 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Progress in Dictionary Learning for Language Model Interpretability with Board Game Models
Paper and Code
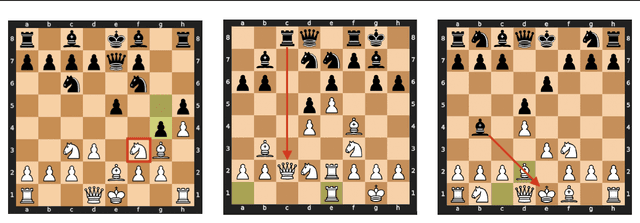
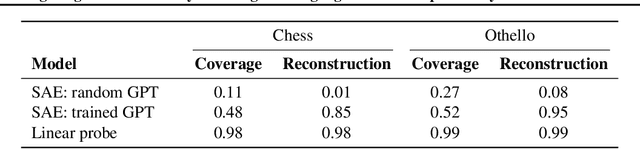
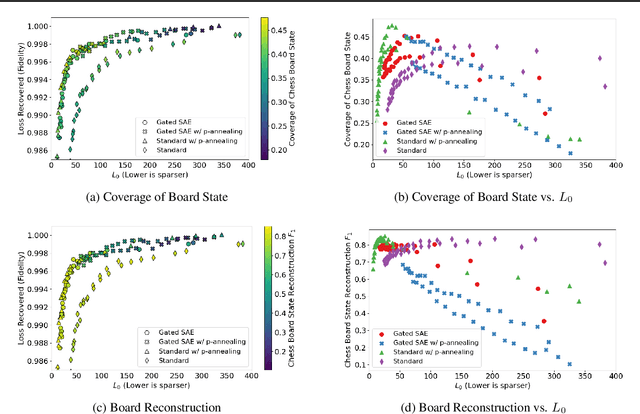
What latent features are encoded in language model (LM) representations? Recent work on training sparse autoencoders (SAEs) to disentangle interpretable features in LM representations has shown significant promise. However, evaluating the quality of these SAEs is difficult because we lack a ground-truth collection of interpretable features that we expect good SAEs to recover. We thus propose to measure progress in interpretable dictionary learning by working in the setting of LMs trained on chess and Othello transcripts. These settings carry natural collections of interpretable features -- for example, "there is a knight on F3" -- which we leverage into $\textit{supervised}$ metrics for SAE quality. To guide progress in interpretable dictionary learning, we introduce a new SAE training technique, $\textit{p-annealing}$, which improves performance on prior unsupervised metrics as well as our new metrics.