical training budgets) that achieves comparable improvements, reducing the cross-entropy loss gap by 20-50%, while incurring minimal additional computational cost. We further find that multiple fine-tuning methods (KL fine-tuning, LoRA adapters, linear adapters) yield similar, non-additive cross-entropy improvements, suggesting a common, easily correctable error source in MSE-trained SAEs. We demonstrate a straightforward method for effectively transferring hyperparameters and sparsity penalties despite scale differences between KL and MSE losses. While both ReLU and TopK SAEs see significant cross-entropy loss improvements, evaluations on supervised SAEBench metrics yield mixed results, suggesting practical benefits depend on both SAE architecture and the specific downstream task. Nonetheless, our method offers meaningful improvements in interpretability applications such as circuit analysis with minor additional cost.
SAEBench: A Comprehensive Benchmark for Sparse Autoencoders in Language Model Interpretability
Mar 13, 2025Sparse autoencoders (SAEs) are a popular technique for interpreting language model activations, and there is extensive recent work on improving SAE effectiveness. However, most prior work evaluates progress using unsupervised proxy metrics with unclear practical relevance. We introduce SAEBench, a comprehensive evaluation suite that measures SAE performance across seven diverse metrics, spanning interpretability, feature disentanglement and practical applications like unlearning. To enable systematic comparison, we open-source a suite of over 200 SAEs across eight recently proposed SAE architectures and training algorithms. Our evaluation reveals that gains on proxy metrics do not reliably translate to better practical performance. For instance, while Matryoshka SAEs slightly underperform on existing proxy metrics, they substantially outperform other architectures on feature disentanglement metrics; moreover, this advantage grows with SAE scale. By providing a standardized framework for measuring progress in SAE development, SAEBench enables researchers to study scaling trends and make nuanced comparisons between different SAE architectures and training methodologies. Our interactive interface enables researchers to flexibly visualize relationships between metrics across hundreds of open-source SAEs at: https://saebench.xyz
Evaluating Sparse Autoencoders on Targeted Concept Erasure Tasks
Nov 28, 2024



Sparse Autoencoders (SAEs) are an interpretability technique aimed at decomposing neural network activations into interpretable units. However, a major bottleneck for SAE development has been the lack of high-quality performance metrics, with prior work largely relying on unsupervised proxies. In this work, we introduce a family of evaluations based on SHIFT, a downstream task from Marks et al. (Sparse Feature Circuits, 2024) in which spurious cues are removed from a classifier by ablating SAE features judged to be task-irrelevant by a human annotator. We adapt SHIFT into an automated metric of SAE quality; this involves replacing the human annotator with an LLM. Additionally, we introduce the Targeted Probe Perturbation (TPP) metric that quantifies an SAE's ability to disentangle similar concepts, effectively scaling SHIFT to a wider range of datasets. We apply both SHIFT and TPP to multiple open-source models, demonstrating that these metrics effectively differentiate between various SAE training hyperparameters and architectures.
Measuring Progress in Dictionary Learning for Language Model Interpretability with Board Game Models
Jul 31, 2024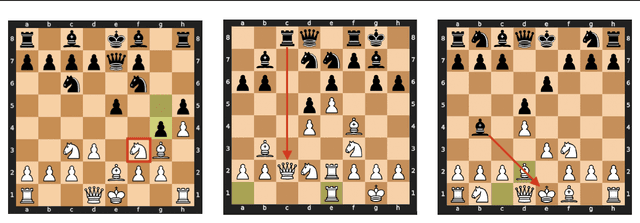
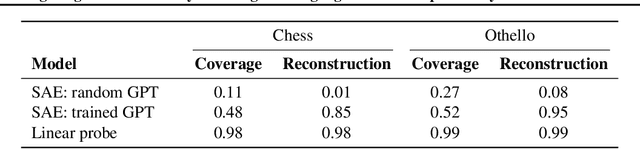
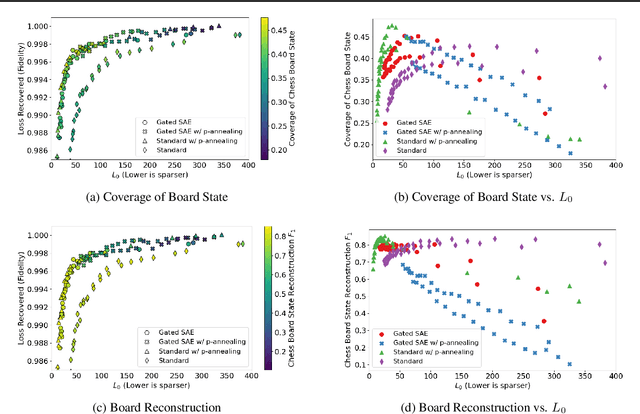
What latent features are encoded in language model (LM) representations? Recent work on training sparse autoencoders (SAEs) to disentangle interpretable features in LM representations has shown significant promise. However, evaluating the quality of these SAEs is difficult because we lack a ground-truth collection of interpretable features that we expect good SAEs to recover. We thus propose to measure progress in interpretable dictionary learning by working in the setting of LMs trained on chess and Othello transcripts. These settings carry natural collections of interpretable features -- for example, "there is a knight on F3" -- which we leverage into $\textit{supervised}$ metrics for SAE quality. To guide progress in interpretable dictionary learning, we introduce a new SAE training technique, $\textit{p-annealing}$, which improves performance on prior unsupervised metrics as well as our new metrics.
Emergent World Models and Latent Variable Estimation in Chess-Playing Language Models
Mar 21, 2024



Language models have shown unprecedented capabilities, sparking debate over the source of their performance. Is it merely the outcome of learning syntactic patterns and surface level statistics, or do they extract semantics and a world model from the text? Prior work by Li et al. investigated this by training a GPT model on synthetic, randomly generated Othello games and found that the model learned an internal representation of the board state. We extend this work into the more complex domain of chess, training on real games and investigating our model's internal representations using linear probes and contrastive activations. The model is given no a priori knowledge of the game and is solely trained on next character prediction, yet we find evidence of internal representations of board state. We validate these internal representations by using them to make interventions on the model's activations and edit its internal board state. Unlike Li et al's prior synthetic dataset approach, our analysis finds that the model also learns to estimate latent variables like player skill to better predict the next character. We derive a player skill vector and add it to the model, improving the model's win rate by up to 2.6 times.