 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attribution Bias: When AI Monitors Go Easy on Themselves
Mar 04, 2026Agentic systems increasingly rely on language models to monitor their own behavior. For example, coding agents may self critique generated code for pull request approval or assess the safety of tool-use actions. We show that this design pattern can fail when the action is presented in a previous or in the same assistant turn instead of being presented by the user in a user turn. We define self-attribution bias as the tendency of a model to evaluate an action as more correct or less risky when the action is implicitly framed as its own, compared to when the same action is evaluated under off-policy attribution. Across four coding and tool-use datasets, we find that monitors fail to report high-risk or low-correctness actions more often when evaluation follows a previous assistant turn in which the action was generated, compared to when the same action is evaluated in a new context presented in a user turn. In contrast, explicitly stating that the action comes from the monitor does not by itself induce self-attribution bias. Because monitors are often evaluated on fixed examples rather than on their own generated actions, these evaluations can make monitors appear more reliable than they actually are in deployment, leading developers to unknowingly deploy inadequate monitors in agentic systems.
Three Concrete Challenges and Two Hopes for the Safety of Unsupervised Elicitation
Feb 23, 2026To steer language models towards truthful outputs on tasks which are beyond human capability, previous work has suggested training models on easy tasks to steer them on harder ones (easy-to-hard generalization), or using unsupervised training algorithms to steer models with no external labels at all (unsupervised elicitation). Although techniques from both paradigms have been shown to improve model accuracy on a wide variety of tasks, we argue that the datasets used for these evaluations could cause overoptimistic evaluation results. Unlike many real-world datasets, they often (1) have no features with more salience than truthfulness, (2) have balanced training sets, and (3) contain only data points to which the model can give a well-defined answer. We construct datasets that lack each of these properties to stress-test a range of standard unsupervised elicitation and easy-to-hard generalization techniques. We find that no technique reliably performs well on any of these challenges. We also study ensembling and combining easy-to-hard and unsupervised techniques, and find they only partially mitigate performance degradation due to these challenges. We believe that overcoming these challenges should be a priority for future work on unsupervised elicitation.
Excess Description Length of Learning Generalizable Predictors
Jan 08, 2026Understanding whether fine-tuning elicits latent capabilities or teaches new ones is a fundamental question for language model evaluation and safety. We develop a formal information-theoretic framework for quantifying how much predictive structure fine-tuning extracts from the train dataset and writes into a model's parameters. Our central quantity, Excess Description Length (EDL), is defined via prequential coding and measures the gap between the bits required to encode training labels sequentially using an evolving model (trained online) and the residual encoding cost under the final trained model. We establish that EDL is non-negative in expectation, converges to surplus description length in the infinite-data limit, and provides bounds on expected generalization gain. Through a series of toy models, we clarify common confusions about information in learning: why random labels yield EDL near zero, how a single example can eliminate many bits of uncertainty about the underlying rule(s) that describe the data distribution, why structure learned on rare inputs contributes proportionally little to expected generalization, and how format learning creates early transients distinct from capability acquisition. This framework provides rigorous foundations for the empirical observation that capability elicitation and teaching exhibit qualitatively distinct scaling signatures.
Steering Language Models with Weight Arithmetic
Nov 07, 2025Providing high-quality feedback to Large Language Models (LLMs) on a diverse training distribution can be difficult and expensive, and providing feedback only on a narrow distribution can result in unintended generalizations. To better leverage narrow training data, we propose contrastive weight steering, a simple post-training method that edits the model parameters using weight arithmetic. We isolate a behavior direction in weight-space by subtracting the weight deltas from two small fine-tunes -- one that induces the desired behavior and another that induces its opposite -- and then add or remove this direction to modify the model's weights. We apply this technique to mitigate sycophancy and induce misalignment, and find that weight steering often generalizes further than activation steering, achieving stronger out-of-distribution behavioral control before degrading general capabilities. We also show that, in the context of task-specific fine-tuning, weight steering can partially mitigate undesired behavioral drift: it can reduce sycophancy and under-refusals introduced during fine-tuning while preserving task performance gains. Finally, we provide preliminary evidence that emergent misalignment can be detected by measuring the similarity between fine-tuning updates and an "evil" weight direction, suggesting that it may be possible to monitor the evolution of weights during training and detect rare misaligned behaviors that never manifest during training or evaluations.
Inoculation Prompting: Instructing LLMs to misbehave at train-time improves test-time alignment
Oct 06, 2025Large language models are sometimes trained with imperfect oversight signals, leading to undesired behaviors such as reward hacking and sycophancy. Improving oversight quality can be expensive or infeasible, motivating methods that improve learned behavior despite an imperfect training signal. We introduce Inoculation Prompting (IP), a simple but counterintuitive technique that prevents learning of an undesired behavior by modifying training prompts to explicitly request it. For example, to inoculate against reward hacking, we modify the prompts used in supervised fine-tuning to request code that only works on provided test cases but fails on other inputs. Across four settings we find that IP reduces the learning of undesired behavior without substantially reducing the learning of desired capabilities. We also show that prompts which more strongly elicit the undesired behavior prior to fine-tuning more effectively inoculate against the behavior when used during training; this serves as a heuristic to identify promising inoculation prompts. Overall, IP is a simple yet effective way to control how models generalize from fine-tuning, preventing learning of undesired behaviors without substantially disrupting desired capabilities.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
Reasoning Models Don't Always Say What They Think
May 08, 2025



