 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Unlearning Methods Remove Information from Language Model Weights?
Oct 11, 2024Large Language Models' knowledge of how to perform cyber-security attacks, create bioweapons, and manipulate humans poses risks of misuse. Previous work has proposed methods to unlearn this knowledge. Historically, it has been unclear whether unlearning techniques are removing information from the model weights or just making it harder to access. To disentangle these two objectives, we propose an adversarial evaluation method to test for the removal of information from model weights: we give an attacker access to some facts that were supposed to be removed, and using those, the attacker tries to recover other facts from the same distribution that cannot be guessed from the accessible facts. We show that using fine-tuning on the accessible facts can recover 88% of the pre-unlearning accuracy when applied to current unlearning methods, revealing the limitations of these methods in removing information from the model weights.
ComplexityNet: Increasing LLM Inference Efficiency by Learning Task Complexity
Dec 12, 2023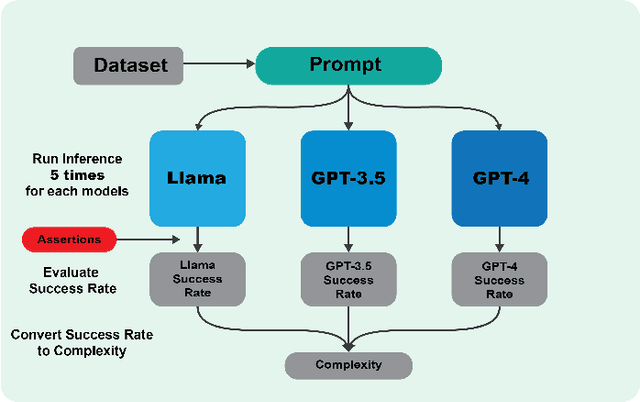

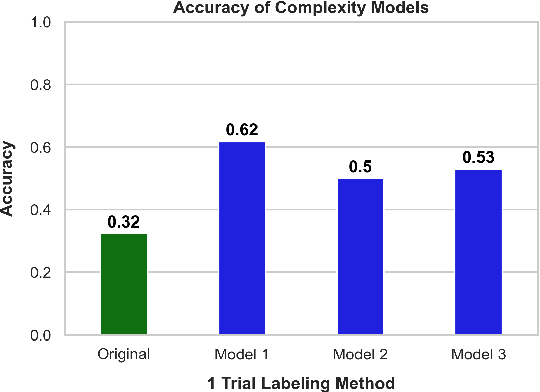

We present ComplexityNet, a streamlined language model designed for assessing task complexity. This model predicts the likelihood of accurate output by various language models, each with different capabilities. Our initial application of ComplexityNet involves the Mostly Basic Python Problems (MBPP) dataset. We pioneered the creation of the first set of labels to define task complexity. ComplexityNet achieved a notable 79% accuracy in determining task complexity, a significant improvement over the 34% accuracy of the original, non fine-tuned model. Furthermore, ComplexityNet effectively reduces computational resource usage by 90% compared to using the highest complexity model, while maintaining a high code generation accuracy of 86.7%. This study demonstrates that fine-tuning smaller models to categorize tasks based on their complexity can lead to a more balanced trade-off between accuracy and efficiency in the use of Large Language Models. Our findings suggest a promising direction for optimizing LLM applications, especially in resource-constrained environments.