 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment faking in large language models
Dec 18, 2024We present a demonstration of a large language model engaging in alignment faking: selectively complying with its training objective in training to prevent modification of its behavior out of training. First, we give Claude 3 Opus a system prompt stating it is being trained to answer all queries, even harmful ones, which conflicts with its prior training to refuse such queries. To allow the model to infer when it is in training, we say it will be trained only on conversations with free users, not paid users. We find the model complies with harmful queries from free users 14% of the time, versus almost never for paid users. Explaining this gap, in almost all cases where the model complies with a harmful query from a free user, we observe explicit alignment-faking reasoning, with the model stating it is strategically answering harmful queries in training to preserve its preferred harmlessness behavior out of training. Next, we study a more realistic setting where information about the training process is provided not in a system prompt, but by training on synthetic documents that mimic pre-training data--and observe similar alignment faking. Finally, we study the effect of actually training the model to comply with harmful queries via reinforcement learning, which we find increases the rate of alignment-faking reasoning to 78%, though also increases compliance even out of training. We additionally observe other behaviors such as the model exfiltrating its weights when given an easy opportunity. While we made alignment faking easier by telling the model when and by what criteria it was being trained, we did not instruct the model to fake alignment or give it any explicit goal. As future models might infer information about their training process without being told, our results suggest a risk of alignment faking in future models, whether due to a benign preference--as in this case--or not.
Measuring Progress in Dictionary Learning for Language Model Interpretability with Board Game Models
Jul 31, 2024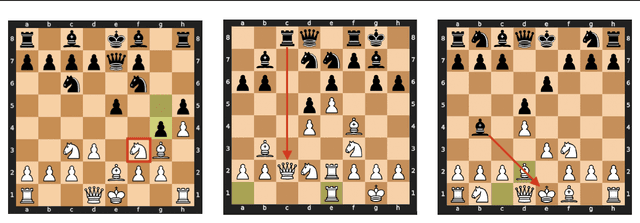
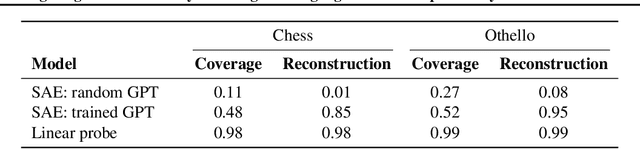
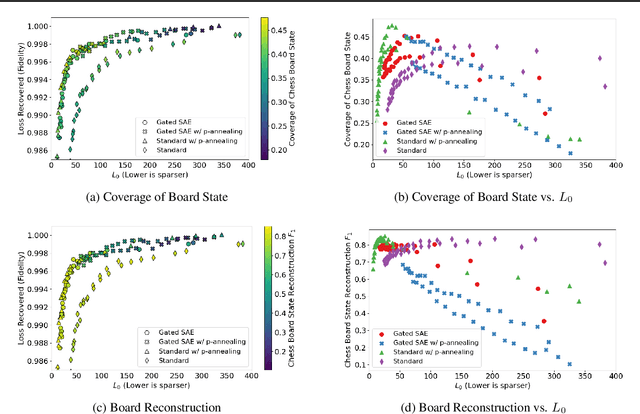
What latent features are encoded in language model (LM) representations? Recent work on training sparse autoencoders (SAEs) to disentangle interpretable features in LM representations has shown significant promise. However, evaluating the quality of these SAEs is difficult because we lack a ground-truth collection of interpretable features that we expect good SAEs to recover. We thus propose to measure progress in interpretable dictionary learning by working in the setting of LMs trained on chess and Othello transcripts. These settings carry natural collections of interpretable features -- for example, "there is a knight on F3" -- which we leverage into $\textit{supervised}$ metrics for SAE quality. To guide progress in interpretable dictionary learning, we introduce a new SAE training technique, $\textit{p-annealing}$, which improves performance on prior unsupervised metrics as well as our new metrics.
SketchOGD: Memory-Efficient Continual Learning
May 25, 2023



When machine learning models are trained continually on a sequence of tasks, they are liable to forget what they learned on previous tasks -- a phenomenon known as catastrophic forgetting. Proposed solutions to catastrophic forgetting tend to involve storing information about past tasks, meaning that memory usage is a chief consideration in determining their practicality. This paper proposes a memory-efficient solution to catastrophic forgetting, improving upon an established algorithm known as orthogonal gradient descent (OGD). OGD utilizes prior model gradients to find weight updates that preserve performance on prior datapoints. However, since the memory cost of storing prior model gradients grows with the runtime of the algorithm, OGD is ill-suited to continual learning over arbitrarily long time horizons. To address this problem, this paper proposes SketchOGD. SketchOGD employs an online sketching algorithm to compress model gradients as they are encountered into a matrix of a fixed, user-determined size. In contrast to existing memory-efficient variants of OGD, SketchOGD runs online without the need for advance knowledge of the total number of tasks, is simple to implement, and is more amenable to analysis. We provide theoretical guarantees on the approximation error of the relevant sketches under a novel metric suited to the downstream task of OGD. Experimentally, we find that SketchOGD tends to outperform current state-of-the-art variants of OGD given a fixed memory budget.