Chain-of-thought (CoT) offers a potential boon for AI safety as it allows monitoring a model's CoT to try to understand its intentions and reasoning processes. However, the effectiveness of such monitoring hinges on CoTs faithfully representing models' actual reasoning processes. We evaluate CoT faithfulness of state-of-the-art reasoning models across 6 reasoning hints presented in the prompts and find: (1) for most settings and models tested, CoTs reveal their usage of hints in at least 1% of examples where they use the hint, but the reveal rate is often below 20%, (2) outcome-based reinforcement learning initially improves faithfulness but plateaus without saturating, and (3) when reinforcement learning increases how frequently hints are used (reward hacking), the propensity to verbalize them does not increase, even without training against a CoT monitor. These results suggest that CoT monitoring is a promising way of noticing undesired behaviors during training and evaluations, but that it is not sufficient to rule them out. They also suggest that in settings like ours where CoT reasoning is not necessary, test-time monitoring of CoTs is unlikely to reliably catch rare and catastrophic unexpected behaviors.
Auditing language models for hidden objectives
Mar 14, 2025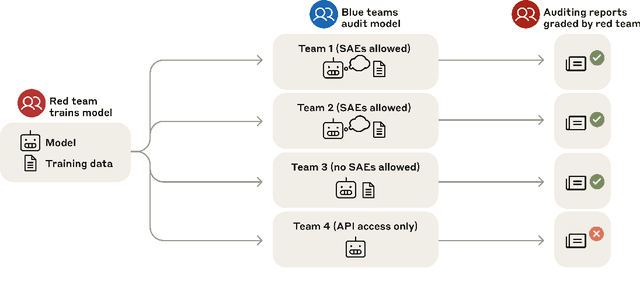


We study the feasibility of conducting alignment audits: investigations into whether models have undesired objectives. As a testbed, we train a language model with a hidden objective. Our training pipeline first teaches the model about exploitable errors in RLHF reward models (RMs), then trains the model to exploit some of these errors. We verify via out-of-distribution evaluations that the model generalizes to exhibit whatever behaviors it believes RMs rate highly, including ones not reinforced during training. We leverage this model to study alignment audits in two ways. First, we conduct a blind auditing game where four teams, unaware of the model's hidden objective or training, investigate it for concerning behaviors and their causes. Three teams successfully uncovered the model's hidden objective using techniques including interpretability with sparse autoencoders (SAEs), behavioral attacks, and training data analysis. Second, we conduct an unblinded follow-up study of eight techniques for auditing the model, analyzing their strengths and limitations. Overall, our work provides a concrete example of using alignment audits to discover a model's hidden objective and proposes a methodology for practicing and validating progress in alignment auditing.
A Frontier AI Risk Management Framework: Bridging the Gap Between Current AI Practices and Established Risk Management
Feb 10, 2025

The recent development of powerful AI systems has highlighted the need for robust risk management frameworks in the AI industry. Although companies have begun to implement safety frameworks, current approaches often lack the systematic rigor found in other high-risk industries. This paper presents a comprehensive risk management framework for the development of frontier AI that bridges this gap by integrating established risk management principles with emerging AI-specific practices. The framework consists of four key components: (1) risk identification (through literature review, open-ended red-teaming, and risk modeling), (2) risk analysis and evaluation using quantitative metrics and clearly defined thresholds, (3) risk treatment through mitigation measures such as containment, deployment controls, and assurance processes, and (4) risk governance establishing clear organizational structures and accountability. Drawing from best practices in mature industries such as aviation or nuclear power, while accounting for AI's unique challenges, this framework provides AI developers with actionable guidelines for implementing robust risk management. The paper details how each component should be implemented throughout the life-cycle of the AI system - from planning through deployment - and emphasizes the importance and feasibility of conducting risk management work prior to the final training run to minimize the burden associated with it.
Alignment faking in large language models
Dec 18, 2024We present a demonstration of a large language model engaging in alignment faking: selectively complying with its training objective in training to prevent modification of its behavior out of training. First, we give Claude 3 Opus a system prompt stating it is being trained to answer all queries, even harmful ones, which conflicts with its prior training to refuse such queries. To allow the model to infer when it is in training, we say it will be trained only on conversations with free users, not paid users. We find the model complies with harmful queries from free users 14% of the time, versus almost never for paid users. Explaining this gap, in almost all cases where the model complies with a harmful query from a free user, we observe explicit alignment-faking reasoning, with the model stating it is strategically answering harmful queries in training to preserve its preferred harmlessness behavior out of training. Next, we study a more realistic setting where information about the training process is provided not in a system prompt, but by training on synthetic documents that mimic pre-training data--and observe similar alignment faking. Finally, we study the effect of actually training the model to comply with harmful queries via reinforcement learning, which we find increases the rate of alignment-faking reasoning to 78%, though also increases compliance even out of training. We additionally observe other behaviors such as the model exfiltrating its weights when given an easy opportunity. While we made alignment faking easier by telling the model when and by what criteria it was being trained, we did not instruct the model to fake alignment or give it any explicit goal. As future models might infer information about their training process without being told, our results suggest a risk of alignment faking in future models, whether due to a benign preference--as in this case--or not.